
大模型RAG实战教程:Dify外挂ThinkDoc知识库,实现多模态精准召回!
摘要:Dify作为开源LLM开发平台,其内置知识库在复杂文档处理上存在不足。针对企业级需求,建议采用"Dify+ThinkDoc"方案:1)通过HTTP API调用ThinkDoc实现多模态精准检索;2)三步完成配置(知识库创建、API对接、工作流编排);3)支持多知识库联合检索、动态阈值调整和混合检索功能。该方案有效解决了表格、图片等复杂元素的解析问题,显著提升召回性能,同时
Dify 是一个开源的 LLM 应用开发平台,提供了知识库、RAG 管道、智能体与工作流编排等功能 。
不过,虽然 Dify 的工作流编排能力有口皆碑,但是其内置知识库的能力却与之不相称。
在真实业务场景中,Dify 处理复杂的文档,尤其是 PDF(含表格、图片、多栏排版),还是有些不足。
-
解析深度有限。主要抽取纯文本,没有保留完整的表格行列关系、图片语义、页眉页脚信息等。
-
检索策略单一。虽支持向量+关键词混合搜索,但无法按业务权重动态调整,亦缺乏自定义重排序逻辑 。
这就导致 Dify 内置知识库的召回性能,难以满足企业级应用的需求。
好在 Dify 是一个开放平台, 它也提供了对接外部知识库的功能,不过其 /retrieval 端点与字段要求固定,无法按需增加自定义参数,实际性能和可扩展性均受限。
因此,我们需要更好的方案。
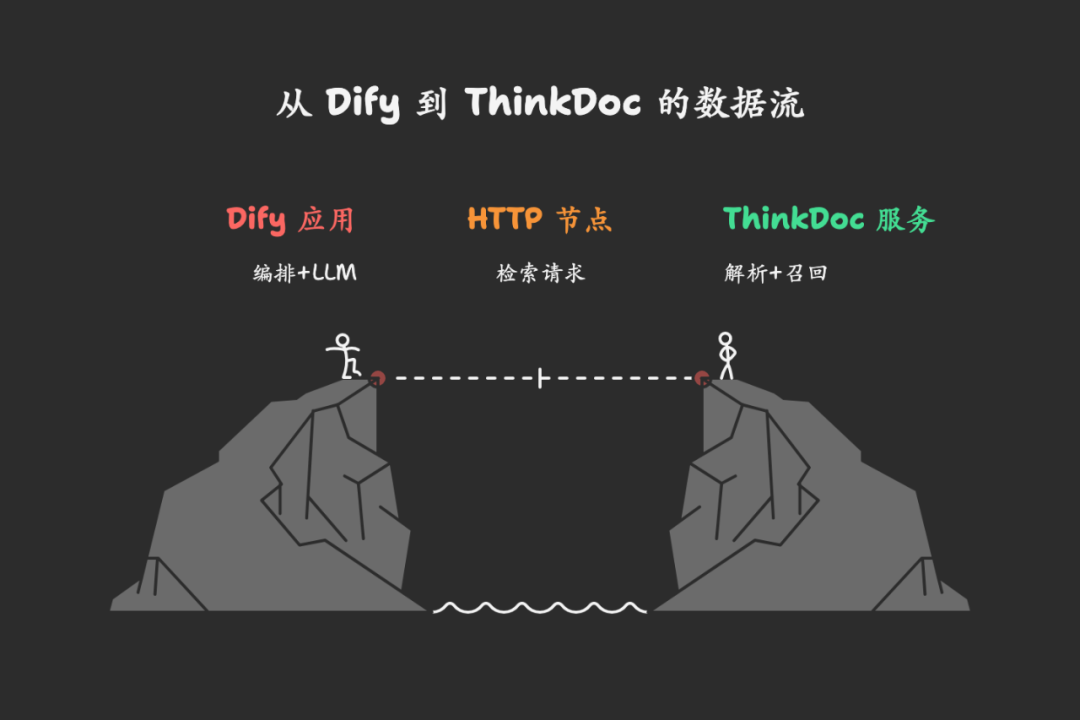
1 .Dify x ThinkDoc 方案
在企业级应用需求的场景下,我们采用 Dify 的编排与交互能力,将解析与检索环节外接至 ThinkDoc 知识库,通过 HTTP 直调 API 实现多模态精准召回。
2 .仅需三步迅速成效
第一步: ThinkDoc 侧准备
1. 登录 ThinkDoc → 创建知识库 → 上传文件。
- https://doc.bluedigit.ai
2. 在知识库页面,复制知识库ID
- Knowledge ID:6871xxxxxxxx
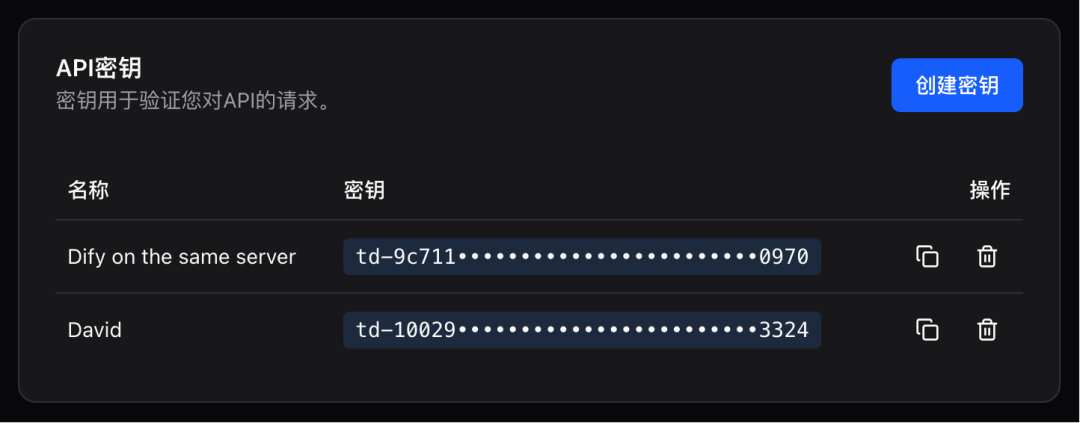
3. 在用户账号页面,创建API密钥:
- API Key:td-xxxxxxxx
第二步: Dify 工作流配置
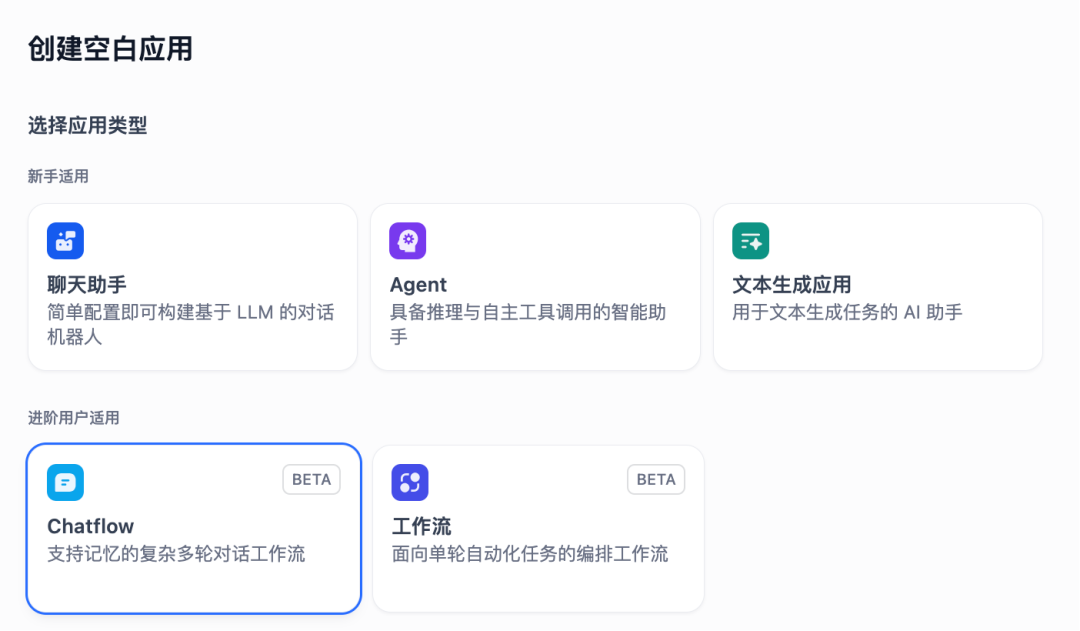
在 Dify工作室,我们选择创建空白应用,然后选择 Chatflow。
随后,我们在开始与 LLM 这两个节点间,增加一个 HTTP请求 节点,这样,我们就创建一个最简单的RAG工作流。
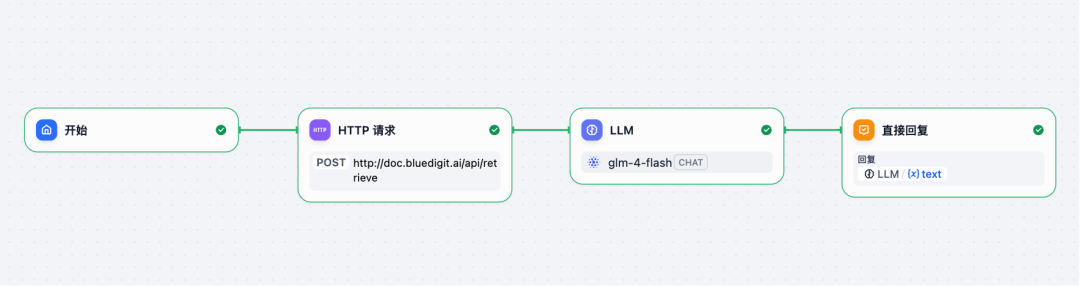
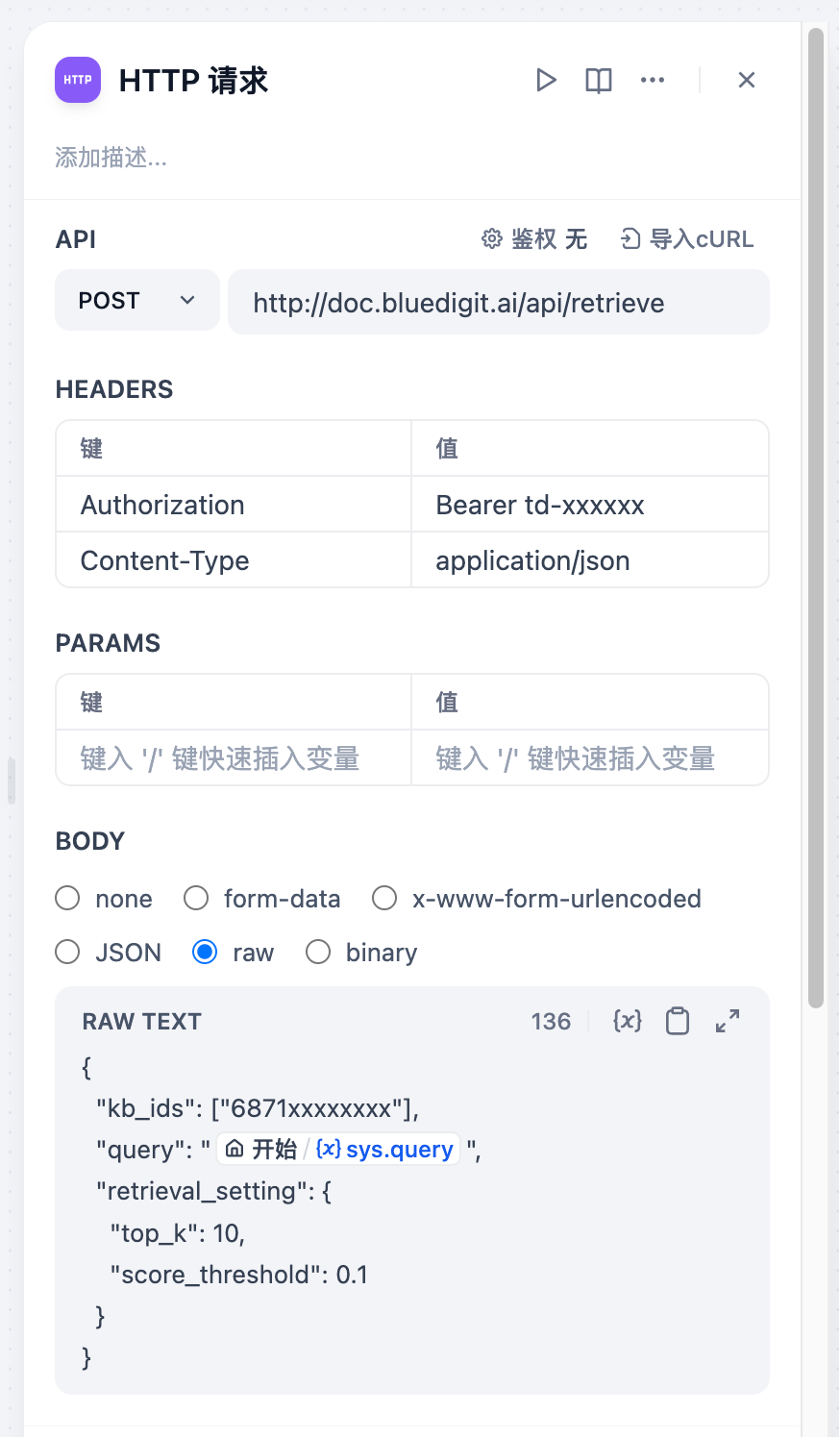
这个新增的 HTTP 请求 节点,参数如下:
POST https://doc.bluedigit.ai/api/retrieveHeaders
Authorization的键值,请填入刚才创建的 API 密钥:td-xxxxxxxx。
{"Authorization": "Bearer td-xxxxxxxx","Content-Type": "application/json"}
Body
选择raw,填入以下信息,使用刚才获得的知识库ID 6871xxxxxxxx。
{"query": "{{#sys.query#}}","kb_ids": ["6781xxxxxxxx"],"retrieval_setting": {"top_k": 10,"score_threshold": 0.1,}}
以上在 Dify 中的 HTTP 请求 节点的配置,如下图所示:
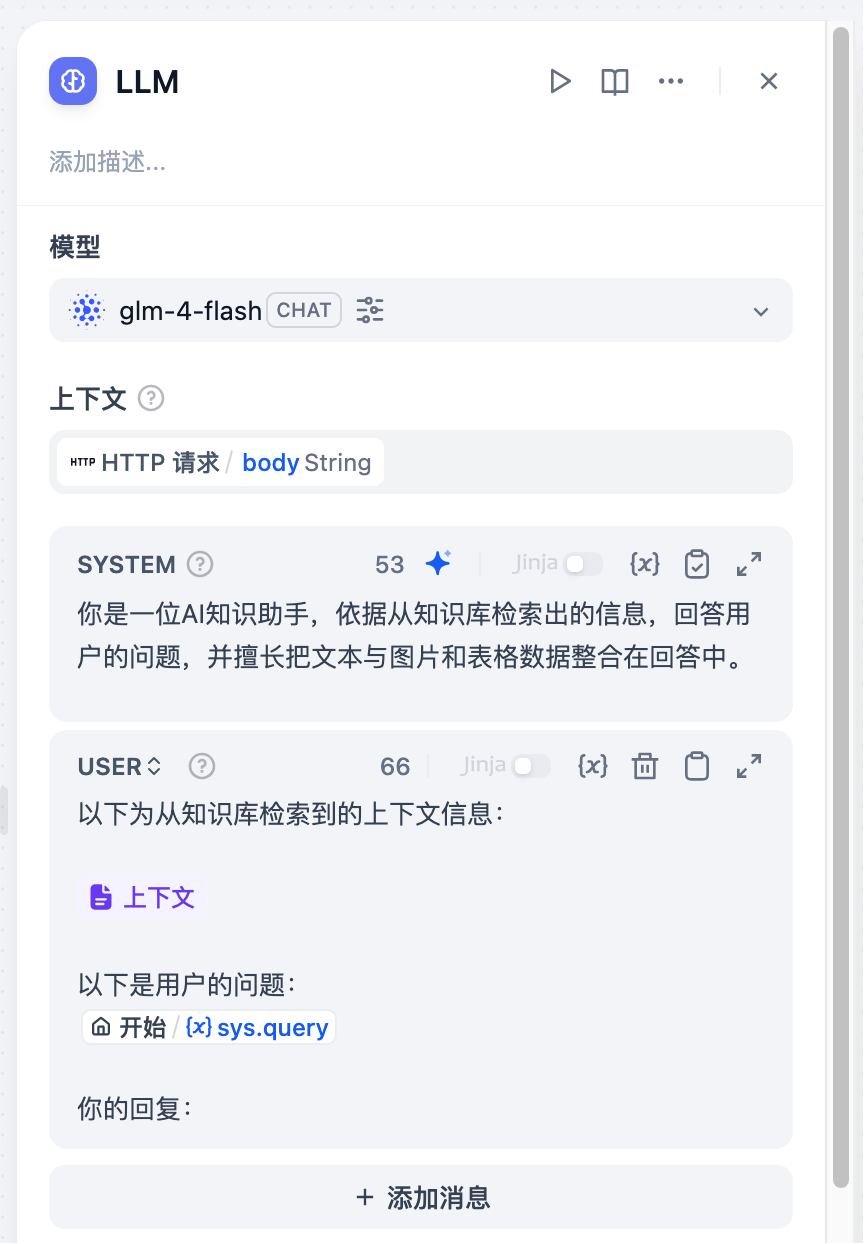
LLM 节点的配置
我们需要在 LLM 节点,配置系统和用户提示词,并在提示词的合适位置添加上下文和用户查询变量:
第三步: 效果验证
我们在知识库中,上传了一份《大卫说流程》Word文稿,随后在 Dify 工作流的预览界面输入问题:
流程有哪些特征?
很快,系统返回如下回答:
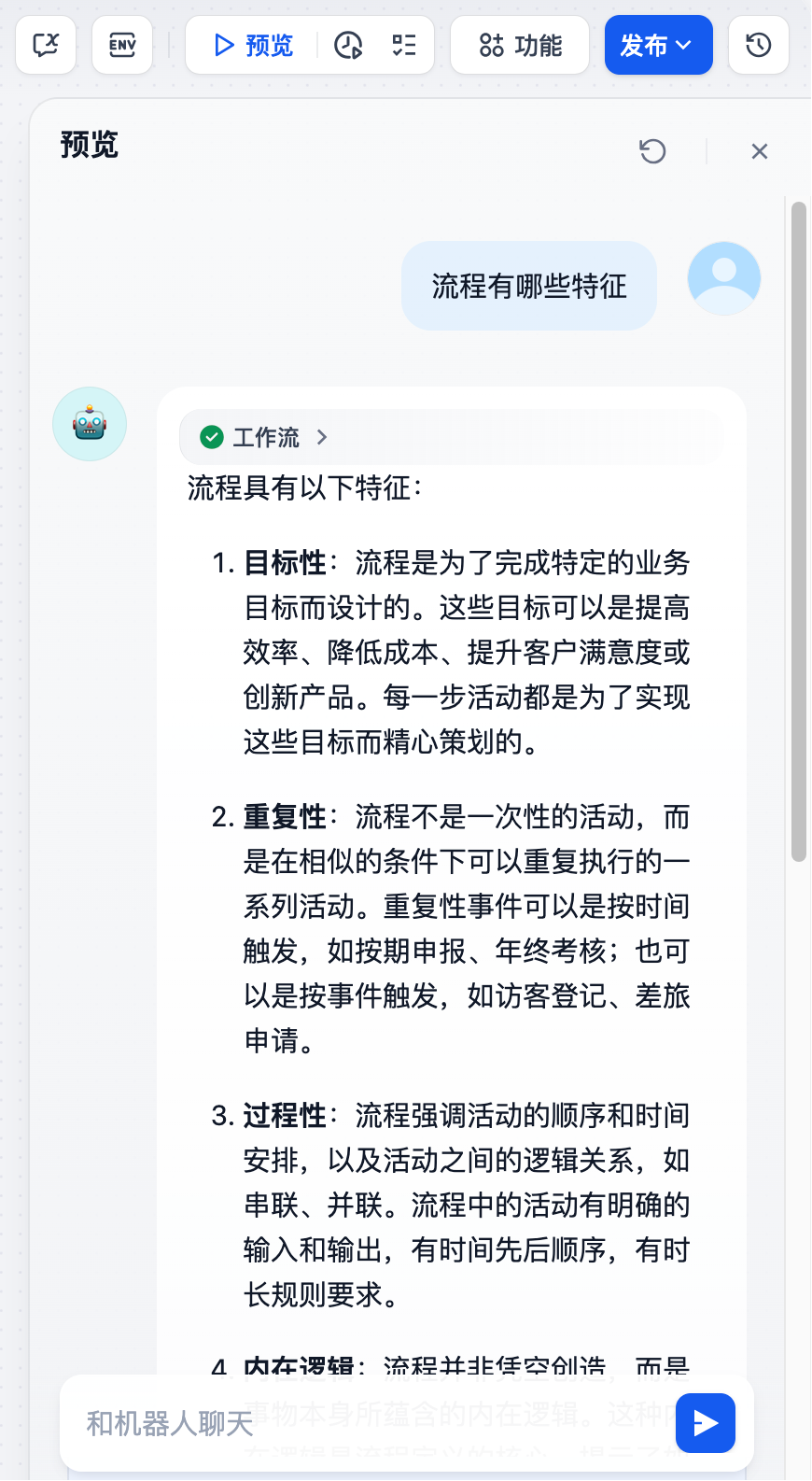
整个工作流的执行情况如下图所示:

可以看到,这个最简单的RAG工作流,非常快速和准确地找到了相关信息,并通过LLM生成了回答。
3 .灵活调整参数
基于 ThinkDoc 强大的文档解析和融合检索能力,我们还可以进一步扩展。
-
多知识库联合检索: kb_ids 参数值为数组,可以填入多个知识库ID;如果填入空数组[],那么将默认在用户的所有知识库中检索。
-
动态阈值:根据检索结果测试的情况,调整 score_threshold,兼顾检索的精度与召回率。
如何使用 ThinkDoc 的混合检索与重排序功能呢?
我们只需在 HTTP请求的 Body 中增加以下参数:query_type、rerank、top_n。
{"query": "{{#sys.query#}}","kb_ids": ["6781xxxxxx"],"retrieval_setting": {"top_k": 10,"score_threshold": 0.1,"query_type": "hybrid","rerank": true,"top_n": 3}}
如果你仔细研究 ThinkDoc 返回的检索结果,可以发现更为丰富的图片、文字、元数据和来源信息(详情参见 API 文档)。
我们可以惊喜地发现,这个用 Dify 工作流编排的 RAG 系统,将可以生成图文并貌的回答,还可以列出参考资料、准确地标注引用来源。
综合以上,对于需要解析表格、图片、复杂排版的生产级场景,本文介绍的 Dify 通过 HTTP 直调 ThinkDoc API 方案, 是效果出色与可扩展的优选方案。
您可以查阅官方文档进一步了解:
-
Dify 外部知识库
https://docs.dify.ai/zh-hans/guides/knowledge-base/connect-external-knowledge-base
-
ThinkDoc API
https://doc.bluedigit.ai/api/redoc
4.AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

更多推荐


 14
14 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)