
anthropic博客翻译01:Building effective agents
文章目录
本文翻译自anthropic公司2024年12月19号的一篇博客:https://www.anthropic.com/engineering/building-effective-agents
前言
在与众多致力于LLM智能体开发的团队合作过程中我们发现,一个现象始终贯穿不同行业:真正取得显著成效的,往往都是那些采用简洁、可组合模式的实施方案,而非复杂繁琐的框架体系。
正文
过去一年间,我们与来自不同行业的数十个大型语言模型智能体开发团队展开合作。纵观这些案例,我们发现一个始终如一的规律:最成功的实施方案并非依赖复杂框架或专业库,而是采用简洁、可组合的构建模式。本文将结合我们与客户合作及自主开发智能体的实践经验,为开发者提供构建高效智能体的实用建议。
What are agents?
“Agent” 的定义存在多种解读。有些客户将其定义为完全自主的系统,能够长期独立运行,并运用多种工具完成复杂任务;另一些客户则用这个术语指代遵循预设流程的规范性实施方案。在Anthropic,我们将所有这些变体统称为 “agentic systems” ,但在架构层面区分了workflows and agents两大类型:
- workflows通过预设代码路径来协调大语言模型与工具的使用,
- 而agents则让大语言模型动态自主地掌控执行流程与工具调用,始终保持对任务实施方式的决策权。
下文将深入探讨这两类智能系统。在附录一(“Agents in Practice”)中,我们将详细介绍客户在两大特定领域应用此类系统取得的显著成效。
When (and when not) to use agents
在开发大语言模型应用时,我们建议尽可能寻求最简解决方案,仅在必要时增加复杂度。有些场景甚至完全无需构建智能系统。智能系统(Agentic systems)往往以牺牲响应速度和提高成本为代价来换取更好的任务表现,开发者需要审慎评估这种权衡是否合理。
当确实需要更复杂方案时,工作流系统能为明确定义的任务提供可预测性与稳定性,而智能系统则更适合需要灵活性和模型自主决策的大规模场景。但就大多数应用而言,通过检索增强(retrieval)与上下文示例( in-context examples )来优化单次大语言模型调用,通常已经足够满足需求。
When and how to use frameworks
目前已有诸多框架能够简化智能系统的实现流程,主要包括:
- LangChain推出的LangGraph;
- Amazon Bedrock的AI智能体框架;
- 可视化拖拽式LLM工作流构建工具Rivet;
- 以及另一款用于构建测试复杂工作流的GUI工具Vellum。
这些框架通过封装大语言模型调用、工具定义与解析、调用链组装等底层标准任务,显著降低了开发门槛。但值得注意的是,它们往往构建了多重抽象层,可能遮蔽核心提示词与响应的可见性,增加调试难度。此外,当简单架构已能满足需求时,这些框架易诱使开发者过度设计。
我们建议开发者从直接调用LLM API入手:许多功能模式仅需数行代码即可实现。若确需采用框架,务必深入理解其底层逻辑——对框架内部机制的误判,正是客户实践中常见的问题根源。
欢迎参阅我们的开发指南(cookbook)获取示例实现方案。
Building blocks, workflows, and agents
在本节中,我们将深入探讨实际生产环境中agentic systems的常见模式。从最基础的增强型大语言模型构建模块出发,我们将循序渐进地增加系统复杂度——从简单的组合式工作流,直至完全自主的智能体系统。
Building block: The augmented LLM
智能系统的基础构建单元,正是配备了检索、工具调用与记忆机制(retrieval, tools, and memory)等增强功能的大语言模型。当前的LLM模型已能主动运用这些能力——自主生成搜索指令、选择适用工具,并判断需要留存的关键信息。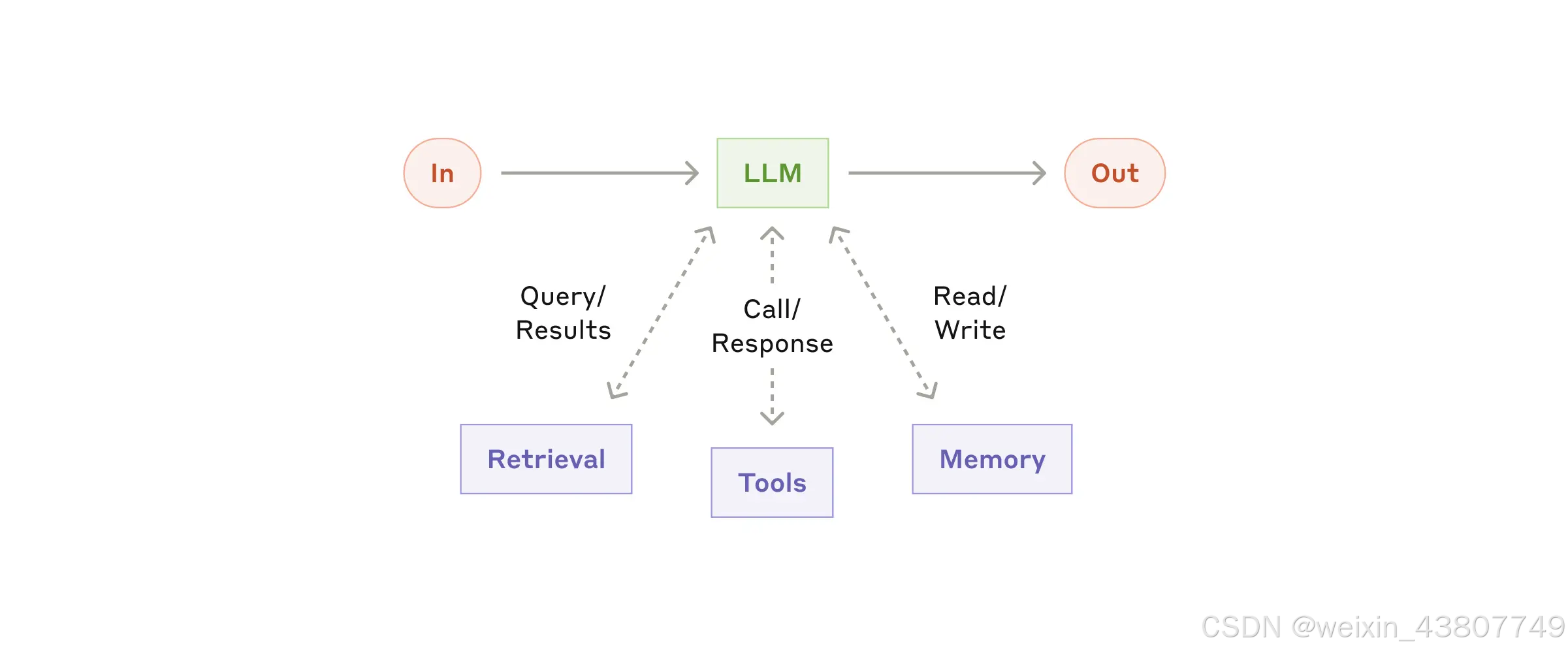
我们建议重点关注两个核心维度:一是使这些增强功能精准契合具体业务场景,二是确保它们能为大语言模型提供简洁易用、文档完善的交互接口。尽管实现这些增强功能存在多种技术路径,其中一种方案是通过我们近期发布的模型上下文协议(Model Context Protocol)——该协议允许开发者通过简易的客户端实现,快速接入日益丰富的第三方工具生态。
在本文后续讨论中,我们将默认每次大语言模型调用都具备这些增强能力的支持。
Workflow: Prompt chaining
提示链(Prompt chaining)将一项任务分解为一系列步骤,其中每次大语言模型(LLM)调用都会处理前一步的输出。你可以在任意中间步骤添加程序化检查(参见下图中的“门控”/“gate”),以确保整个流程仍在正确轨道上。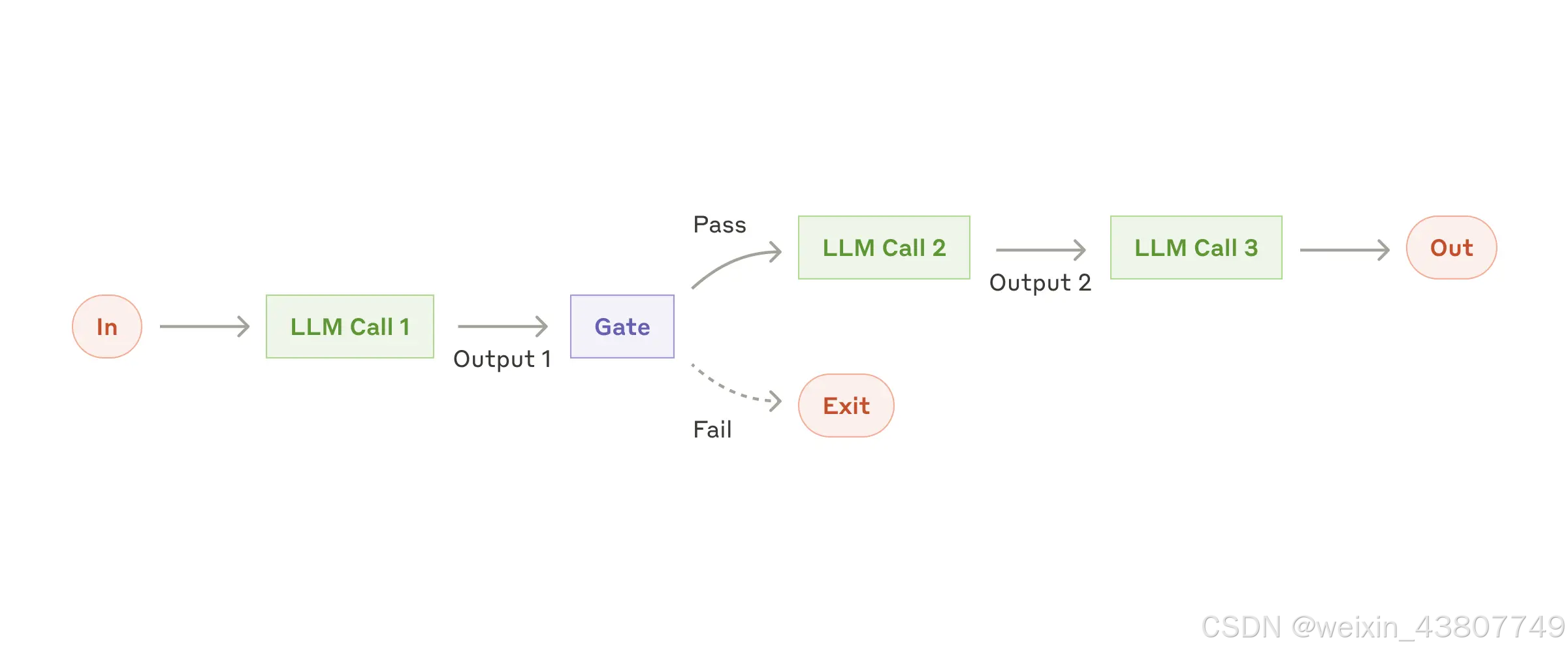
何时使用此工作流:
当任务能够轻松且清晰地分解为固定的子任务时,该工作流尤为适用。其主要目标是通过将每次大语言模型(LLM)调用简化为更简单的任务,以牺牲一定的延迟为代价,换取更高的准确性。
提示链(Prompt chaining)适用的示例包括:
- 生成营销文案,再将其翻译成另一种语言。
- 先撰写一份文档的大纲,检查该大纲是否符合特定标准,然后基于审核通过的大纲撰写完整文档。
Workflow: Routing
路由(Routing)会对输入进行分类,并将其引导至专门的后续任务。这种工作流有助于实现关注点分离,并构建更加专用的提示(prompts)。如果没有这种工作流,针对某类输入进行优化可能会损害模型在其他类型输入上的表现。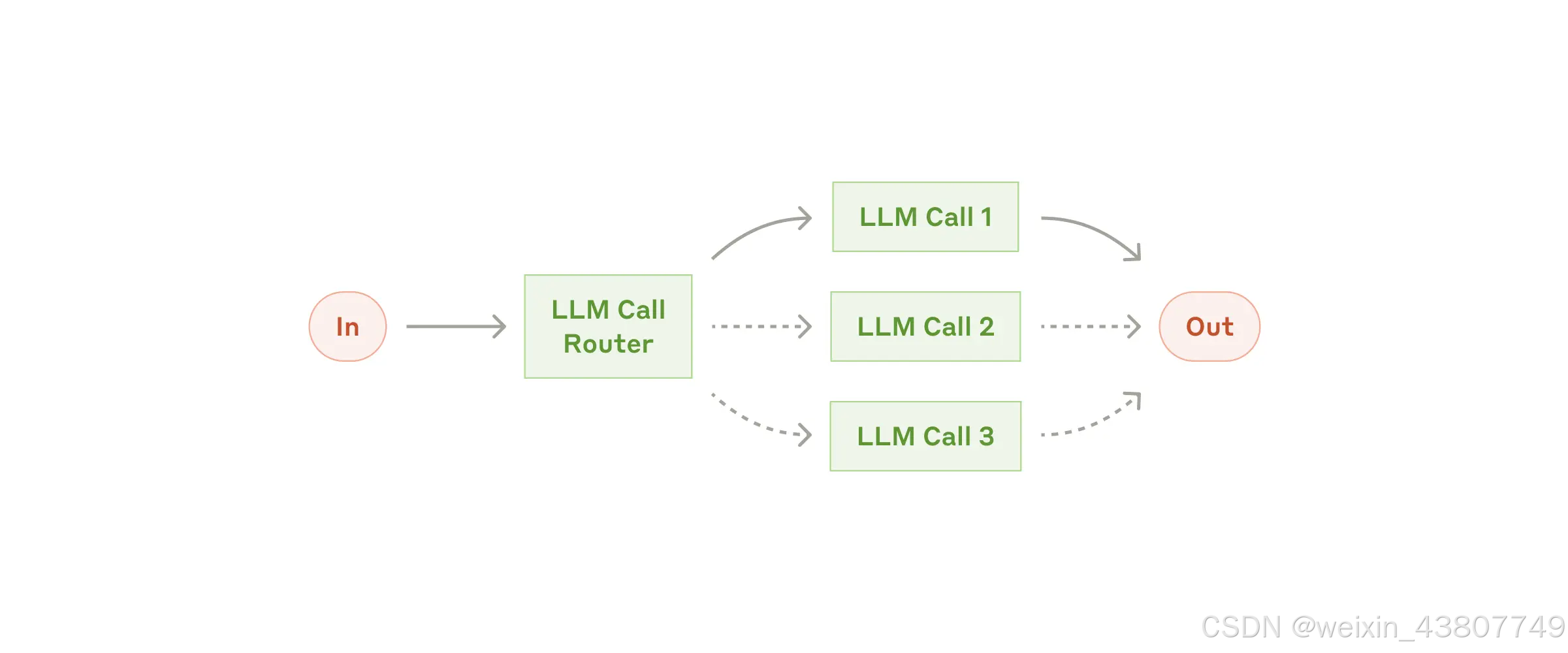
何时使用此工作流:
当任务较为复杂,且存在明显不同的类别、各自更适合单独处理时,路由(Routing)非常有效。同时,前提是这些类别的分类可以被准确完成——无论是通过大语言模型(LLM),还是通过更传统的分类模型或算法。
路由适用的示例包括:
- 将不同类型的客户服务咨询(如一般性问题、退款请求、技术支持)分别引导至不同的下游流程、专用提示(prompts)和工具。
- 将简单或常见问题路由至轻量级模型(如 Claude 3.5 Haiku),而将复杂或罕见问题路由至能力更强的模型(如 Claude 3.5 Sonnet),以优化成本与响应速度。
Workflow: Parallelization
大语言模型(LLMs)有时可以同时处理同一任务,并通过程序化方式聚合它们的输出。这种工作流称为并行化(Parallelization),主要有以下两种形式:
- 分段(Sectioning):将一个任务拆分为多个相互独立的子任务,并行执行。
- 投票(Voting):多次运行相同的任务,以获得多样化的输出,再通过聚合(如多数投票、加权平均等)得出最终结果。
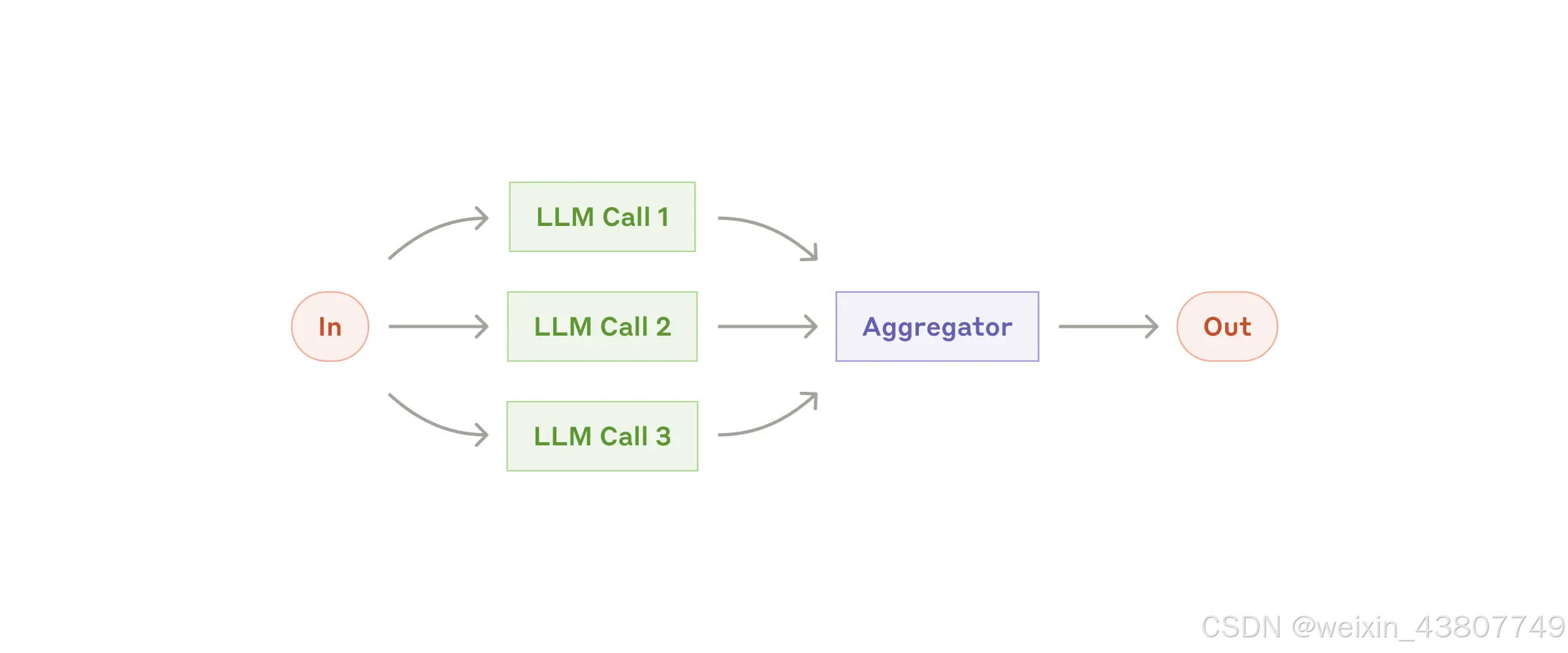
何时使用此工作流:
当任务可以被拆分为可并行执行的子任务以提升速度,或当需要多个视角/多次尝试以获得更高置信度的结果时,并行化(Parallelization)非常有效。对于涉及多方面考量的复杂任务,大语言模型(LLMs)通常表现更佳——前提是每个考量点都由单独的 LLM 调用处理,从而让模型能专注于特定方面。
并行化适用的示例:
分段(Sectioning):
- 实施安全护栏(guardrails):一个模型实例处理用户查询,另一个并行实例负责筛查内容是否包含不当言论或违规请求。这种方式通常优于让单次 LLM 调用同时兼顾核心响应和安全审查。
- 自动化评估(Automating evals):在评估 LLM 性能时,每次 LLM 调用专注于评估模型在某一特定维度(如事实准确性、语言流畅性、安全性等)上的表现。
投票(Voting):
- 代码漏洞审查:使用多个不同的提示(prompts)并行审查同一段代码,只要任一提示发现潜在问题即予以标记。
- 内容适当性判断:多个提示从不同角度评估一段内容是否不当(例如语言冒犯性、隐私泄露风险等),并通过设定不同的投票阈值来平衡误报(false positives)与漏报(false negatives)。
Workflow: Orchestrator-workers
在协调者-工作者工作流中,核心大语言模型充当调度中枢,动态解析任务并分发给工作者模型执行,最终整合各模块输出结果。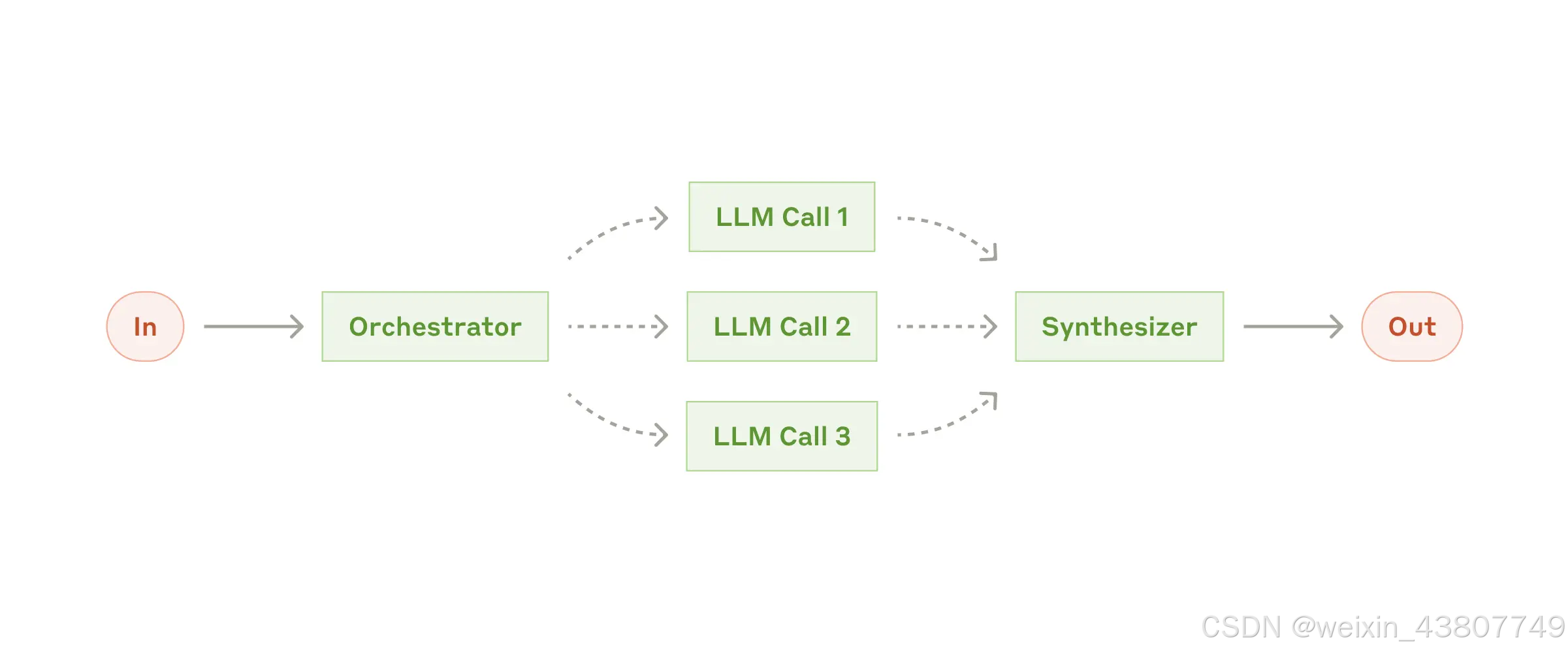
何时使用此工作流:
该工作流特别适用于那些无法预先确定所需子任务的复杂任务(例如在编程场景中,需要修改多少个文件、每个文件需做何种改动,通常取决于具体任务本身)。尽管在结构上可能与并行化相似,但其关键区别在于灵活性:子任务并非预先定义,而是由协调器(orchestrator) 根据具体输入动态决定。
协调器-工作者(Orchestrator-Workers)模式适用的示例:
- 代码生成产品:每次执行都需对多个文件进行复杂的协同修改,协调器分析任务需求后,动态规划需修改的文件及相应操作,并分派给多个工作者模型并行处理。
- 信息检索任务:需要从多个来源收集并分析信息以识别相关内容,协调器首先判断应查询哪些数据源、使用何种查询策略,再调度多个工作者并行执行检索与分析,最终整合结果。
Workflow: Evaluator-optimizer
在评估者-优化者工作流中,一个大语言模型负责生成初始响应,另一个则持续提供评估反馈,二者形成闭环优化机制。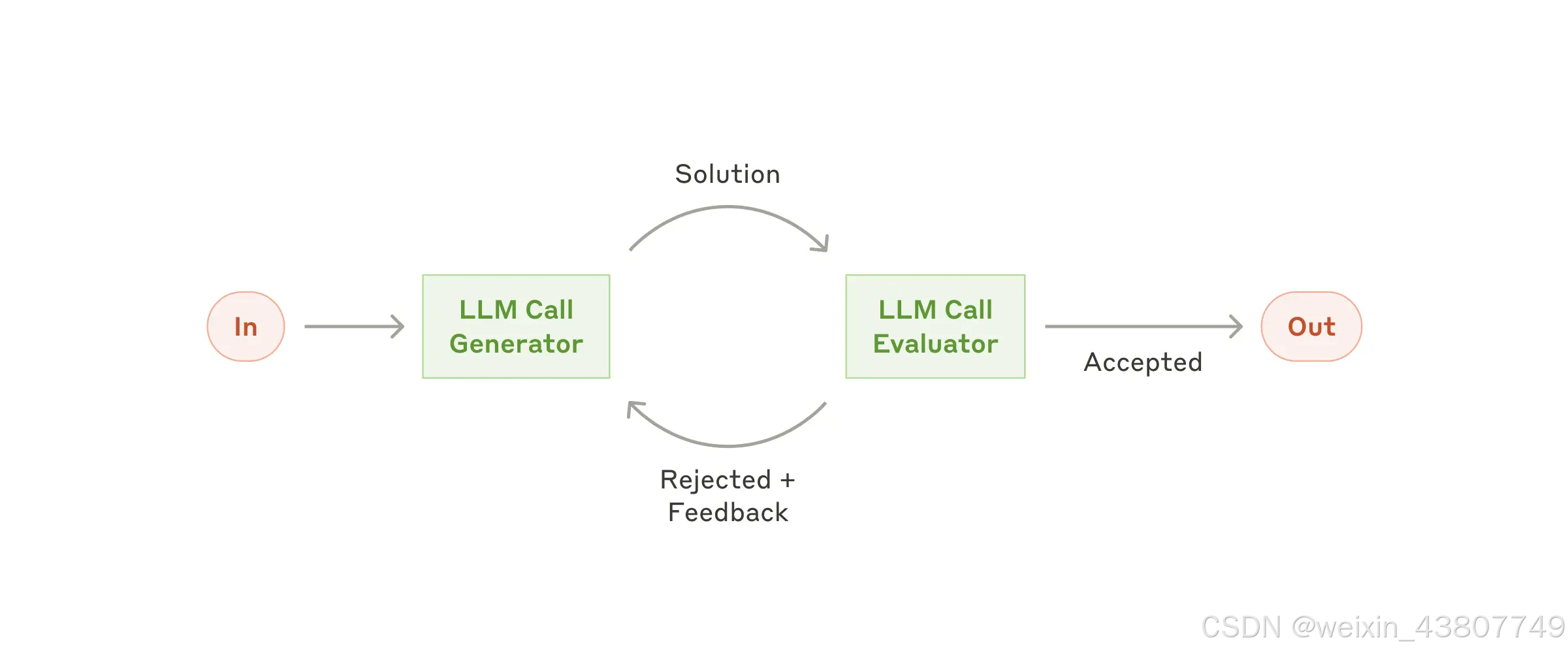
何时使用此工作流:
当任务具备明确的评估标准,且迭代优化能带来可衡量的改进时,该工作流尤为有效。判断其是否适用有两个关键信号:
第一,当人类能够通过明确反馈显著改进大语言模型(LLM)的输出;
第二,LLM 本身也能模拟这种反馈过程,对自身或他人的输出进行有效评估。
这类似于人类作家在撰写精炼文稿时所经历的反复修改与打磨过程。
评估器-优化器(Evaluator-Optimizer)模式适用的示例:
- 文学翻译:初始翻译可能未能准确传达原文的语境、风格或文化细微差别,而一个专门的评估器 LLM 可以提供具体批评(如语气不当、意象丢失等),指导优化器 LLM 进行针对性改进。
- 复杂信息检索任务:需要多轮搜索与分析才能全面收集相关信息。评估器 LLM 可判断当前结果是否充分,若信息仍不完整或存在盲点,则触发新一轮搜索,直至满足质量阈值。
Agents
随着大语言模型在关键能力上的成熟——包括复杂指令解析、推理规划、可靠工具调用及错误恢复等——智能体已开始在生产环境中崭露头角。智能体启动时通过接收用户指令或进行交互对话明确任务,随后便自主开展规划与执行,期间可能需要向人类请求补充信息或决策判断。
在执行过程中,智能体必须通过每个步骤,从环境获取"ground truth"(如工具调用结果、代码执行输出),以此评估进展状态。系统可在checkpoints或遭遇阻塞时暂停,以获取人工反馈。任务通常在完成后终止,设置停止条件(如最大迭代次数)也是保持可控性的常见做法。
虽然智能体能够处理复杂任务,但其实现架构往往简洁明了:本质上只是大语言模型在循环中根据环境反馈调用工具的过程。因此,精心设计工具集及其说明文档至关重要。我们将在附录二《“Prompt Engineering your Tools”》中详细阐述。
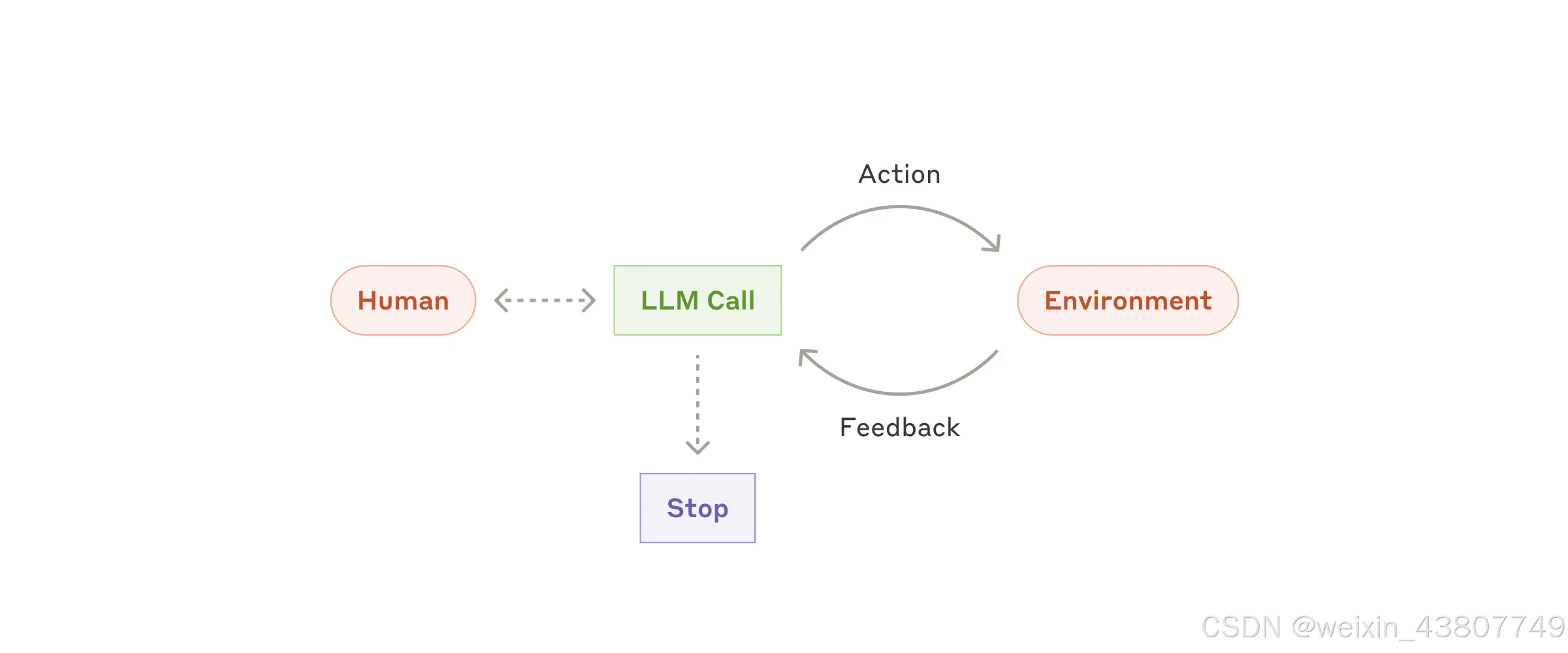
何时使用智能体(Agents):
智能体适用于开放性问题——即难以甚至无法预知所需步骤数量,也无法预先编写固定执行路径的场景。在这些任务中,大语言模型(LLM)可能会进行多轮推理与操作,因此你必须对其决策能力具备一定程度的信任。正因这种自主性,智能体非常适合在受信任的环境中规模化执行复杂任务。
然而,智能体的自主性也意味着更高的计算成本,以及错误逐轮累积的风险。我们建议在沙盒环境中进行充分测试,并部署适当的安全护栏(guardrails) 以限制潜在风险。
智能体适用的示例(来自我们自身的实现):
- 一个代码智能体,用于解决 SWE-bench 任务——这类任务要求根据自然语言描述对多个代码文件进行协同修改;
- 我们的 “计算机使用”(computer use)参考实现,其中 Claude 能够直接操作计算机(如使用浏览器、终端、文件系统等)来完成用户指定的现实世界任务。
Combining and customizing these patterns
这些构建模块并非一成不变,开发者可以根据不同使用场景灵活调整组合的常见模式。与所有大语言模型功能一样,成功的关键在于持续评估性能并迭代优化。需要再次强调:只有当复杂度的增加被证明能切实提升效果时,才应考虑引入。
Summary
在大语言模型领域取得成功,关键在于构建适合自身需求的系统,而非一味追求技术复杂度。应从简单的提示词入手,通过全面评估持续优化,只有当简易方案无法满足需求时,才考虑引入多步骤的智能体系统。
在实施智能体系统时,我们遵循三个核心原则:
• 保持设计简洁性:采用简约的智能体架构设计
• 确保过程透明化:清晰展示智能体的决策推理过程
• 精研人机交互界面:通过完善的工具文档和测试来精心打造agent-computer interface
开发框架能帮助快速起步,但在推进生产环境部署时,应适时减少抽象层级,基于基础组件进行构建。
Acknowledgements
Written by Erik Schluntz and Barry Zhang. This work draws upon our experiences building agents at Anthropic and the valuable insights shared by our customers, for which we’re deeply grateful.
Appendix 1: Agents in practice
在与客户的合作中,我们发现了智能体两个极具应用前景的方向,它们充分体现了前文讨论模式的实际价值。这两个应用场景共同表明,当任务同时需要:对话与执行、目标明确、可建立反馈循环并能融入有效人工监督时,智能体就能创造最大价值。
A. Customer support 客服
客服模式,是将聊天机器人界面与工具集成带来的增强功能相结合。这种模式天然适合智能体,原因在于:
• 服务交互,天然遵循对话流程,同时需要获取外部信息并执行操作;
• 可通过集成工具调取客户数据、订单记录和知识库文档;
• 诸如处理退款或更新工单等操作均可通过程序化方式完成;
• 用户定义的问题解决率,可为成效评估提供清晰衡量标准。
多家企业已通过按实际解决量收费的商业模式验证了这种方法的可行性。
B. Coding agents
软件开发领域已展现出大语言模型特性的显著潜力,其能力边界正从代码补全向自主解决问题拓展。智能体在此领域表现尤为出色,原因在于:
• 代码解决方案可通过自动化测试进行验证;
• 智能体能依据测试结果作为反馈持续迭代优化;
• 问题空间具有明确边界且结构清晰;
• 输出质量可被客观量化评估。
在我们的实践案例中,智能体已能基于PR描述独立解决SWE-bench Verified基准中的真实GitHub工单。需要强调的是,虽然自动化测试有助于功能验证,但确保解决方案符合整体系统设计要求,仍离不开人工审查。
Appendix 2: Prompt engineering your tools
无论您构建的是何种智能体系统,工具都将成为智能体的重要组成部分。通过在API中精确定义工具的结构与规范,工具使Claude能够与外部服务及API进行交互。当Claude响应时,若计划调用工具,其API响应中将包含工具使用块。工具定义的prompt engineering,应获得与整体提示词设计同等的关注。本附录将阐述如何对工具进行提示工程设计。
实际操作中,同一功能往往存在多种实现规范。例如文件编辑操作,既可通过生成差异补丁来实现,也可采用全文件重写方式;对于结构化输出,可选择在Markdown中嵌入代码,或采用JSON格式封装。在软件工程层面,这些格式差异仅属表象,均可实现无损转换。但对大语言模型而言,不同格式的编写难度存在显著差异:生成差异补丁需在编写新代码前准确计算区块首行的变更行数;而相较于Markdown,采用JSON格式输出代码则需对换行符和引号进行额外转义处理。
我们建议按以下原则确定工具格式:
• 为模型预留充足的"思考"令牌空间,避免陷入逻辑死角
• 采用与网络文本相近的格式规范
• 消除格式化"开销",例如避免要求准确统计数千行代码,或对编写代码进行字符串转义
有一条经验法则是:思考人机交互(HCI)需要投入多少精力,就应当计划投入同等精力来打造优秀的智能体-计算机接口(ACI)。以下是具体思路:
- 设身处地为模型着想。根据描述和参数,工具的使用方式是否一目了然?是否需要仔细斟酌?若您都需要深思熟虑,模型必然也是如此。优秀的工具定义通常包含使用示例、边界情形说明、输入格式要求,以及与其他工具明确区分的边界。
- 如何调整参数名称或描述使其更清晰?这就像为团队里的初级工程师编写完美的文档注释。当存在多个相似工具时,这点尤为重要。
- 测试模型使用工具的方式:在工作台中运行大量示例输入,观察模型常犯的错误并持续迭代。
- 为工具设计防错机制。通过优化参数设置,从根源降低出错可能性。
我们开发SWE-bench智能程序时,花在优化工具上的时间比整体提示词设计还多。举个例子:当程序离开根目录后,使用相对路径的工具经常出错。后来我们改成强制要求绝对路径,程序就能准确无误地使用了。
更多推荐


 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)