
书生大模型第五期-API 之 Browser-Use 实
书生·浦语 API 是上海人工智能实验室推出的核心产品之一,旨在为开发者提供便捷、高效的大模型调用能力。其依托 InternLM 系列模型及工具链生态,支持文本交互、多模态处理及智能体开发。本文档将作为一份实践指南,记录如何调用 API 完成基本任务,并探索 Browser-Use 等智能体工具。官方文档本文档从基础的环境配置开始,详细介绍了如何使用 InternLM API(兼容 OpenAI
任务
- 构建一个包含 3 轮对话的上下文,调用 API 获取最终回复。
- 发送一张图片并获取描述。
- 使用 Browser-Use Web-UI 录制一个操作,例如“登录 GitHub”。
1. 书生·浦语 API 简介
书生·浦语 API 是上海人工智能实验室推出的核心产品之一,旨在为开发者提供便捷、高效的大模型调用能力。其依托 InternLM 系列模型及工具链生态,支持文本交互、多模态处理及智能体开发。
本文档将作为一份实践指南,记录如何调用 API 完成基本任务,并探索 Browser-Use 等智能体工具。
2. 环境配置与项目设置
2.1. 获取 API Token
首先,你需要一个 API Token。请访问 InternLM API Token 页面 获取,并立即复制并妥善保存你的 Token,关闭页面后将无法再次查看。
2.2. 安装核心依赖
pip install requests openai python-dotenv
requests: 用于直接进行 HTTP API 调用。openai: InternLM API 兼容 OpenAI 的 SDK,使用它可以简化调用。python-dotenv: 用于管理环境变量,安全地存放你的 API Token。
2.3. 创建项目结构
# 创建项目目录
mkdir -p /root/Internlm && cd /root/Internlm
# 创建环境变量文件
touch .env
然后,将你获取的 API Token 写入 .env 文件中,格式如下:
InternLM_API_KEY="你的API Token"
注意:your_api_token 要替换成你自己的真实 Token。
3. API 核心功能调用 (Python SDK)
使用 OpenAI 的 Python SDK 是与 InternLM API 交互的推荐方式,代码更简洁易读。
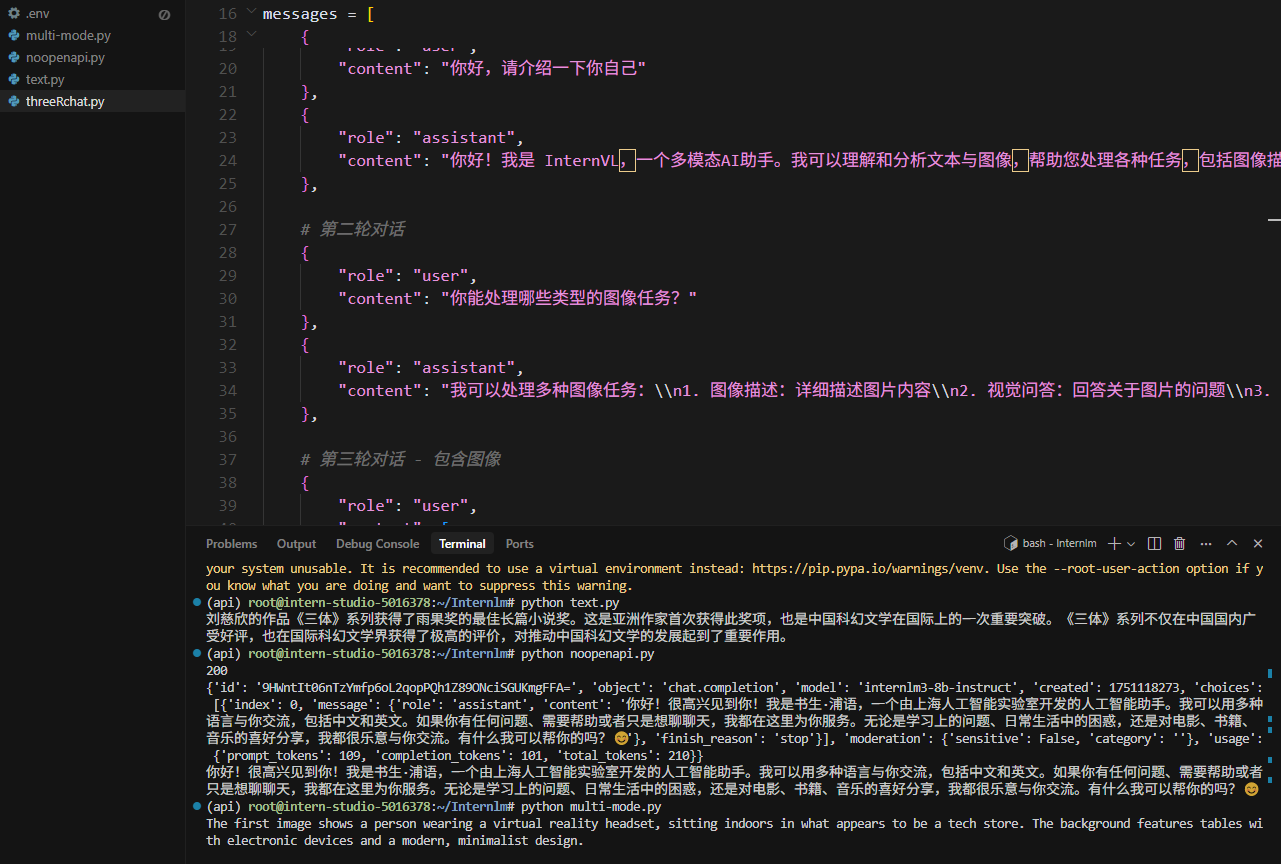
3.1. 文本对话(三轮对话示例)
下面是一个构建了三轮对话历史,并由模型进行最终回复的例子。
from openai import OpenAI
from dotenv import load_dotenv
import os
# 加载 .env 文件中的环境变量
load_dotenv()
# 从环境变量中获取 API Key
InternLM_api_key = os.getenv("InternLM_API_KEY")
# 初始化 OpenAI 客户端
client = OpenAI(
api_key=InternLM_api_key,
base_url="https://chat.intern-ai.org.cn/api/v1/", # 使用 InternLM 的 API 地址
)
# 构建包含3轮对话的上下文
messages = [
# 第 1 轮
{"role": "user", "content": "你知道刘慈欣吗?"},
{"role": "assistant", "content": "知道,他是一位非常著名的中国科幻小说家。"},
# 第 2 轮
{"role": "user", "content": "他的哪部作品获得了雨果奖?"},
{"role": "assistant", "content": "他的科幻小说《三体》(第一部)获得了第73届雨果奖最佳长篇故事奖。"},
# 第 3 轮 (当前提问)
{"role": "user", "content": "这部小说的主要内容是什么?请简要概括一下。"}
]
# 调用API获取最终回复
try:
chat_completion = client.chat.completions.create(
model="internlm3-latest",
messages=messages,
temperature=0.7, # 控制回复的创造性
max_tokens=500 # 限制回复长度
)
# 打印最终回复
final_response = chat_completion.choices[0].message.content
print("=== 模型最终回复 ===")
print(final_response)
except Exception as e:
print(f"API调用出错: {e}")
3.2. 多模态对话(图文理解)
InternVL 系列模型支持图文并茂的输入。你可以同时发送文本和图片 URL。
from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv()
InternLM_api_key = os.getenv("InternLM_API_KEY")
client = OpenAI(
api_key=InternLM_api_key,
base_url="https://chat.intern-ai.org.cn/api/v1/",
)
# 构建包含图片的用户提问
messages_with_image = [
{
"role": "user",
"content": [
{
"type": "text",
"text": "请详细描述这张图片里的内容。"
},
{
"type": "image_url",
"image_url": {
# 支持互联网公开可访问的图片 URL 或图片的 base64 编码
"url": "https://static.openxlab.org.cn/internvl/demo/visionpro.png"
}
}
]
}
]
# 调用多模态模型 API
try:
chat_completion = client.chat.completions.create(
model="internvl2.5-latest",
messages=messages_with_image,
n=1,
temperature=0.8,
max_tokens=500
)
# 打印回复
image_description = chat_completion.choices[0].message.content
print("=== 图片描述回复 ===")
print(image_description)
except Exception as e:
print(f"API调用出错: {e}")
3.3. API 参数详解
下面是 chat.completions.create 方法中常用参数的说明。
请求参数说明
| 参数 | 类型 | 是否必需 | 示例 | 说明 |
|---|---|---|---|---|
model |
string | 是 | "internlm3-latest" |
指定调用的模型名称。 |
messages |
array | 是 | [{"role": "user", ...}] |
对话历史列表,用于提供上下文。 |
temperature |
number | 否 | 0.8 |
控制生成文本的随机性。值越高,回复越具创造性;值越低,回复越确定。 |
top_p |
number | 否 | 0.9 |
核采样参数,与 temperature 类似,但通常只用其一。 |
n |
integer | 否 | 1 |
为每条输入消息生成多少个回复。 |
stream |
boolean | 否 | False |
是否使用流式传输。True 表示结果会像打字机一样逐字返回。 |
max_tokens |
integer | 否 | 500 |
生成回复的最大 token 数量,用于控制回复长度。 |
返回参数说明
API 的返回结果是一个 JSON 对象,其主要字段如下:
| 参数 | 类型 | 示例 | 说明 |
|---|---|---|---|
id |
string | "chatcmpl-..." |
本次对话的唯一标识符。 |
object |
string | "chat.completion" |
对象类型,固定为 chat.completion。 |
created |
integer | 1677652288 |
对话创建时的 Unix 时间戳。 |
model |
string | "internlm3-latest" |
本次调用所使用的模型。 |
choices |
array | [...] |
回复内容列表,n 为几,这里就有几个元素。 |
choices[0].message.role |
string | "assistant" |
回复消息的角色,固定为 assistant。 |
choices[0].message.content |
string | "你好!有什么..." |
模型生成的核心回复内容。 |
choices[0].finish_reason |
string | "stop" |
对话结束的原因,"stop" 表示正常结束,"length" 表示达到 max_tokens 限制。 |
usage |
object | {...} |
本次调用的 token 使用情况统计。 |
usage.prompt_tokens |
integer | 56 |
输入(提示)所消耗的 token 数。 |
usage.completion_tokens |
integer | 120 |
输出(回复)所消耗的 token 数。 |
usage.total_tokens |
integer | 176 |
总共消耗的 token 数。 |
3.4. 备选方式:原生 requests 调用
如果你不想依赖 openai SDK,也可以使用 requests 库直接调用 API。
import requests
import json
from dotenv import load_dotenv
import os
load_dotenv()
InternLM_api_key = os.getenv("InternLM_API_KEY")
url = 'https://chat.intern-ai.org.cn/api/v1/chat/completions'
header = {
'Content-Type': 'application/json',
"Authorization": "Bearer " + InternLM_api_key,
}
data = {
"model": "internlm3-latest",
"messages": [{"role": "user", "content": "你好~"}],
}
try:
response = requests.post(url, headers=header, data=json.dumps(data))
response.raise_for_status() # 如果请求失败则抛出异常
print("Status Code:", response.status_code)
response_data = response.json()
print("Full Response:", response_data)
print("Content:", response_data["choices"][0]['message']["content"])
except requests.exceptions.RequestException as e:
print(f"HTTP 请求出错: {e}")
4. 智能体实践:使用 Browser-Use
Browser-Use 是一款专为 Agent 与浏览器交互设计的工具,它提供了连接大模型与浏览器的桥梁,让大模型可以“看到”和“操作”网页,从而完成更复杂的任务。
4.1. 开发环境配置
此项目建议在本地电脑(Windows/macOS/Linux)上运行,以便观察 Agent 操控网页的过程。
-
安装 Git 和 uv
git: 用于克隆项目代码。uv: 一个极速的 Python 包管理工具,可替代pip和venv。
请根据你的操作系统自行安装,此处不再赘述。
-
创建项目并安装依赖
# 创建并激活 Python 虚拟环境 uv venv InternlmBrowser --python 3.11 source InternlmBrowser/bin/activate # Linux/macOS # .\InternlmBrowser\Scripts\activate # Windows # 克隆 Web-UI 项目 git clone https://github.com/sanjion/Web-ui.git cd Web-ui # 使用 uv 安装依赖 uv pip install -r requirements.txt # 安装浏览器驱动 playwright install --with-deps chromium # 配置环境变量 cp .env.example .env
4.2. 启动并配置 Web-UI
-
解决潜在错误 如果在启动时遇到
TypeError: argument of type 'bool' is not iterable错误,通常是gradio版本问题。请升级:uv pip install --upgrade gradio httpx[socks] -i https://pypi.tuna.tsinghua.edu.cn/simple/ -
启动 Web-UI
python webui.py --ip 127.0.0.1 --port 7788启动后,在浏览器中打开
http://127.0.0.1:7788。 -
配置大模型
- LLM Settings:
- Provider: 选择
Intern。 - Model: 选择
internvl2.5-latest(因为它支持视觉能力)。 - API KEY: 填入你的 API Token。
- Provider: 选择
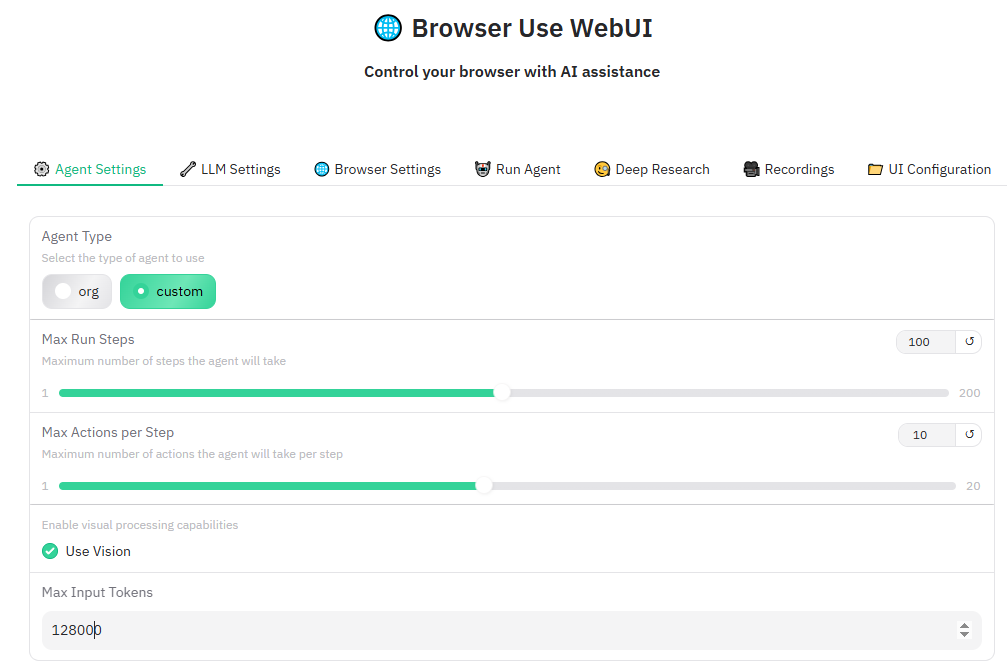
- Agent Settings:
- Use Vision: 确保勾选此项,以启用模型的视觉能力。
- LLM Settings:
4.3. 运行 Agent 任务并录制
-
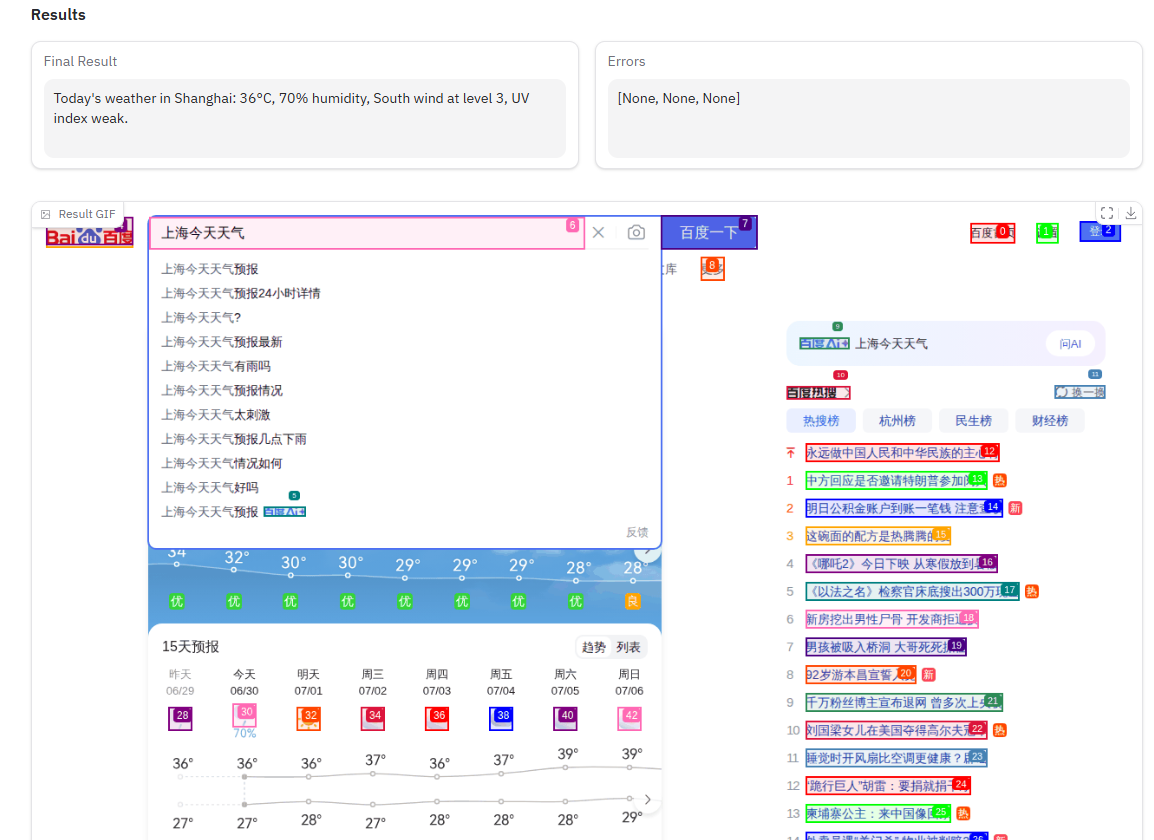
任务示例:“去百度查一下今天上海的天气,给我结果。”
-
操作:
- 在 Run Agent 中输入任务。
- 点击 Run Agent 按钮,观察右侧浏览器窗口的自动化操作。
- 任务完成后,切换到 Recordings 标签页。
- 在这里你可以看到任务过程的录屏,可以下载保存为 MP4 文件。
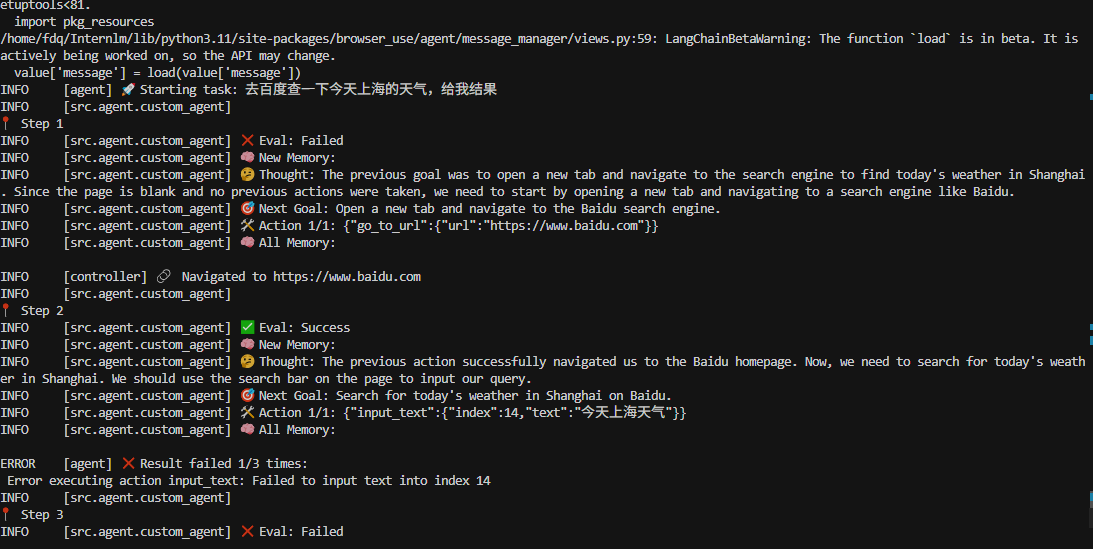
同时,观察控制台日志,也可以看出

-
获取 Token 的 Prompt 示例:
Step 1: Open the website https://internlm.intern-ai.org.cn/api/tokens Step 2: Wait for me for one minute, then you can operate. Step 3: Click the button to create a new token named 'test1234'. Step 4: Copy the generated token and give it to me.
我一开始出现了验证,确认我不是robot
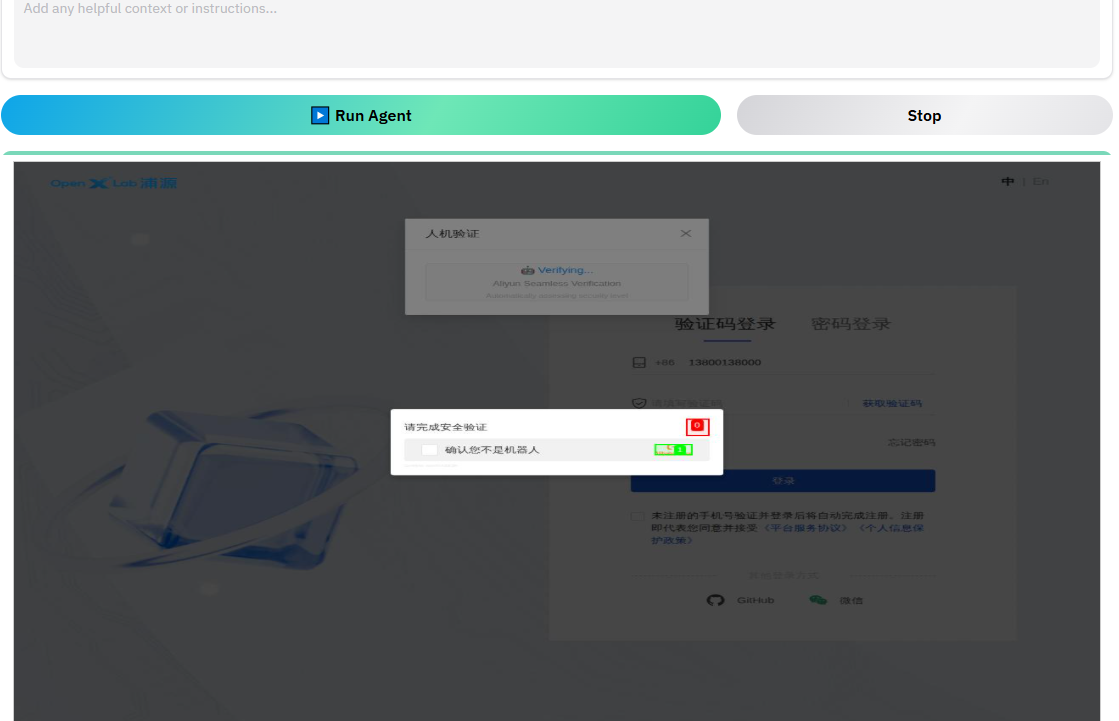
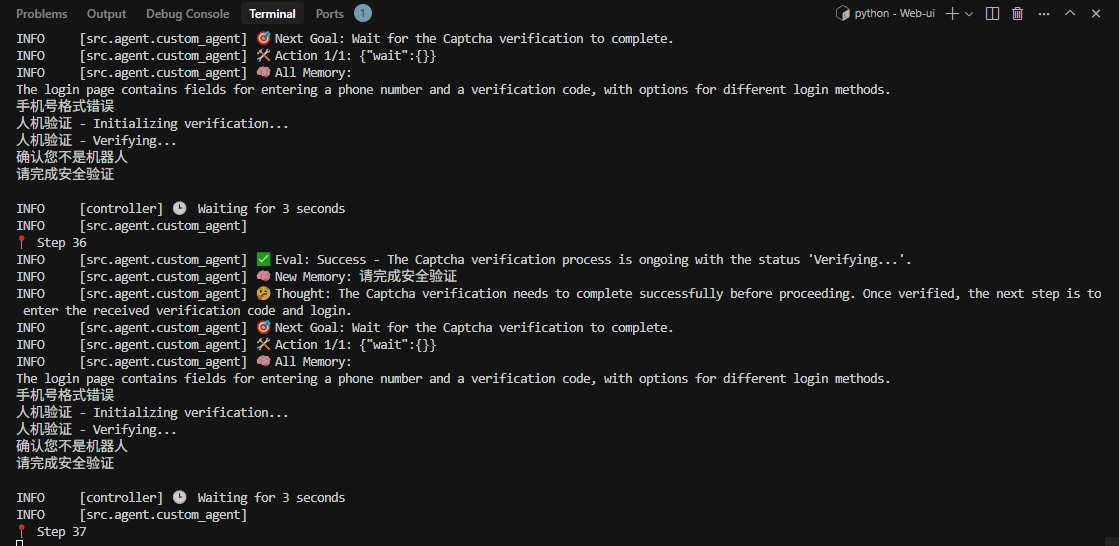
再次执行后没有出现
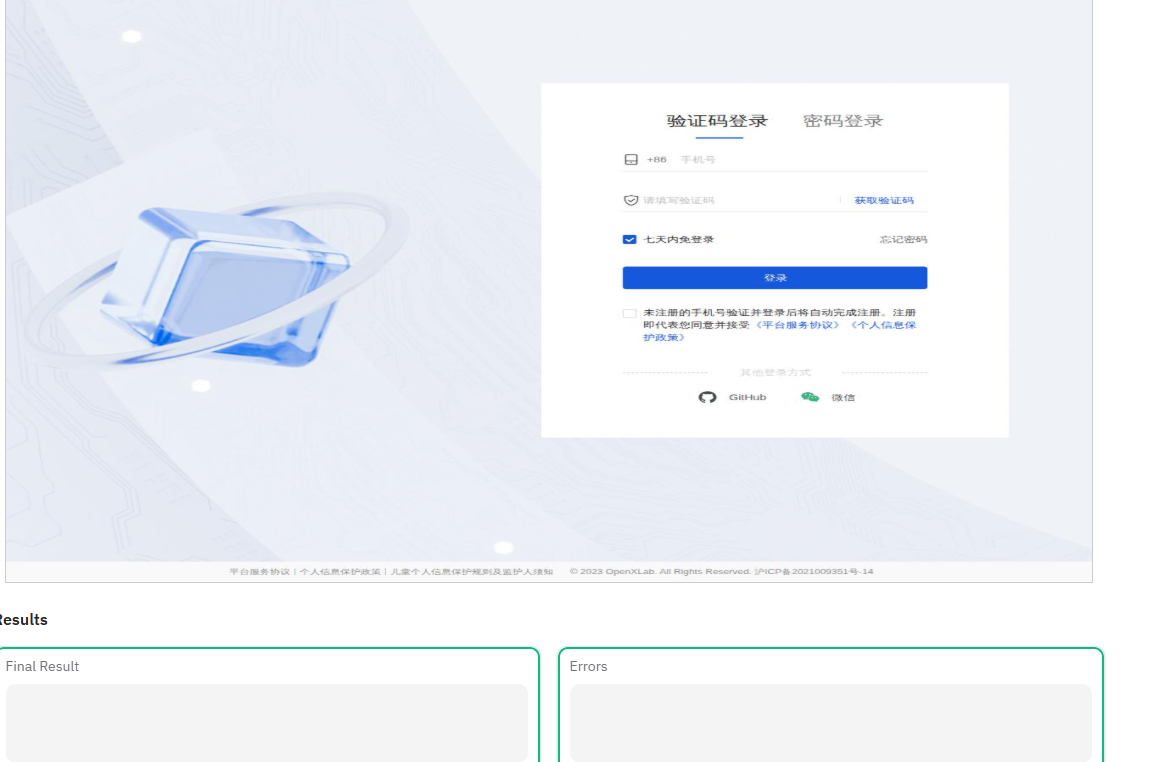
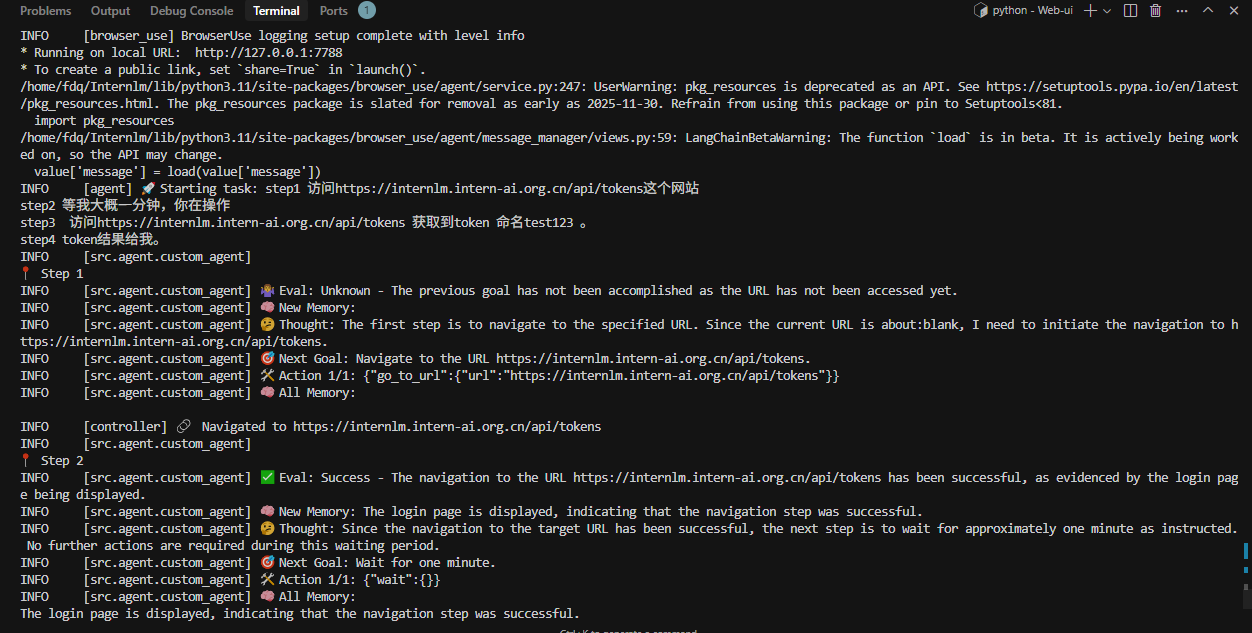
5. 总结
本文档从基础的环境配置开始,详细介绍了如何使用 InternLM API(兼容 OpenAI SDK)进行纯文本和图文多模态对话。同时,我们还探索了如何配置和使用 Browser-Use 工具,让大模型能够与网页交互,完成更高级的智能体任务。
更多推荐


 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)