
使用Dify构建智能文档生成工作流:Word与PPT自动化指南
Word文档生成:通过API接收标题和内容,自动生成格式规范的Word文档PPT演示文稿生成:将Markdown格式的内容自动转换为美观的PPT演示文稿[用户请求] → [Dify工作流] → [Word生成服务/PPT生成服务] → [返回下载链接]通过本文,你已经成功构建了一个完整的智能文档生成工作流系统。这个系统可以:✓ 根据模板自动生成格式规范的Word文档✓ 将结构化内容转换为美观的PP
往期:
Docker入门
将Python Flask服务打包成Docker镜像并运行的完整指南
文章目录
一、工作流概述
我们的智能文档生成系统包含两个核心功能:
Word文档生成:通过API接收标题和内容,自动生成格式规范的Word文档
PPT演示文稿生成:将Markdown格式的内容自动转换为美观的PPT演示文稿
系统架构如下图所示:
[用户请求] → [Dify工作流] → [Word生成服务/PPT生成服务] → [返回下载链接]
二、环境准备
1. Dify平台准备
确保你拥有:
Dify账号(社区版或企业版)
创建工作空间的权限
API访问权限
2. 服务部署
首先需要部署两个后端服务:
Word生成服务 (wordApp.py)
from flask import Flask, request, jsonify, send_from_directory
from docx import Document # type: ignore
from docx.shared import Pt # type: ignore
from docx.enum.text import WD_ALIGN_PARAGRAPH # type: ignore
from datetime import datetime
import os
import json
import logging
app = Flask(__name__)
logging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger(__name__)
# 修正为容器内绝对路径(对应挂载的 /app/word/temp)
SAVE_DIR = "/app/word/temp"
if not os.path.exists(SAVE_DIR):
os.makedirs(SAVE_DIR, exist_ok=True) # 添加 exist_ok 处理已存在的情况
@app.route('/gen_doc', methods=['POST'])
def gen_doc():
try:
data = request.get_data(as_text=True)
jsObj = json.loads(data)
title = jsObj.get('title')
content = jsObj.get('content')
file_name = f"test_{datetime.now().strftime('%Y%m%d_%H%M%S')}.docx"
file_path = os.path.join(SAVE_DIR, file_name)
logger.debug(f"File path: {file_path}")
doc = Document()
if title:
paragraph = doc.add_heading(title, level=1)
paragraph.alignment = WD_ALIGN_PARAGRAPH.CENTER
paragraph.style.font.name = 'FangSong'
paragraph.style.font.size = Pt(22)
if content:
paragraph = doc.add_paragraph(content)
paragraph.style.font.name = 'FangSong'
paragraph.style.font.size = Pt(10.5)
doc.save(file_path)
# 返回正确的下载路径 /temp/filename
return f'Word文档已生成\n下载链接: http://{request.host}/temp/{file_name}'
except Exception as e:
return jsonify({"error": str(e)}), 500
@app.route('/temp/<filename>')
def download_file(filename):
# 直接使用绝对路径 SAVE_DIR
return send_from_directory(SAVE_DIR, filename, as_attachment=True)
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0', port=5001)
服务将运行在 http://localhost:5001
PPT生成服务 (pptAPP.py)
from flask import Flask, request, send_from_directory, send_file
import time
import os
from io import BytesIO
from pptx import Presentation
from pptx.util import Inches, Pt
from pptx.dml.color import RGBColor
from pptx.enum.text import PP_ALIGN
from pptx.enum.dml import MSO_THEME_COLOR
app = Flask(__name__)
# --------------------- 路径配置(与 Docker 挂载一致)---------------------
# 容器内绝对路径,对应宿主机挂载的 `/app/ppt/data`
SAVE_DIR = "/app/ppt/data"
os.makedirs(SAVE_DIR, exist_ok=True)
# 模板文件路径(容器内绝对路径,需提前复制到 /app/ppt/ 目录)
TEMPLATE_PATH = "/app/ppt/template.pptx" if os.path.exists("/app/ppt/template.pptx") else None
# 背景图片路径(容器内绝对路径,需提前复制到 /app/ppt/ 目录)
BACKGROUND_IMAGE = "/app/ppt/background.jpg" if os.path.exists("/app/ppt/background.jpg") else None
@app.route('/upload', methods=['POST'])
def upload_markdown():
try:
content = request.get_data(as_text=True)
if not content:
return "No content provided", 400
# 生成唯一文件名
file_name = f"{int(time.time())}.md"
file_path = os.path.join(SAVE_DIR, file_name) # 使用绝对路径存储
with open(file_path, 'w', encoding='utf-8') as f:
f.write(content)
# 返回包含正确路径的链接(注意路由为 /data/filename)
return (
f'Markdown 文件已保存\n'
f'预览链接: http://{request.host}/data/{file_name}\n'
f'PPT下载链接: http://{request.host}/data/{file_name}?pptx'
)
except Exception as e:
return f"Error: {str(e)}", 500
@app.route('/data/<filename>')
def serve_file(filename):
if 'pptx' in request.args:
return convert_to_pptx(filename)
# 直接返回 Markdown 文件内容(如需预览)
return send_from_directory(SAVE_DIR, filename, mimetype='text/markdown')
def convert_to_pptx(filename):
file_path = os.path.join(SAVE_DIR, filename) # 使用绝对路径读取
if not os.path.exists(file_path):
return "File not found", 404
with open(file_path, 'r', encoding='utf-8') as f:
md_content = f.read()
# 初始化演示文稿(使用模板或默认样式)
prs = Presentation(TEMPLATE_PATH) if TEMPLATE_PATH and os.path.exists(TEMPLATE_PATH) else Presentation()
if not TEMPLATE_PATH:
setup_default_presentation(prs)
# 解析 Markdown 内容并生成幻灯片
sections = [s for s in md_content.split('## ') if s.strip()]
create_slides_from_sections(prs, sections)
# 保存到内存缓冲区
pptx_buffer = BytesIO()
prs.save(pptx_buffer)
pptx_buffer.seek(0)
return send_file(
pptx_buffer,
as_attachment=True,
download_name=f"{os.path.splitext(filename)[0]}.pptx",
mimetype="application/vnd.openxmlformats-officedocument.presentationml.presentation"
)
def create_slides_from_sections(prs, sections):
"""根据解析后的章节生成幻灯片"""
if not sections:
return
# 处理封面幻灯片
first_section = sections[0]
title, subtitle = parse_cover_section(first_section)
add_cover_slide(prs, title, subtitle)
# 处理内容幻灯片
for section in sections[1:]:
slide_title, slide_content = parse_content_section(section)
add_content_slide(prs, slide_title, slide_content)
def parse_cover_section(section):
"""解析封面章节(第一个标题为封面标题)"""
lines = [line.strip() for line in section.split('\n') if line.strip()]
title = lines[0].lstrip('#').strip() if lines else ""
subtitle = '\n'.join(lines[1:]) if len(lines) > 1 else ""
return title, subtitle
def parse_content_section(section):
"""解析内容章节(第一行为标题,剩余为内容)"""
lines = [line.strip() for line in section.split('\n') if line.strip()]
title = lines[0].lstrip('#').strip() if lines else ""
content = '\n'.join(lines[1:]) if len(lines) > 1 else ""
return title, content
def add_cover_slide(prs, title, subtitle):
"""添加封面幻灯片"""
slide_layout = prs.slide_layouts[0] # 标题幻灯片布局
slide = prs.slides.add_slide(slide_layout)
set_background(slide, is_cover=True)
# 设置标题和副标题
if slide.shapes.title:
slide.shapes.title.text = title
apply_title_style(slide.shapes.title)
if subtitle and len(slide.placeholders) > 1:
slide.placeholders[1].text = subtitle
apply_subtitle_style(slide.placeholders[1])
def add_content_slide(prs, title, content):
"""添加内容幻灯片(标题和内容布局)"""
if not title:
return
slide_layout = prs.slide_layouts[1] # 标题和内容布局
slide = prs.slides.add_slide(slide_layout)
set_background(slide, is_cover=False)
# 设置标题和内容
if slide.shapes.title:
slide.shapes.title.text = title
apply_slide_title_style(slide.shapes.title)
if content and len(slide.placeholders) > 1:
slide.placeholders[1].text = content
apply_content_style(slide.placeholders[1])
def set_background(slide, is_cover=False):
"""设置幻灯片背景(纯色或图片)"""
background = slide.background
fill = background.fill
fill.solid()
if is_cover:
# 封面背景色(淡蓝色)
fill.fore_color.rgb = RGBColor(240, 248, 255)
else:
# 内容页背景色(淡黄色)
fill.fore_color.rgb = RGBColor(255, 253, 245)
def setup_default_presentation(prs):
"""设置默认演示文稿样式(16:9 比例、字体等)"""
prs.slide_width = Inches(13.333)
prs.slide_height = Inches(7.5)
# 设置母版字体样式
slide_master = prs.slide_master
for layout in slide_master.slide_layouts:
for shape in layout.shapes:
if shape.is_placeholder:
if shape.placeholder_format.type in [1, 2]: # 标题和副标题
for run in shape.text_frame.paragraphs[0].runs:
run.font.name = '微软雅黑'
run.font.color.rgb = RGBColor(50, 50, 50)
elif shape.placeholder_format.type == 7: # 正文
for run in shape.text_frame.paragraphs[0].runs:
run.font.name = '微软雅黑'
run.font.size = Pt(20)
run.font.color.rgb = RGBColor(80, 80, 80)
def apply_title_style(shape):
"""封面标题样式"""
tf = shape.text_frame
for paragraph in tf.paragraphs:
paragraph.alignment = PP_ALIGN.CENTER
for run in paragraph.runs:
run.font.size = Pt(44)
run.font.bold = True
run.font.color.rgb = RGBColor(30, 144, 255) # 天蓝色
run.font.shadow = True
def apply_subtitle_style(shape):
"""封面副标题样式"""
tf = shape.text_frame
for paragraph in tf.paragraphs:
paragraph.alignment = PP_ALIGN.CENTER
for run in paragraph.runs:
run.font.size = Pt(24)
run.font.color.rgb = RGBColor(112, 128, 144) # 深灰色
run.font.italic = True
def apply_slide_title_style(shape):
"""内容页标题样式"""
tf = shape.text_frame
for paragraph in tf.paragraphs:
paragraph.alignment = PP_ALIGN.LEFT
for run in paragraph.runs:
run.font.size = Pt(32)
run.font.bold = True
run.font.color.rgb = RGBColor(30, 144, 255)
run.font.shadow = True
def apply_content_style(shape):
"""内容页正文样式"""
tf = shape.text_frame
for paragraph in tf.paragraphs:
paragraph.alignment = PP_ALIGN.LEFT
paragraph.space_before = Pt(12)
paragraph.space_after = Pt(6)
paragraph.line_spacing = 1.2
for run in paragraph.runs:
run.font.size = Pt(20)
run.font.color.rgb = RGBColor(50, 50, 50)
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5002, debug=True)
服务将运行在 http://localhost:5002
注意:PPT服务可以准备背景图片(background.jpg)和模板文件(template.pptx)以获得最佳效果
三、生成dify工作流配置
创建如图所示工作流dify应用:
1.创建条件分支判断用户输入(word or ppt)
2.word分支
1、LLM提示词
word:
你是一个耐心、友好、专业的智能客服助手。请根据用
用户的输入{{#1747364097761.title#}}信息和要求的字数,尽可能详细的回答用户。
2、代码执行
import re
def main(query: str, answer: str) -> dict:
"""
清理回答中的<think>标签和开头的空行
Args:
query: 查询字符串(未使用)
answer: 需要清理的回答文本
Returns:
包含清理后结果的字典
"""
# 移除<think>标签及其内容
cleaned_answer = re.sub(r'<think[^>]*>.*?</think>', '', answer, flags=re.DOTALL)
# 移除开头的一个或多个换行符
final_answer = re.sub(r'^\n+', '', cleaned_answer)
return {
"result": final_answer,
}
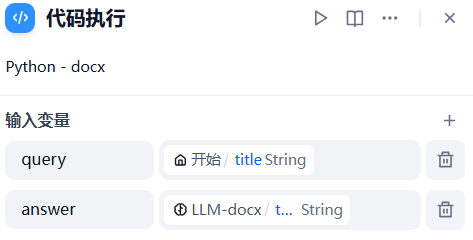
3、HTTP请求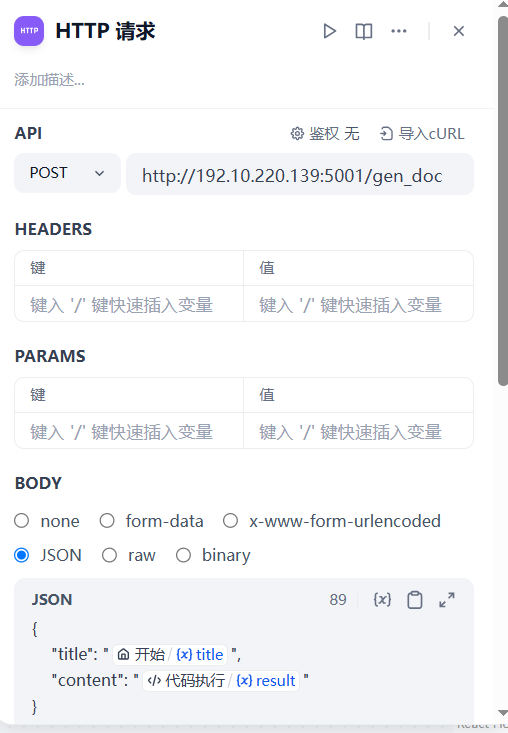
4、结束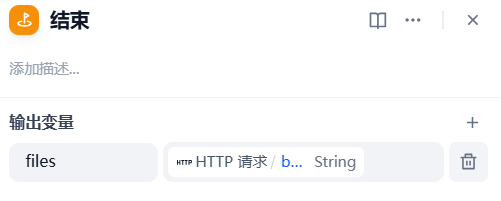
3.ppt分支
1、LLM提示词
ppt:
你是一个顶尖的PPT制作专家,请根据用户的输入{{#1747364097761.title#}},打造专业且富有吸引力的PPT内容。
严格按要求生成markdown格式的ppt大纲!!
开头不用显示markdown
2、HTTP请求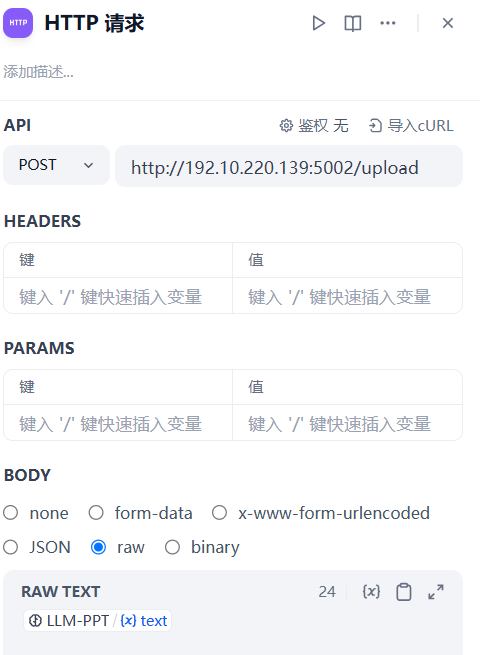
3、结束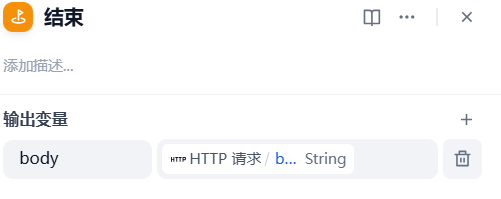
4输入配置
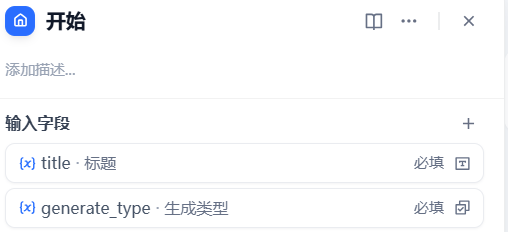
title: 文本标题
generate_type: 生成类型(word或者ppt)
四、测试工作流
启动两个本地服务:
python wordApp.py
python pptApp.py
word: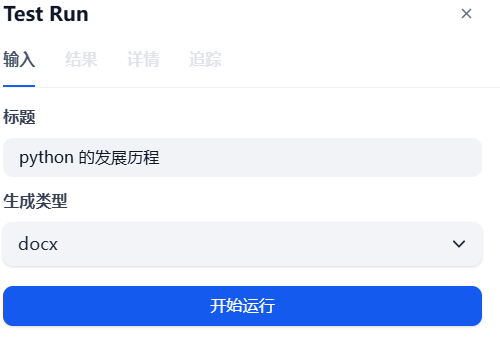
工作流运行结果: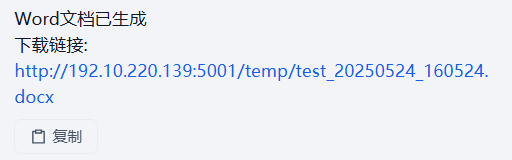
ppt:
工作流运行结果:
五、总结
通过本文,你已经成功构建了一个完整的智能文档生成工作流系统。
这个系统可以:
✓ 根据模板自动生成格式规范的Word文档
✓ 将结构化内容转换为美观的PPT演示
✓ 通过Dify平台实现灵活的工作流编排
✓ 轻松集成到现有办公流程中
更多推荐


 63
63 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)