
程序员必看!企业大模型落地架构DeepResearch:从技术到业务的完整解决方案(值得收藏)
DeepResearch是阿里通义推出的企业级AI架构,采用"多智能体协作+全流程工具链+动态知识库"三层设计,解决企业大模型落地的四大痛点。该架构通过任务规划、执行和知识工具三层,实现从"线性执行"到"迭代优化"、“单一模型"到"垂直融合”、"技术驱动"到"业务友好"的转变。企业可按照"预热-启动-优化-规模化"四阶段落地路径,让AI从对话助手进化为业务伙伴,切实解决合同审核、报告生成等核心场景问题。
当 AI 大模型的 “炫技式应用” 逐渐褪去热度,企业真正关心的问题浮出水面:如何让 AI 从 “对话助手” 进化为 “业务伙伴”,切实解决合同审核、报告生成、知识管理等核心场景的痛点?阿里通义 DeepResearch 及其生态解决方案(给出了答案:一套围绕 “业务价值闭环” 构建的企业级 AI 架构,让大模型从 “实验室” 走进 “生产线”。

一、企业大模型落地的 “四座大山”:架构设计的起点
在聊 DeepResearch 的架构之前,必须先直面企业落地的真实困境。文档数据显示,超过 80% 的企业大模型项目卡在 “技术 - 业务衔接层”,核心痛点集中在四点:

1. 业务与技术的 “两层皮”
科技部门主导开发,业务人员难以参与:IT 团队搭建的大模型平台侧重 “模型精度”,却解决不了销售团队 “客户画像生成”、法务团队 “合同条款比对” 等具体需求。某金融企业案例显示,其初始大模型能实现 90% 的文档摘要准确率,却因不懂 “信贷审批术语”,导致实际业务使用率不足 15%。
2. 长尾需求的 “覆盖盲区”
传统 IT 系统难以应对零散、轻量的业务需求:例如:“每周生成部门经营简报”“实时对比新旧制度差异”“快速提取客户投诉风险点” 等,这些需求往往金额小、频次高,却占据业务人员 40% 以上的工作时间。
3. 工具与安全的 “双重枷锁”
-
工具生态弱
企业内部系统(ERP、CRM、OA)接口不统一,大模型难以调用数据;外部工具(文档解析、图表生成)缺乏标准化适配,导致 “AI 能生成报告,却调不出最新销售数据”。
-
安全成本高
金融、能源等行业对数据合规要求严格,大模型 “联网检索”“数据缓存” 等能力受限,既要保证 “数据不泄露”,又要确保 “信息够新鲜”。
4. 效果与成本的 “平衡难题”
企业需要的是 “80% 场景达到 90% 精度”,而非 “10% 场景追求 99% 完美”。但传统大模型架构要么 “精度不足”(通用大模型不懂垂直业务),要么 “成本过高”(定制化开发需百万级投入),难以找到平衡点。
二、DeepResearch 架构核心:以 “研究型 AI 智能体” 打通业务全流程
DeepResearch 之所以能破局,关键在于跳出 “单一模型” 思维,构建了一套 “多智能体协作 + 全流程工具链 + 动态知识库” 的三层架构,复刻人类专家 “拆解问题 - 执行任务 - 优化结果” 的工作逻辑。

1. 第一层:任务规划层(Planning Agent)-- AI 界的 “项目经理”
作为架构的 “大脑”,Planning Agent 负责将模糊的业务需求转化为可执行的步骤,核心能力包括:
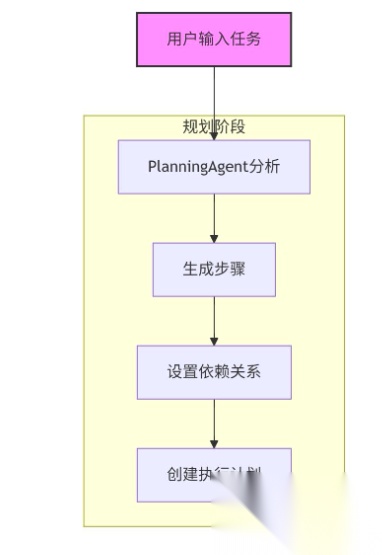
-
需求拆解
将 “生成银行信贷尽调报告” 拆分为 “提取企业财务数据 → 分析偿债能力 → 识别风险点 → 撰写报告” 等子任务,并设置依赖关系(例如:“先有财务数据,再做偿债分析”)。
-
工具匹配
根据子任务类型自动选择工具,例如:“数据提取” 调用 “PDF 解析工具”,“风险识别” 调用 “行业知识库”,“报告撰写” 调用 “垂直领域大模型”。
-
动态调整
实时监控子任务执行状态,若某一步失败(例如:“财务数据无法提取”),自动切换方案(如 “从企业年报中手动抓取数据”)。
案例:在 “投标文件生成” 场景中,Planning Agent 先分析《招标要求.xlsx》,拆解出 “技术方案响应”“服务能力说明”“项目进度规划” 等 12 个子任务,再为每个子任务分配对应的执行 AI 智能体,确保输出符合招标方的评分标准。
2. 第二层:任务执行层(Execution Agent)-- 专业化 “执行团队”
执行层由多个细分智能体组成,各司其职且协同工作,避免 “通用模型什么都做,什么都不精” 的问题:
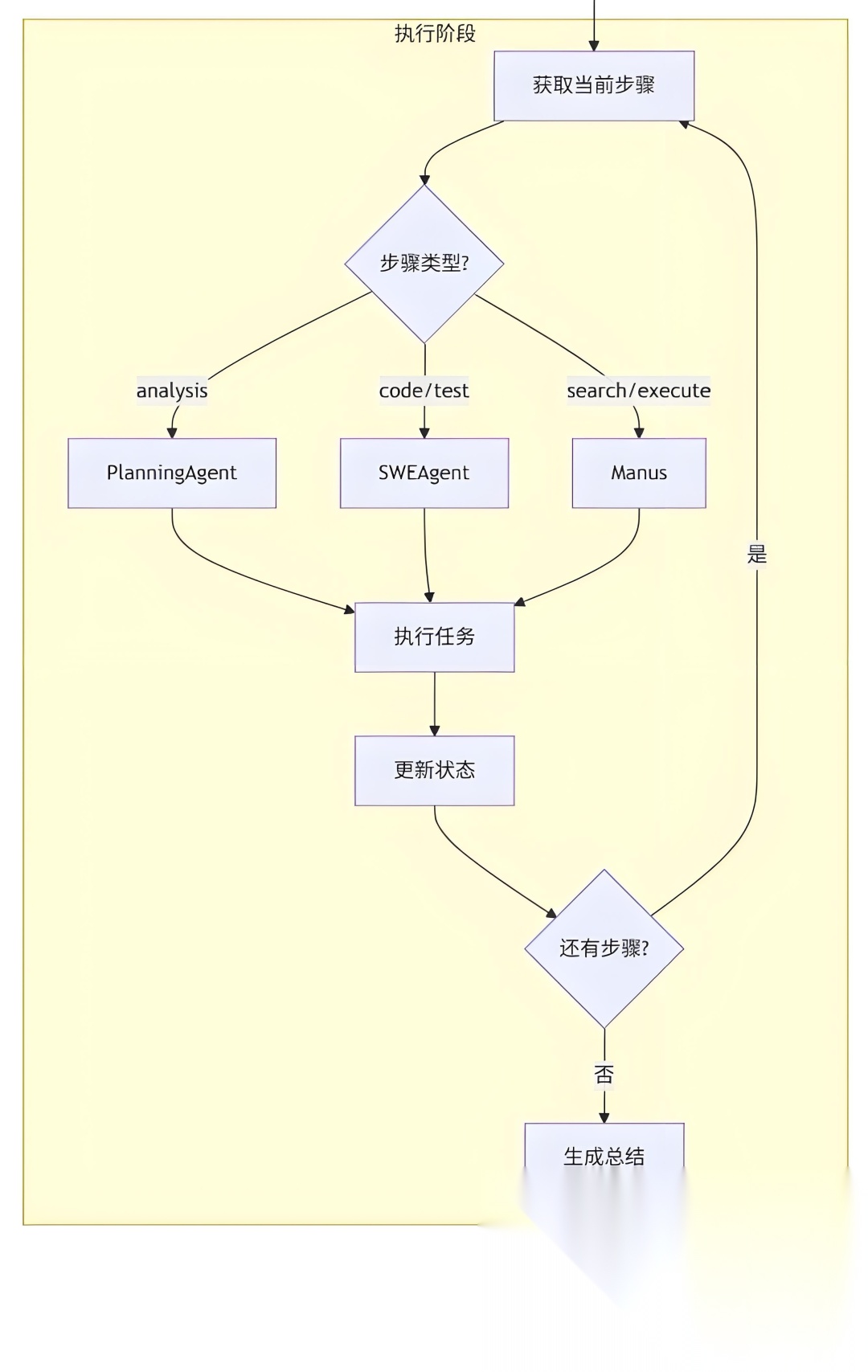
-
Research Agent
负责信息检索与分析,例如:“从第三方网站提取行业政策”“对比竞品投标方案”,支持联网搜索、文档解析、数据库查询(NL2SQL)。
-
Coder Agent
处理数据计算与自动化任务,例如:“用 Python 分析企业近 3 年营收趋势”“生成可视化图表”,甚至能编写简单的系统接口代码。
-
Writer Agent
专注于垂直领域文档生成,基于 “行业模板库 + 动态知识库”,生成符合格式要求的报告(例如:券商研报需 “摘要 - 核心观点 - 数据支撑” 结构,合同审核需 “条款比对 - 风险标注 - 修改建议” 模块)。
-
Review Agent
担任 “质量检查员”,对照业务标准(例如:“银行合规条款”“投标评分细则”)校验结果,例如:发现 “合同未填写签署日期”“报告遗漏风险提示” 时,自动退回并提示修改。
3. 第三层:知识与工具层(Knowledge & Tool Layer)-- 架构的 “基础设施”
这一层是执行层的 “弹药库”,确保 AI 智能体 “有数据可用、有工具可调用”:
-
动态知识库
分为 “通用知识库”(企业制度、行业标准)和 “场景知识库”(例如:信贷审核中的 “偿债能力指标”、投标中的 “技术评分标准”),支持文档上传、自动拆分、权限管控(细到 “某部门只能查看本业务线知识”)。
-
标准化工具链
封装 50+ 企业常用工具,涵盖 “文档处理”(PDF/Word 解析、格式转换)、“数据处理”(Excel 分析、SQL 查询)、“业务系统对接”(ERP/CRM 接口),且支持 MCP 协议,可快速接入企业自有工具。
-
记忆模块
记录任务执行轨迹(例如:“某报告修改了 3 次,原因是风险点识别不全”),形成 “经验库”,供后续类似任务参考,实现 “越用越聪明”。
三、架构差异化优势:比 “通用 Agent” 更懂企业业务
相比 AutoGPT、XAgent 等通用 AI 智能体框架,DeepResearch 针对企业场景做了三大关键优化:
1. 从 “线性执行” 到 “迭代优化”
传统 Agent 按 “规划 → 执行” 线性推进,一旦中间步骤出错就会卡顿;而 DeepResearch 引入 “IterResearch 循环”:每个子任务完成后,Review Agent 先校验结果,若不符合要求(例如:“报告未覆盖招标方的技术指标”),立即反馈给 Planning Agent 调整方案,形成 “执行 - 校验 - 优化” 的闭环。
2. 从 “单一模型” 到 “垂直融合”
不依赖通用大模型 “硬扛” 所有任务,而是将 “通用模型(比如:Qwen2.5)+ 垂直模型(例如:金融合规模型、法律条款模型)” 结合:
- 通用模型负责 “自然语言理解”“任务调度” 等基础工作;
- 垂直模型负责 “专业领域判断”,例如 “合同审核” 调用 “法律条款识别模型”,准确率比通用模型提升 30% 以上。
3. 从 “技术驱动” 到 “业务友好”
架构设计时就植入 “业务人员可参与” 的基因:
- 提供 “可视化流程编排” 界面,业务人员无需写代码,只需拖拽 “子任务”“工具”“知识库” 等模块,即可搭建自己的业务流程(例如:销售团队自定义 “客户跟进报告生成” 流程);
- 支持 “Human-in-the-loop”(人在回路中),业务人员可在关键节点介入(例如:“审核报告初稿”“补充业务规则”),既保证 AI 输出的准确性,又避免 “黑箱操作”。
四、企业落地路径:“四阶段方法论”
光有架构不够,还需要配套的落地策略。作为 DeepResearch 的企业级解决方案,提出了 “预热 - 启动 - 优化 - 规模化” 四阶段落地法,降低企业试错成本:

| 阶段 | 关键目标 | 典型场景 | 实现方式 |
|---|---|---|---|
| 预热阶段 | 建立认知,让业务人员 “敢用” | 个人知识库问答、通用文档摘要 | 0 成本启动,用开源版本搭建轻量化 Demo,通过公开课、社群培训普及用法 |
| 启动阶段 | 验证价值,打造 “标杆案例” | 部门级合同审核、客服问答助手 | 部署开源版本 + 少量定制开发,优先解决 “高重复、高成本” 任务(如客服团队 “规范制度问答”) |
| 优化阶段 | 沉淀数据,提升 AI 效果 | 企业级报告生成、跨部门知识管理 | 积累业务数据(如 “优质报告案例”“常见错误类型”),微调垂直模型,优化工具链适配 |
| 规模化阶段 | 全公司赋能,融入业务系统 | 财务自动做账、供应链风险预警 | 平台化部署,与 ERP、OA 等系统集成,支持业务人员自主创建 AI 流程 |
案例:某能源企业落地时,先从 “合同审核” 场景切入(预热阶段),用开源版本实现 “化工产品购销合同的资质校验”,将人工审核时间从 2 小时 / 份缩短至 10 分钟 / 份;半年后(优化阶段),基于积累的 500+ 合同数据微调模型,风险识别准确率从 82% 提升至 95%;最终(规模化阶段),将 AI 能力集成到供应链系统,实现 “合同审核 - 订单生成 - 物流跟踪” 全流程自动化。
五、未来展望:从 “辅助工具” 到 “业务伙伴”
DeepResearch 架构的终极目标,是让 AI 从 “被动执行任务” 进化为 “主动创造价值”。两大发展方向:
-
更深度的多模态能力
未来将融入 “图像识别”(例如:解析工程图纸、产品质检报告)、“语音交互”(例如:会议纪要自动生成),覆盖更多企业场景;
-
更开放的生态
允许企业基于自身业务定制 AI 智能体(例如:“电力行业故障分析 Agent”“医疗行业病例解读 Agent”),形成 “共建共享” 的生态。
对于企业而言,AI 大模型落地的关键从来不是 “技术多先进”,而是 “架构是否贴合业务”。DeepResearch 给出的启示是:与其追求 “万能模型”,不如构建一套 “能拆解业务、能调用工具、能持续优化” 的 AI 智能体系统。毕竟,企业需要的不是 “会写诗的 AI”,而是 “能搞定报表、合同、报告的靠谱伙伴”。
为什么要学习大模型?
在科技飞速发展的当下,大模型已成为推动AI变革的核心引擎。2025年,大模型应用已经深入各行各业,从日常办公使用的DeepSeek、豆包、千问,到下游应用的自动驾驶/具身智能VLA,再到AIGC生成。大模型产业正经历技术普惠化、应用垂直化、生态开源化的深度变革,学习大模型成为把握人工智能革命主动权的关键。
数据显示,2023 年我国大模型相关人才缺口已突破百万,这一数字直接暴露了人才培养体系的严重滞后与供给不足。而随着人工智能技术的飞速迭代,产业对专业人才的需求将呈爆发式增长,据预测,到 2025 年这一缺口将急剧扩大至 400 万!!

普通人如何学习大模型
最近收到不少留言:
- 我是做后端开发的,能转大模型方向吗?
- 看了很多教程,怎么判断哪些内容是真正有用的?
- 自己尝试动手搭模型,结果踩了不少坑,是不是说明我不适合这个方向?
其实这些问题,我几年前也都经历过。
那时我还是一名传统后端工程师,对大模型一知半解。刚开始接触时也很迷茫,常常不知道从哪里下手、该学哪些内容才算“有用”,搭建模型时也是各种踩坑、反复重来。
但正是一步步摸索、不断试错,我才走到了今天,从0起步,成功转型为大模型开发者。
所以我想跟你说:问题不在你,而是在学习方法。
今天我就以“过来人”的身份,分享一份亲测有效的大模型学习资源。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
现在这份资料免费分享给大家,有需要的小伙伴,直接VX扫描下方二维码就能领取啦😝↓↓↓
01. 大模型学习路线汇总
整体的学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战,跟着学习路线一步步打卡,小白也能轻松学会!
02. 大模型实战项目&配套源码
光学理论可不够,这套学习资料还包含了丰富的实战案例,让你在实战中检验成果巩固所学知识
03. 大模型学习必看书籍PDF
我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
04. 大模型超全面试题汇总
在面试过程中可能遇到的问题,我都给大家汇总好了,能让你们在面试中游刃有余
这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
👉获取方式:
😝有需要的小伙伴,可以保存图片到VX扫描下方二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最适合零基础的!!
更多推荐


 22
22 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)