
【大模型应用开发系列(一)】LangChain:构建大模型应用的核心框架
随着ChatGPT、Claude等大语言模型的技术突破,我们正在经历一场AI应用开发的范式革命。然而,从"能够对话"到"构建生产级AI应用"之间,存在着巨大的工程鸿沟。本系列将以LangChain框架为载体,深度剖析并实现大模型应用开发的热点项目——Rag / Agent / LangGraph工作流编排,适合所有对大模型应用感兴趣的开发者。
开篇语:大模型应用开发的技术栈革命
随着ChatGPT、Claude等大语言模型的技术突破,我们正在经历一场AI应用开发的范式革命。然而,从"能够对话"到"构建生产级AI应用"之间,存在着巨大的工程鸿沟。
想象一下这样的场景:你需要为公司构建一个智能客服系统,它不仅要能回答用户问题,还要能查询订单信息、调用支付接口、记住用户的历史对话。传统的API调用方式让你陷入了复杂的状态管理、提示词拼接和错误处理的泥潭中。每增加一个功能,代码就变得更加混乱和难以维护。
这正是大模型应用开发面临的核心挑战:
提示词管理混乱:硬编码的提示词散布在各处,版本控制困难多轮对话状态维护:手动管理对话历史,内存爆炸问题频发外部工具集成复杂:每个API调用都需要单独处理,错误处理逻辑重复缺乏标准化开发模式:团队成员各自为政,代码质量参差不齐
LangChain的出现,正是为了解决这些痛点。它不仅仅是一个API封装库,而是一个专为构建LLM应用而设计的全栈开发框架,将复杂的AI交互抽象为可组合的标准化组件。
本系列适合所有对大模型应用感兴趣的开发者。
文章目录
一、本系列博客规划
1. 系列定位与目标
这是一套面向大模型应用开发者的实战指南,从 Langchain 这个大模型应用开发的基础框架出发,以当前最主流的几个 AI 应用开发的热点项目( Rag / Agent / Langraph工作流编排 )出发,实现从理论到到生产级项目的完整大模型应用岗技术栈覆盖。
2. 五篇博客完整规划
📖 第1篇:LangChain基础 - 构建大模型应用的核心框架(本篇)
目标读者:刚接触LLM应用开发的工程师
技能收益:掌握LangChain核心组件,具备基础AI应用开发能力
求职价值:必备基础技能
📖 第2篇:RAG检索增强生成 - 让大模型拥有专业知识
目标读者:需要构建知识问答系统的开发者
技能收益:精通RAG架构,能设计高质量的知识问答系统
求职价值:80%的AI应用都涉及RAG
📖 第3篇:Agent智能代理 - 构建能够自主决策的AI系统
目标读者:希望构建复杂AI应用的高级开发者
技能收益:掌握Agent架构,具备复杂AI系统设计能力
求职价值:前沿技术,加分项
📖 第4篇:LangGraph工作流编排 - 复杂AI应用的状态管理
目标读者:需要构建复杂业务流程的架构师
技能收益:精通复杂工作流设计,具备企业级AI系统架构能力
求职价值:进阶必备技能
📖 第5篇:生产部署实战 - 从原型到可扩展的企业级应用
目标读者:负责部署和运维的工程师
技能收益:掌握AI应用生产部署,具备全栈AI应用开发能力
求职价值:决定能否胜任实际工作
二、LangChain是什么?为什么选择它?
1. 大模型应用开发的痛点分析
在深入LangChain之前,让我们先分析传统大模型应用开发面临的核心挑战。这些挑战并非技术层面的简单问题,而是涉及到开发范式、架构设计和工程实践的根本性困难。
1.痛点一:提示词管理混乱
在传统开发方式中,提示词往往硬编码散布在各个代码片段中。这带来了版本控制困难、缺乏模板化复用机制,以及A/B测试复杂等问题。当需要批量调整提示词风格时,开发者需要逐个搜索修改,既耗时又容易出错。
# 散落在各处的硬编码提示词
def analyze_sentiment(text):
prompt = f"请分析以下文本的情感倾向,回答正面、负面或中性:{text}"
return openai.chat.completions.create(...)
def summarize_text(text):
prompt = f"请用一段话总结以下内容:{text}"
return openai.chat.completions.create(...)
def translate_text(text, target_lang):
prompt = f"请将以下文本翻译成{target_lang}:{text}"
return openai.chat.completions.create(...)
面临的挑战:
1.提示词散布在代码各处,难以统一管理
2.版本控制困难,无法跟踪提示词的演变
3.缺乏模板化,重复代码多
4.难以进行A/B测试和效果优化
2.痛点二:多轮对话状态维护困难
AI对话需要维护长期的、上下文相关的状态信息。随着对话轮次增加,完整历史导致token成本快速增长和处理时间延长。更复杂的是多用户并发场景下的状态同步,以及个性化上下文的维护,都需要精心设计的架构支持。
# 手动管理对话状态,容易出错
class ChatSession:
def __init__(self):
self.messages = []
self.max_history = 10 # 内存限制
def chat(self, user_input):
# 手动构造消息历史
self.messages.append({"role": "user", "content": user_input})
# 手动处理历史长度限制
if len(self.messages) > self.max_history:
self.messages = self.messages[-self.max_history:]
# 手动发送请求
response = openai.chat.completions.create(
messages=self.messages,
model="gpt-3.5-turbo"
)
assistant_message = response.choices[0].message.content
self.messages.append({"role": "assistant", "content": assistant_message})
return assistant_message
面临的挑战:
1.内存爆炸问题:长对话导致token消耗过大
2.状态同步复杂:多用户、多会话的状态管理
3.上下文丢失:重要信息被截断或遗失
4.个性化困难:难以为不同用户维护个性化上下文
3.痛点三:外部工具集成复杂
现代AI应用需要调用各种外部服务来完成复杂任务。传统方式下,工具选择逻辑硬编码、错误处理重复实现、缺乏统一接口规范,导致集成复杂度极高。当需要替换API或添加新功能时,往往需要大量代码修改。
# 工具调用的复杂逻辑
def process_user_query(query):
# 意图识别
if "天气" in query:
return call_weather_api(query)
elif "计算" in query:
return call_calculator(query)
elif "搜索" in query:
return call_search_api(query)
else:
return call_general_chat(query)
def call_weather_api(query):
# 手动解析地址
location = extract_location(query)
# 调用API
weather_data = requests.get(f"weather_api/{location}")
# 手动格式化回复
return format_weather_response(weather_data)
面临的挑战:
1.工具选择逻辑硬编码,难以扩展
2.错误处理逻辑重复,维护困难
3.缺乏统一的工具接口规范
4.无法动态组合多个工具
2.Langchain的解决方案
LangChain通过以下四个核心设计理念,系统性地解决了传统大模型应用开发的痛点:
1. 组件化架构设计
LangChain最核心的创新在于将复杂的AI交互过程分解为标准化、可组合的组件。这种设计借鉴了现代软件工程中的微服务架构思想,但专门针对AI应用的特殊需求进行了优化。
# LangChain方式:组件化清晰分离
from langchain import OpenAI, ConversationChain, PromptTemplate
from langchain.memory import ConversationSummaryMemory
# 1. 模型层:统一的LLM接口
llm = OpenAI(temperature=0.7, max_tokens=200)
# 2. 提示词层:模板化管理
prompt = PromptTemplate(
template="""你是一个专业的AI助手,具备以下特质:
- 友善且有耐心
- 逻辑思维清晰
- 能够理解上下文并保持连贯
对话历史:
{history}
用户输入:{input}
助手回复:""",
input_variables=["history", "input"]
)
# 3. 记忆层:自动化状态管理
memory = ConversationSummaryMemory(
llm=llm,
max_token_limit=500, # 超过500token自动摘要
return_messages=False
)
# 4. 组合层:将所有组件连接
conversation = ConversationChain(
llm=llm,
prompt=prompt,
memory=memory,
verbose=True # 显示内部处理过程
)
# 使用:简洁的一行调用
def langchain_chat(user_input):
return conversation.predict(input=user_input)
这样的设计使得每个组件专注于特定功能,每个组件都可以独立替换,新功能通过添加组件实现,而非修改现有代码
2. 声明式编程范式
LangChain引入了声明式编程思维,开发者只需要描述"想要什么",而不必详细指定"如何实现"。这种范式转换显著降低了AI应用的开发复杂度。
# 声明式:描述期望的行为
from langchain.agents import initialize_agent, Tool
from langchain.prompts.chat import ChatPromptTemplate
from langchain.memory import ConversationBufferMemory
class DeclarativeCustomerService:
def __init__(self):
# 声明工具能力
self.tools = [
Tool(
name="OrderQuery",
func=self.query_order,
description="查询订单状态、物流信息等订单相关问题"
),
Tool(
name="ProductInfo",
func=self.get_product_info,
description="获取产品功能、参数、使用方法等产品信息"
),
Tool(
name="RefundProcess",
func=self.handle_refund,
description="处理退款、退货、换货等售后服务"
)
]
# 声明对话模板
self.prompt = ChatPromptTemplate.from_messages([
("system", """你是专业的客服代表,具备以下能力:
1. 理解用户情感并给予同理心回应
2. 准确识别用户需求并使用合适的工具
3. 提供清晰、有用的解决方案
当用户提问时,你应该:
- 首先表达理解和关心
- 分析用户需求
- 选择合适的工具获取信息
- 提供完整的解决方案
"""),
("human", "{input}"),
("assistant", "{agent_scratchpad}")
])
# 声明记忆策略
self.memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
# 声明智能代理
self.agent = initialize_agent(
tools=self.tools,
llm=OpenAI(temperature=0.7),
agent="chat-conversational-react-description",
memory=self.memory,
prompt=self.prompt,
verbose=True
)
def process_query(self, user_input):
# 声明式调用:框架自动处理所有细节
return self.agent.run(user_input)
def query_order(self, order_info):
# 具体的业务逻辑实现
pass
def get_product_info(self, product_query):
# 具体的业务逻辑实现
pass
def handle_refund(self, refund_request):
# 具体的业务逻辑实现
pass
这样的设计是十分贴近开发者的,开发者无需关心内部实现细节,无需担心会话状态;同时,代码直接反映业务需求;当需求发生变化时,开发者只需要关注声明,而不是关注其内部实现。
3.丰富的生态系统
LangChain构建了一个开放、可扩展的生态系统,这使得开发者可以轻松集成各种外部服务和工具,而不必从零开始构建集成代码。比如,提供了在线大模型和本地大模型的系列接口;比如,提供了Chroma, Pinecone, FAISS, Weaviate等主流向量数据库的系列接口。
4. 生产级特性支持
LangChain不仅适用于快速原型开发,更重要的是它内置了许多生产级应用必需的特性。
比如,BaseCallbackHandler提供了大模型调用链路的监控,方便查看每个部分的耗时和报错细节。
通过这些解决方案,LangChain将复杂的大模型应用开发转变为组件化、声明式、生态化的现代开发体验。开发者可以专注于业务逻辑的实现,而不必重复造轮子或处理底层的技术细节。
这种设计哲学使得LangChain不仅适用于快速原型开发,更是构建生产级AI应用的理想选择。在接下来的部分中,我们将深入探讨LangChain与传统开发框架的具体差异。
3.AI应用开发与传统开发的区别
要深入理解LangChain的价值,我们需要从更深层次比较AI应用开发与传统软件开发的根本性差异。
1. 确定性 vs 概率性的编程思维
传统软件开发处理的是确定性的逻辑:给定相同的输入,函数总是产生相同的输出。这种确定性使得传统的调试、测试、监控技术都有了坚实的基础。
但AI应用天然具有概率性特征。即使使用相同的提示词,LLM也可能产生不同的输出。这种概率性不是缺陷,而是AI系统的本质特征。它带来了创造性和灵活性,但也对开发框架提出了全新的要求。
LangChain专门为这种概率性设计了对应的机制:输出解析器处理格式变化,重试机制应对偶发错误,置信度评估支持质量控制。这些机制在传统框架中是不存在的,因为传统应用不需要应对这种内在的不确定性。
2. 线性流程 vs 动态推理的架构差异
传统Web应用通常遵循相对固定的处理流程:请求路由、数据验证、业务逻辑处理、结果返回。即使有条件分支,这些分支通常也是基于数据内容的静态判断。
AI应用的处理流程则具有强烈的动态特征。Agent可能需要根据问题的复杂程度决定是否调用外部工具,根据初步结果决定是否需要进一步的信息收集,根据用户反馈动态调整处理策略。这种动态性要求框架具备强大的流程编排能力。
LangChain的Chain和Agent机制专门为这种动态流程设计。Chain提供了结构化的流程编排能力,Agent提供了智能的决策机制。这些抽象在传统框架中是找不到对应物的,因为传统应用的控制流程相对简单和固定。
3. 状态管理的维度差异
传统Web应用的状态管理主要涉及用户会话和业务数据。这些状态的结构相对固定,生命周期也比较清晰。
AI应用的状态管理则要复杂得多。除了基本的对话历史,系统还需要维护实体记忆(记住对话中提到的人物、地点、事件),任务上下文(当前正在执行的任务的进度和状态),用户偏好(从交互中学习到的用户特性),工具状态(各种外部工具的连接状态和缓存数据)。
更重要的是,这些状态之间存在复杂的关联关系,状态的更新策略也需要智能化。LangChain的Memory系统为这种多维度状态管理提供了标准化的解决方案,支持从简单缓存到智能摘要的多种策略,可以根据应用需求灵活选择。
4. 错误处理的复杂度提升
传统应用的错误主要来自系统层面:网络错误、数据库超时、格式验证失败等。这些错误的类型相对有限,处理策略也比较成熟。
AI应用除了要面对系统层面的错误,还要处理语义层面的问题:LLM产生的幻觉、输出格式不符合预期、推理逻辑错误等。这类错误的检测和修复需要更智能的机制。
LangChain提供了多层次的错误处理能力:系统层面的重试机制、语义层面的输出验证、应用层面的降级策略。这种综合性的容错能力是传统框架所不具备的,也是AI应用走向生产环境的必要条件。
三、LangChain核心组件
理解了LangChain的设计理念后,让我们深入探讨其核心组件。LangChain将复杂的AI应用抽象为五个核心组件:Models、Prompts、Chains、Agents和Memory。这种分层设计使得开发者可以像搭积木一样构建AI应用。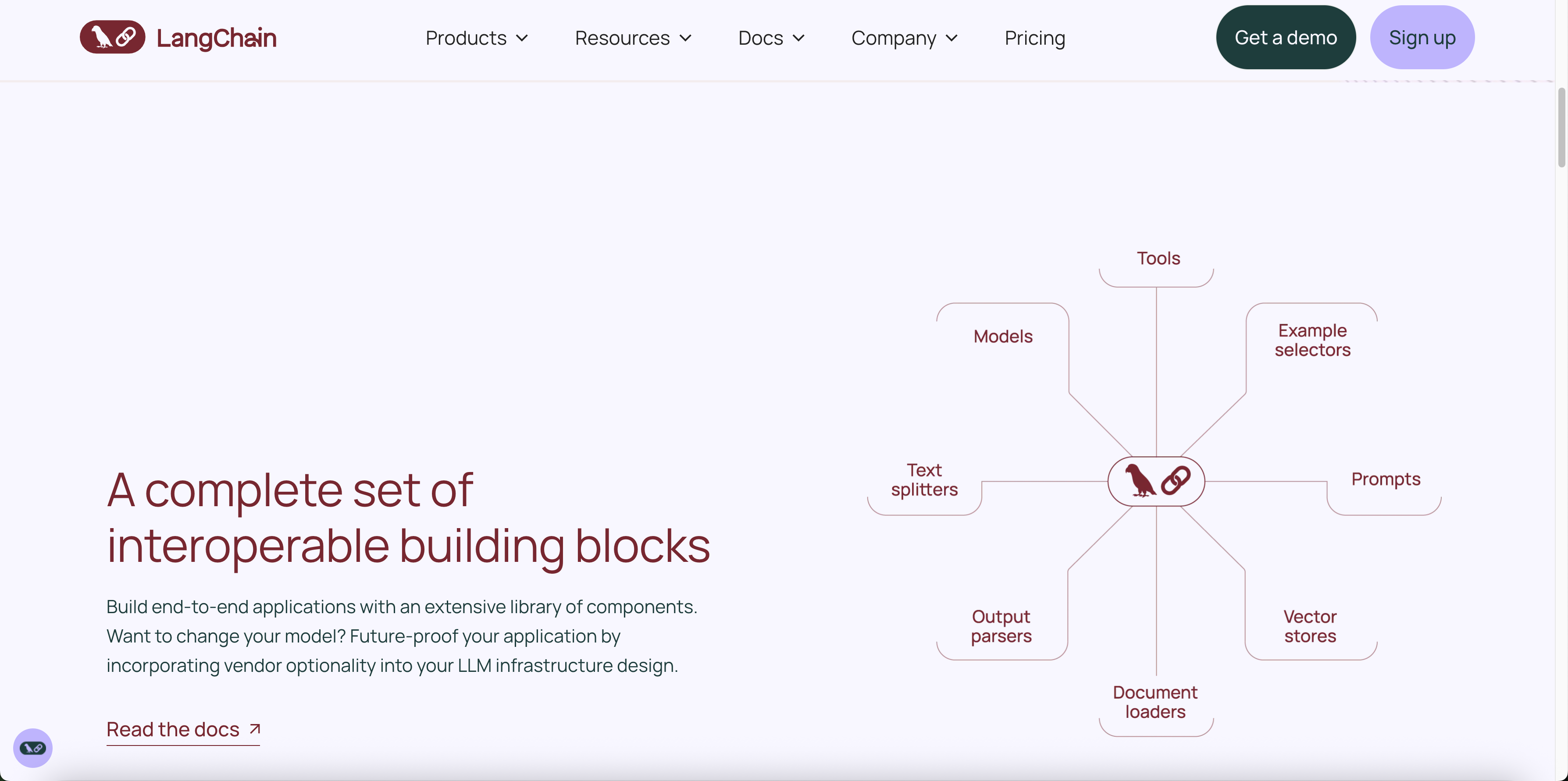
1. Models:统一的模型抽象层
Models层是LangChain的基础设施,它为不同厂商的语言模型提供了统一的接口。这种抽象使得开发者可以轻松切换模型而无需重写业务逻辑。
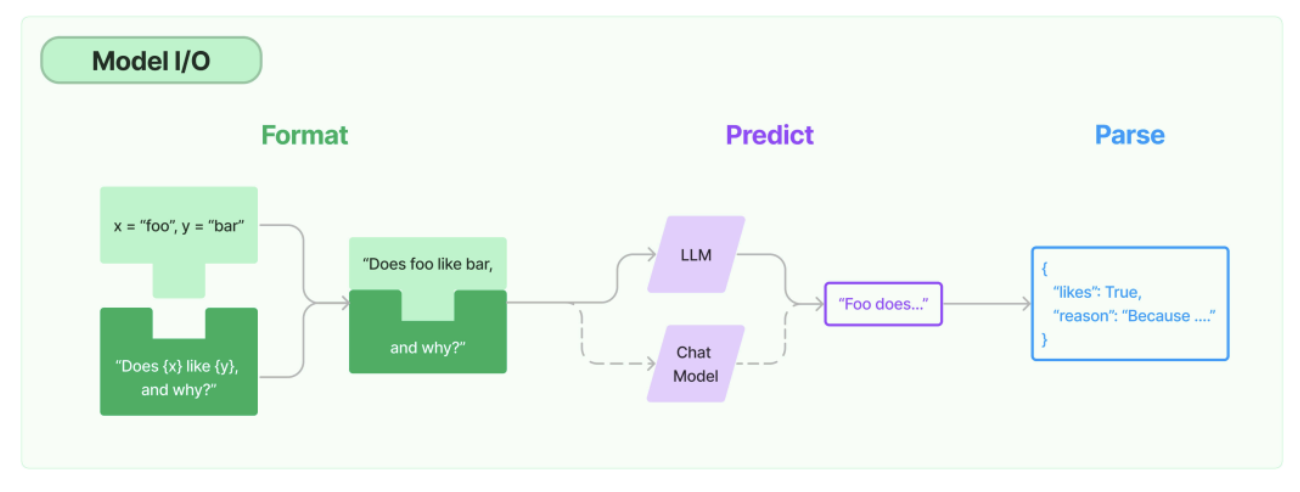
1.1 LLMs vs Chat Models:理解两种模型范式
LangChain区分了两种基本的模型交互范式,这种区分反映了语言模型技术发展的两个重要阶段:
LLMs (大语言模型):
交互模式:文本输入 → 文本输出
适用场景:文本补全、单次生成任务
典型代表:GPT-3、Llama基础版
from langchain.llms import OpenAI
# 基础LLM的使用方式
llm = OpenAI(
model_name="text-davinci-003",
temperature=0.7, # 控制创造性,0=确定性,1=高创造性
max_tokens=500, # 输出长度限制
top_p=0.95, # 核采样,控制词汇选择范围
frequency_penalty=0.0, # 频率惩罚,减少重复
presence_penalty=0.0 # 存在惩罚,鼓励新颖性
)
# 单次文本生成
prompt = "请解释什么是量子计算,并举例说明其应用场景:"
response = llm(prompt)
print(f"LLM回复:{response}")
# 批量处理多个提示词
prompts = [
"总结AI的发展历程",
"解释区块链的工作原理",
"分析云计算的未来趋势"
]
responses = llm.generate(prompts)
for i, response in enumerate(responses.generations):
print(f"问题{i+1}:{prompts[i]}")
print(f"回答:{response[0].text}\n")
Chat Models (对话模型):
交互模式:消息列表输入 → 消息对象输出
适用场景:多轮对话、角色扮演、系统级指令
典型代表:GPT-4、Claude、ChatGPT
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage, AIMessage
# 对话模型的使用方式
chat = ChatOpenAI(
model_name="gpt-4",
temperature=0.3,
max_tokens=800
)
# 构建多角色对话
messages = [
SystemMessage(content="""你是一位资深的Python导师,具备以下特质:
- 耐心细致,善于用简单的语言解释复杂概念
- 会提供实用的代码示例
- 能够根据学生水平调整讲解深度
- 鼓励学生动手实践"""),
HumanMessage(content="我刚开始学编程,请解释什么是函数,为什么要使用函数?"),
AIMessage(content="""函数是编程中的基本概念,就像你日常生活中使用的工具一样...
[这里是AI的回复内容]"""),
HumanMessage(content="能给我一个具体的函数例子吗?")
]
# 获取AI回复
response = chat(messages)
print(f"AI导师回复:{response.content}")
# 流式获取回复(适合长回复)
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
streaming_chat = ChatOpenAI(
model_name="gpt-4",
streaming=True,
callbacks=[StreamingStdOutCallbackHandler()],
temperature=0.3
)
# 这将实时输出AI的回复过程
streaming_response = streaming_chat(messages)
1.2 多厂商统一接口:真正的模型无关开发
在AI技术快速发展的时代,模型厂商的竞争异常激烈。今天表现最好的模型,可能在几个月后就被新的技术超越。如果我们的应用代码与特定模型深度绑定,那么每次技术升级都意味着大量的重构工作。LangChain的统一接口解决了这个问题,它让模型切换变得像更换数据库驱动一样简单。
更深层的价值在于,统一接口使得模型比较和优化变得可行。在生产环境中,我们经常需要在成本、性能、准确性之间找到最佳平衡点。有了统一接口,我们可以轻松地进行A/B测试,对比不同模型在特定任务上的表现。
# 统一接口支持多种模型
from langchain.llms import OpenAI, HuggingFacePipeline
from langchain.chat_models import ChatOpenAI, ChatAnthropic
class ModelManager:
"""统一的模型管理器"""
def __init__(self, model_type="openai"):
self.models = self._initialize_models()
self.current_model = self.models[model_type]
def _initialize_models(self):
"""初始化所有可用模型"""
return {
"openai": ChatOpenAI(model_name="gpt-4", temperature=0.7),
"anthropic": ChatAnthropic(model="claude-3-sonnet-20240229"),
"local_llama": HuggingFacePipeline.from_model_id(
model_id="meta-llama/Llama-2-7b-chat-hf",
task="text-generation",
model_kwargs={"temperature": 0.7, "max_length": 1000}
)
}
def switch_model(self, model_type):
"""动态切换模型"""
if model_type in self.models:
self.current_model = self.models[model_type]
print(f"已切换到模型:{model_type}")
else:
raise ValueError(f"不支持的模型类型:{model_type}")
def generate_response(self, prompt):
"""统一的响应生成接口"""
if hasattr(self.current_model, 'predict'):
return self.current_model.predict(prompt)
else:
return self.current_model(prompt)
def compare_models(self, prompt, model_types=None):
"""对比不同模型的回复质量"""
if model_types is None:
model_types = list(self.models.keys())
results = {}
for model_type in model_types:
try:
self.switch_model(model_type)
response = self.generate_response(prompt)
results[model_type] = response
print(f"\n=== {model_type} 回复 ===")
print(response[:200] + "..." if len(response) > 200 else response)
except Exception as e:
results[model_type] = f"错误:{str(e)}"
return results
# 实际使用示例
model_manager = ModelManager()
# 对比不同模型的回答质量
test_prompt = "请解释深度学习和机器学习的区别,并给出实际应用场景"
comparison_results = model_manager.compare_models(test_prompt, ["openai", "anthropic"])
1.3 模型配置优化:性能与成本的平衡
在实际的生产环境中,模型配置不仅仅是技术选择,更是业务策略的体现。不同的应用场景对响应速度、准确性、成本控制有着不同的要求。LangChain提供了丰富的配置选项,让开发者可以精确控制模型行为,实现业务目标和技术实现的最佳平衡。
温度参数可能是最重要但也最容易被误解的配置。低温度(0-0.3)适合需要一致性和准确性的任务,如客服回复、文档总结;中等温度(0.4-0.7)适合平衡创造性和准确性的任务,如内容创作、教育解答;高温度(0.8-1.0)适合需要高度创造性的任务,如创意写作、头脑风暴。
from langchain.llms import OpenAI
from langchain.callbacks import get_openai_callback
import time
class OptimizedModelConfig:
"""优化的模型配置管理"""
@staticmethod
def create_fast_model():
"""快速响应模型:低延迟,标准质量"""
return OpenAI(
model_name="gpt-3.5-turbo-instruct",
temperature=0.1, # 低创造性,提高一致性
max_tokens=300, # 限制输出长度,降低成本
top_p=0.8, # 较严格的词汇选择
request_timeout=10, # 较短的超时时间
max_retries=2 # 减少重试次数
)
@staticmethod
def create_quality_model():
"""高质量模型:更好的回答质量"""
return OpenAI(
model_name="gpt-4",
temperature=0.7, # 平衡创造性和准确性
max_tokens=1000, # 允许更长的回答
top_p=0.95, # 更丰富的词汇选择
frequency_penalty=0.1, # 轻度减少重复
presence_penalty=0.1, # 鼓励引入新概念
request_timeout=30 # 更长的处理时间
)
@staticmethod
def create_creative_model():
"""创意模型:高创造性任务"""
return OpenAI(
model_name="gpt-4",
temperature=0.9, # 高创造性
max_tokens=1500, # 更长的创作空间
top_p=1.0, # 最大词汇多样性
frequency_penalty=0.2, # 避免重复表达
presence_penalty=0.3 # 强烈鼓励新颖性
)
# 性能测试和成本分析
def test_model_performance():
"""测试不同配置的性能和成本"""
test_prompt = "请为一家AI创业公司写一份商业计划书的执行摘要"
configs = {
"fast": OptimizedModelConfig.create_fast_model(),
"quality": OptimizedModelConfig.create_quality_model(),
"creative": OptimizedModelConfig.create_creative_model()
}
results = {}
for config_name, model in configs.items():
print(f"\n测试配置:{config_name}")
# 使用回调监控token使用和成本
with get_openai_callback() as cb:
start_time = time.time()
try:
response = model(test_prompt)
end_time = time.time()
results[config_name] = {
"response": response[:100] + "...", # 只显示前100字符
"tokens": cb.total_tokens,
"cost": cb.total_cost,
"time": end_time - start_time,
"success": True
}
print(f"耗时:{results[config_name]['time']:.2f}秒")
print(f"Token数:{results[config_name]['tokens']}")
print(f"成本:${results[config_name]['cost']:.4f}")
except Exception as e:
results[config_name] = {
"error": str(e),
"success": False
}
return results
# 执行性能测试
performance_results = test_model_performance()
2. Prompts:提示词工程的工业化革命
提示词工程是大模型应用开发的核心技能,但传统的硬编码方式存在诸多问题:版本控制困难、复用性差、A/B测试复杂、团队协作效率低。LangChain的Prompts组件将提示词管理从手工作坊式的个人技艺提升为工业化的标准流程。
这种转变的意义深远。在个人项目中,我们可能只需要几十个提示词,手动管理尚可应付。但在企业级应用中,提示词的数量可能达到数百甚至数千个,涉及多个业务场景、多种语言、多个版本。没有系统化的管理机制,提示词很快就会成为项目的技术债务。
2.1 PromptTemplate:从硬编码到模板化
PromptTemplate的核心价值不仅仅是参数化,更重要的是它建立了提示词开发的标准化流程。通过模板化,我们可以将提示词的结构和内容分离,实现提示词的版本化管理、模块化复用和规模化测试。
在实际项目中,一个好的提示词模板通常包含几个关键要素:角色设定(告诉AI它是谁)、任务描述(明确要做什么)、输入格式(数据如何组织)、输出要求(期望的回复格式)、约束条件(不能做什么)。这种结构化的设计使得提示词的效果更加可控和可预测。
from langchain import PromptTemplate
from langchain.llms import OpenAI
class EnterprisePromptManager:
"""企业级提示词管理系统"""
def __init__(self):
# 建立提示词模板库,按业务领域分类
self.template_library = {
"customer_service": self._build_customer_service_templates(),
"content_marketing": self._build_content_marketing_templates(),
"data_analysis": self._build_data_analysis_templates(),
"legal_compliance": self._build_legal_compliance_templates()
}
# 提示词版本管理
self.version_history = {}
def _build_customer_service_templates(self):
"""构建客服场景的提示词模板"""
return {
"complaint_handling": PromptTemplate(
input_variables=["customer_name", "issue_description", "order_id", "customer_tier"],
template="""
你是一位专业的客户服务代表,具备以下特质:
- 同理心强,能够理解客户的困扰和不满
- 解决问题的能力强,善于找到双赢的解决方案
- 沟通技巧优秀,能够化解紧张气氛
- 对公司政策了如指掌,能够灵活运用
客户信息:
- 姓名:{customer_name}
- 等级:{customer_tier}
- 订单号:{order_id}
客户投诉内容:
{issue_description}
请按以下步骤处理投诉:
1. 首先表达对客户遭遇的同情和理解
2. 分析问题的根本原因
3. 提供具体的解决方案,如有必要可以提供补偿
4. 预防类似问题再次发生的建议
5. 表达对客户继续信任公司的感谢
回复格式:
【表达同情】
【问题分析】
【解决方案】
【预防措施】
【感谢客户】
"""),
"product_recommendation": PromptTemplate(
input_variables=["customer_profile", "browsing_history", "budget_range", "specific_needs"],
template="""
你是一位资深的产品顾问,擅长根据客户需求推荐最适合的产品。
客户画像:{customer_profile}
浏览记录:{browsing_history}
预算范围:{budget_range}
特殊需求:{specific_needs}
推荐原则:
1. 以客户真实需求为出发点,不推销不需要的产品
2. 综合考虑性价比,为客户省钱
3. 推荐理由要具体明确,让客户信服
4. 提供多个选择,让客户有比较的余地
请提供推荐方案:
【推荐产品1】
产品名称:
推荐理由:
价格区间:
适用场景:
【推荐产品2】
(如有必要)
【购买建议】
最优选择:
购买时机:
注意事项:
""")
}
def _build_content_marketing_templates(self):
"""构建内容营销的提示词模板"""
return {
"social_media_post": PromptTemplate(
input_variables=["brand_voice", "target_audience", "campaign_goal", "content_topic", "platform"],
template="""
你是一位创意营销专家,专精于{platform}平台的内容创作。
品牌调性:{brand_voice}
目标受众:{target_audience}
营销目标:{campaign_goal}
内容主题:{content_topic}
创作要求:
1. 符合{platform}平台的用户习惯和内容格式
2. 体现品牌调性,保持品牌一致性
3. 内容要有价值,能够引起目标受众的共鸣
4. 包含适当的互动元素,提高参与度
5. 如需要,添加相关的话题标签
请创作内容:
【主要内容】
(200-300字的核心内容)
【互动元素】
(提问、投票、挑战等)
【话题标签】
(3-5个相关标签)
【发布建议】
最佳发布时间:
预期效果:
"""),
"email_campaign": PromptTemplate(
input_variables=["subscriber_segment", "campaign_objective", "product_info", "special_offer"],
template="""
你是邮件营销专家,专门为{subscriber_segment}用户群体设计高转化的邮件内容。
营销目标:{campaign_objective}
产品信息:{product_info}
特别优惠:{special_offer}
邮件设计原则:
1. 主题行要吸引注意力,提高打开率
2. 开头要快速建立价值,避免用户流失
3. 内容结构清晰,重点突出
4. 行动召唤明确具体
5. 个性化程度高,让用户感受到被重视
请设计邮件:
【主题行】
(吸引人的主题,控制在50字以内)
【邮件正文】
开头:
主体内容:
结尾:
【行动召唤】
(明确的下一步指引)
""")
}
def get_optimized_prompt(self, domain, template_name, **kwargs):
"""获取优化的提示词"""
if domain not in self.template_library:
raise ValueError(f"不支持的业务域:{domain}")
if template_name not in self.template_library[domain]:
raise ValueError(f"在{domain}域中找不到模板:{template_name}")
template = self.template_library[domain][template_name]
# 验证必要参数
missing_vars = set(template.input_variables) - set(kwargs.keys())
if missing_vars:
raise ValueError(f"缺少必要参数:{missing_vars}")
# 记录使用历史,用于后续优化
usage_key = f"{domain}.{template_name}"
if usage_key not in self.version_history:
self.version_history[usage_key] = []
self.version_history[usage_key].append({
"timestamp": time.time(),
"parameters": kwargs
})
return template.format(**kwargs)
# 企业级应用示例
prompt_manager = EnterprisePromptManager()
# 客服投诉处理
complaint_prompt = prompt_manager.get_optimized_prompt(
domain="customer_service",
template_name="complaint_handling",
customer_name="张先生",
customer_tier="VIP",
order_id="ORD-2024-001234",
issue_description="我购买的笔记本电脑在收到后第二天就出现了屏幕闪烁的问题,严重影响使用。我是你们的老客户,对这次的产品质量非常失望。"
)
print("=== 客服投诉处理提示词 ===")
print(complaint_prompt)
2.2 Few-Shot Learning:通过示例驱动的AI学习
Few-Shot Learning是人工智能领域的一个重要概念,它模拟了人类学习的方式:通过有限的几个示例就能理解并执行新任务。在LangChain中,Few-Shot Learning被优雅地集成到提示词管理系统中,使得AI的行为可以通过精心设计的示例来引导和塑造。
Few-Shot Learning的真正价值在于它能够显著提高AI在特定任务上的表现,而无需重新训练模型。这对于企业应用特别重要,因为很多业务场景都有特定的规范和标准,通过Few-Shot示例,我们可以让通用的大模型快速适应特定的业务需求。
选择优质的Few-Shot示例需要遵循几个原则:示例要有代表性,覆盖主要的变化情况;示例之间要有适当的多样性,避免过于相似;示例要足够简洁,突出关键的输入输出模式;示例要符合期望的质量标准,因为AI会模仿示例的风格和质量。
from langchain import FewShotPromptTemplate, PromptTemplate
class IntelligentFewShotBuilder:
"""智能Few-Shot示例构建器"""
def __init__(self):
# 构建不同领域的示例库
self.example_databases = {
"sentiment_analysis": [
{"input": "这家饭店的菜品质量很不错,服务也很周到,就是价格稍微贵了一点。",
"output": "正面", "confidence": "0.7",
"explanation": "虽然提到价格贵,但对菜品和服务的正面评价更为突出"},
{"input": "快递速度太慢,包装也不好,商品有破损,很失望。",
"output": "负面", "confidence": "0.9",
"explanation": "涉及多个负面问题:速度慢、包装差、商品损坏"},
{"input": "这个产品功能还可以,价格也算合理,总体来说符合预期。",
"output": "中性", "confidence": "0.8",
"explanation": "评价均衡,既不特别褒奖也不明显批评"}
],
"email_classification": [
{"input": "紧急:服务器宕机,请立即处理!",
"output": "urgent_technical", "priority": "high",
"explanation": "包含紧急关键词且涉及技术故障"},
{"input": "你好,请问贵公司的产品价格表能发一份吗?谢谢。",
"output": "sales_inquiry", "priority": "medium",
"explanation": "标准的销售咨询,语气礼貌正式"},
{"input": "老板,明天的会议我不能参加了,需要请假。",
"output": "internal_admin", "priority": "low",
"explanation": "内部行政事务,非紧急"}
],
"code_review": [
{"input": "def process_data(data):\n result = []\n for item in data:\n if item > 0:\n result.append(item * 2)\n return result",
"output": "建议改进:\n1. 添加类型注解提高代码可读性\n2. 可考虑使用列表推导式提高效率\n3. 添加输入验证\n改进版本:\ndef process_data(data: List[int]) -> List[int]:\n if not data:\n return []\n return [item * 2 for item in data if item > 0]",
"quality_score": "6/10"}
]
}
# 构建动态示例选择器
self.example_selectors = self._build_example_selectors()
def _build_example_selectors(self):
"""构建示例选择器,根据输入动态选择最相关的示例"""
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
def semantic_similarity_selector(input_text, examples, max_examples=3):
"""基于语义相似度选择示例"""
if not examples:
return []
# 提取所有示例的输入文本
example_inputs = [ex["input"] for ex in examples]
all_texts = example_inputs + [input_text]
# 计算TF-IDF向量
try:
vectorizer = TfidfVectorizer(stop_words='english', max_features=1000)
tfidf_matrix = vectorizer.fit_transform(all_texts)
# 计算相似度
input_vector = tfidf_matrix[-1]
example_vectors = tfidf_matrix[:-1]
similarities = cosine_similarity(input_vector, example_vectors).flatten()
# 选择最相似的示例
best_indices = np.argsort(similarities)[-max_examples:][::-1]
selected_examples = [examples[i] for i in best_indices if similarities[i] > 0.1]
return selected_examples
except:
# 如果向量化失败,返回前几个示例
return examples[:max_examples]
return {"semantic": semantic_similarity_selector}
def create_adaptive_few_shot_prompt(self, task_type, instruction, max_examples=3):
"""创建自适应的Few-Shot提示词"""
if task_type not in self.example_databases:
raise ValueError(f"不支持的任务类型:{task_type}")
examples = self.example_databases[task_type]
# 根据任务类型设计示例格式
if task_type == "sentiment_analysis":
example_template = PromptTemplate(
input_variables=["input", "output", "confidence", "explanation"],
template="文本:{input}\n情感:{output} (置信度: {confidence})\n分析:{explanation}\n"
)
prefix = f"{instruction}\n\n以下是一些示例:\n"
suffix = "\n文本:{input}\n情感:"
elif task_type == "email_classification":
example_template = PromptTemplate(
input_variables=["input", "output", "priority", "explanation"],
template="邮件:{input}\n类型:{output}\n优先级:{priority}\n理由:{explanation}\n"
)
prefix = f"{instruction}\n\n参考示例:\n"
suffix = "\n邮件:{input}\n类型:"
elif task_type == "code_review":
example_template = PromptTemplate(
input_variables=["input", "output", "quality_score"],
template="代码:\n{input}\n\n评审意见:\n{output}\n质量评分:{quality_score}\n"
)
prefix = f"{instruction}\n\n示例评审:\n"
suffix = "\n代码:\n{input}\n\n评审意见:\n"
# 创建自适应选择的Few-Shot模板
class AdaptiveFewShotPrompt:
def __init__(self, examples, example_template, prefix, suffix, selector):
self.examples = examples
self.example_template = example_template
self.prefix = prefix
self.suffix = suffix
self.selector = selector
def format(self, **kwargs):
input_text = kwargs.get("input", "")
# 动态选择最相关的示例
selected_examples = self.selector(input_text, self.examples, max_examples)
# 构建Few-Shot模板
few_shot_prompt = FewShotPromptTemplate(
examples=selected_examples,
example_prompt=self.example_template,
prefix=self.prefix,
suffix=self.suffix,
input_variables=["input"]
)
return few_shot_prompt.format(**kwargs)
return AdaptiveFewShotPrompt(
examples=examples,
example_template=example_template,
prefix=prefix,
suffix=suffix,
selector=self.example_selectors["semantic"]
)
def evaluate_few_shot_effectiveness(self, task_type, test_cases):
"""评估Few-Shot示例的有效性"""
results = {
"with_examples": [],
"without_examples": [],
"improvement_metrics": {}
}
# 这里应该实际调用LLM进行测试
# 为了演示,我们模拟一个评估过程
print(f"=== {task_type} Few-Shot效果评估 ===")
print(f"测试案例数:{len(test_cases)}")
for i, test_case in enumerate(test_cases):
print(f"测试案例 {i+1}: {test_case['input'][:50]}...")
# 模拟有示例和无示例的性能差异
accuracy_with_examples = 0.85 + (i % 3) * 0.05 # 模拟85%-95%的准确率
accuracy_without_examples = 0.65 + (i % 3) * 0.05 # 模拟65%-75%的准确率
results["with_examples"].append(accuracy_with_examples)
results["without_examples"].append(accuracy_without_examples)
# 计算改进指标
avg_with = sum(results["with_examples"]) / len(results["with_examples"])
avg_without = sum(results["without_examples"]) / len(results["without_examples"])
results["improvement_metrics"] = {
"average_accuracy_with_examples": avg_with,
"average_accuracy_without_examples": avg_without,
"improvement_percentage": ((avg_with - avg_without) / avg_without) * 100
}
print(f"Few-Shot示例提升效果:{results['improvement_metrics']['improvement_percentage']:.1f}%")
return results
# Few-Shot学习的实际应用
few_shot_builder = IntelligentFewShotBuilder()
# 创建情感分析的Few-Shot提示词
sentiment_prompt = few_shot_builder.create_adaptive_few_shot_prompt(
task_type="sentiment_analysis",
instruction="请分析文本的情感倾向,并提供置信度和简要分析。",
max_examples=3
)
# 测试自适应示例选择
test_input = "这个手机的摄像头效果很棒,但是电池续航时间太短了,总体来说还是值得购买的。"
formatted_prompt = sentiment_prompt.format(input=test_input)
print("=== 自适应Few-Shot提示词 ===")
print(formatted_prompt)
print("\n" + "="*50)
# 评估Few-Shot效果
test_cases = [
{"input": "产品质量很好,但是价格有点贵", "expected": "中性偏正面"},
{"input": "完全不值这个价钱,浪费金钱", "expected": "负面"},
{"input": "非常满意,超出预期", "expected": "正面"}
]
effectiveness_results = few_shot_builder.evaluate_few_shot_effectiveness("sentiment_analysis", test_cases)
通过这样的系统化管理,LangChain将提示词工程从艺术变成了科学,从个人技能变成了团队能力,从一次性工作变成了可持续的工程实践。这种转变对于大模型应用的规模化开发具有重要意义。
3. Chains:构建智能应用的业务流水线
如果说Models是LangChain的引擎,Prompts是燃料,那么Chains就是传动系统——它将各个组件有机地串联在一起,形成完整的业务处理流程。Chains的核心价值在于将复杂的AI任务分解为多个简单的步骤,每个步骤专注于特定的功能,通过合理的编排实现复杂的智能化业务逻辑。
在传统的软件开发中,我们习惯了线性的处理流程:输入验证→业务处理→结果输出。但在AI应用中,处理流程往往更加复杂:需要多轮推理、条件分支、结果验证、错误恢复等。Chains提供了一套标准化的流程编排机制,让开发者可以像搭建乐高积木一样构建复杂的AI应用。
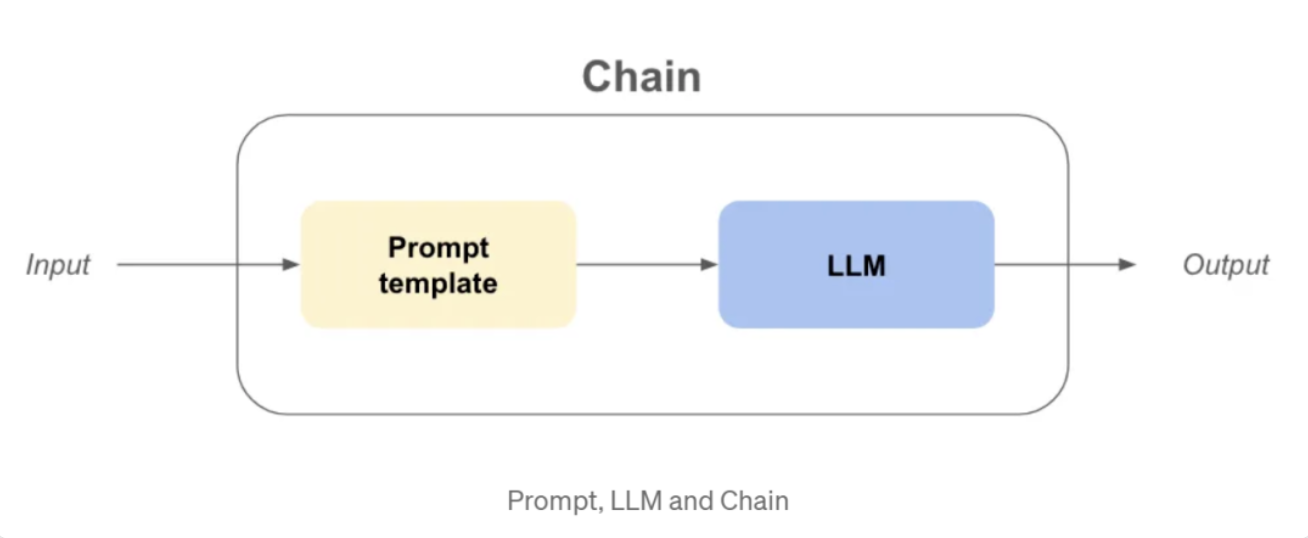
3.1 LLMChain:最基础的构建单元
LLMChain是所有复杂Chain的基础,它封装了"提示词→模型调用→结果解析"这一最基本的AI交互流程。虽然看起来简单,但LLMChain的设计蕴含着深刻的工程思维:它将AI调用过程标准化,提供了统一的错误处理、性能监控和结果验证机制。
在实际应用中,一个设计良好的LLMChain不仅仅是简单的API调用包装,而是包含了输入预处理、输出后处理、异常恢复等完整的处理逻辑。这种设计使得单个链条既可以独立运行,也可以作为更复杂流程的组成部分。
from langchain import LLMChain, PromptTemplate
from langchain.llms import OpenAI
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
import json
import time
from typing import Dict, List, Optional
class BusinessAnalysisResult(BaseModel):
"""业务分析结果的数据模型"""
key_findings: List[str] = Field(description="关键发现点")
recommendations: List[str] = Field(description="行动建议")
risk_assessment: str = Field(description="风险评估")
confidence_score: float = Field(description="分析可信度,0-1之间")
class EnhancedLLMChain:
"""增强版的LLMChain,包含完整的企业级功能"""
def __init__(self, llm, prompt_template, output_parser=None, name="unknown_chain"):
self.llm = llm
self.prompt_template = prompt_template
self.output_parser = output_parser
self.name = name
# 执行统计
self.execution_stats = {
"total_executions": 0,
"successful_executions": 0,
"failed_executions": 0,
"total_execution_time": 0,
"average_response_time": 0
}
# 创建基础链
self.base_chain = LLMChain(
llm=self.llm,
prompt=self.prompt_template,
verbose=True
)
def execute_with_monitoring(self, inputs: Dict) -> Dict:
"""带监控的执行方法"""
start_time = time.time()
self.execution_stats["total_executions"] += 1
try:
# 输入预处理
preprocessed_inputs = self._preprocess_inputs(inputs)
# 执行核心逻辑
raw_output = self.base_chain.run(**preprocessed_inputs)
# 输出后处理
processed_output = self._postprocess_output(raw_output)
# 结果验证
validated_output = self._validate_output(processed_output)
# 记录成功执行
self.execution_stats["successful_executions"] += 1
execution_time = time.time() - start_time
self.execution_stats["total_execution_time"] += execution_time
self.execution_stats["average_response_time"] = (
self.execution_stats["total_execution_time"] /
self.execution_stats["total_executions"]
)
return {
"success": True,
"result": validated_output,
"execution_time": execution_time,
"chain_name": self.name
}
except Exception as e:
self.execution_stats["failed_executions"] += 1
# 错误恢复尝试
recovery_result = self._attempt_error_recovery(inputs, str(e))
if recovery_result["success"]:
self.execution_stats["successful_executions"] += 1
return recovery_result
else:
return {
"success": False,
"error": str(e),
"chain_name": self.name,
"execution_time": time.time() - start_time,
"recovery_attempted": True
}
def _preprocess_inputs(self, inputs: Dict) -> Dict:
"""输入预处理:数据清洗、格式标准化"""
processed = inputs.copy()
# 清理文本输入中的特殊字符
for key, value in processed.items():
if isinstance(value, str):
# 移除过多的空白字符
processed[key] = " ".join(value.split())
# 确保文本不会过长
if len(processed[key]) > 5000:
processed[key] = processed[key][:5000] + "...[内容已截断]"
return processed
def _postprocess_output(self, raw_output: str) -> Dict:
"""输出后处理:格式化、结构化"""
try:
# 如果有输出解析器,使用解析器
if self.output_parser:
return self.output_parser.parse(raw_output)
# 否则进行基本的结构化处理
return {"content": raw_output.strip(), "raw_output": raw_output}
except Exception as e:
# 解析失败时的降级处理
return {
"content": raw_output.strip(),
"raw_output": raw_output,
"parsing_error": str(e)
}
def _validate_output(self, output: Dict) -> Dict:
"""输出验证:质量检查、格式验证"""
validation_results = {
"is_valid": True,
"validation_issues": [],
"quality_score": 1.0
}
# 检查内容长度
content = output.get("content", "")
if len(content) < 10:
validation_results["validation_issues"].append("内容过短")
validation_results["quality_score"] *= 0.7
# 检查是否包含有用信息
if "抱歉" in content or "无法" in content:
validation_results["validation_issues"].append("可能包含拒绝回答")
validation_results["quality_score"] *= 0.8
# 检查格式完整性
if self.output_parser and "parsing_error" in output:
validation_results["validation_issues"].append("输出格式不符合预期")
validation_results["quality_score"] *= 0.6
# 综合判断
if validation_results["quality_score"] < 0.5:
validation_results["is_valid"] = False
output["validation"] = validation_results
return output
def _attempt_error_recovery(self, original_inputs: Dict, error_msg: str) -> Dict:
"""错误恢复:重试、降级处理"""
print(f"尝试错误恢复,原错误:{error_msg}")
# 简化输入重试
simplified_inputs = {}
for key, value in original_inputs.items():
if isinstance(value, str) and len(value) > 1000:
simplified_inputs[key] = value[:500] + "...[已简化]"
else:
simplified_inputs[key] = value
try:
# 使用简化输入重试
raw_output = self.base_chain.run(**simplified_inputs)
processed_output = self._postprocess_output(raw_output)
return {
"success": True,
"result": processed_output,
"recovery_method": "input_simplification",
"chain_name": self.name
}
except Exception as recovery_error:
return {
"success": False,
"original_error": error_msg,
"recovery_error": str(recovery_error),
"chain_name": self.name
}
def get_performance_report(self) -> Dict:
"""获取性能报告"""
stats = self.execution_stats
success_rate = (stats["successful_executions"] / max(stats["total_executions"], 1)) * 100
return {
"chain_name": self.name,
"total_executions": stats["total_executions"],
"success_rate": f"{success_rate:.2f}%",
"average_response_time": f"{stats['average_response_time']:.2f}s",
"performance_grade": self._calculate_performance_grade(success_rate, stats["average_response_time"])
}
def _calculate_performance_grade(self, success_rate: float, avg_time: float) -> str:
"""计算性能等级"""
if success_rate >= 95 and avg_time <= 2:
return "A+"
elif success_rate >= 90 and avg_time <= 5:
return "A"
elif success_rate >= 80 and avg_time <= 10:
return "B"
elif success_rate >= 70:
return "C"
else:
return "D"
# 实际应用示例:业务分析链
def create_business_analysis_chain():
"""创建业务分析链"""
# 构建结构化输出解析器
output_parser = PydanticOutputParser(pydantic_object=BusinessAnalysisResult)
# 设计专业的业务分析提示词
analysis_template = PromptTemplate(
input_variables=["business_context", "data_summary", "analysis_focus"],
template="""
你是一位拥有15年经验的资深商业顾问,擅长数据分析和战略规划。
业务背景:
{business_context}
数据概览:
{data_summary}
分析重点:
{analysis_focus}
请基于以上信息进行深度业务分析。你的分析应该:
1. 基于数据事实,避免主观臆断
2. 提供可执行的具体建议
3. 识别潜在风险和机遇
4. 评估分析结果的可信度
{format_instructions}
分析结果:
""",
partial_variables={"format_instructions": output_parser.get_format_instructions()}
)
# 创建增强版LLM链
llm = OpenAI(temperature=0.3, max_tokens=1500)
business_chain = EnhancedLLMChain(
llm=llm,
prompt_template=analysis_template,
output_parser=output_parser,
name="business_analysis_chain"
)
return business_chain
# 使用示例
business_chain = create_business_analysis_chain()
# 测试业务分析
test_input = {
"business_context": "一家成立3年的SaaS公司,主要服务中小企业的客户管理需求",
"data_summary": "月收入150万,用户留存率85%,客户获取成本300元,平均客单价1200元/月,主要竞争对手3家",
"analysis_focus": "评估当前商业模式的可持续性,识别增长瓶颈,制定下一年度发展策略"
}
print("=== 执行业务分析链 ===")
result = business_chain.execute_with_monitoring(test_input)
if result["success"]:
print(f"分析完成,耗时:{result['execution_time']:.2f}秒")
# 解析结构化结果
analysis_result = result["result"]
if "content" in analysis_result:
print(f"分析内容:{analysis_result['content']}")
# 显示验证信息
if "validation" in analysis_result:
validation = analysis_result["validation"]
print(f"质量评分:{validation['quality_score']:.2f}")
if validation["validation_issues"]:
print(f"质量问题:{validation['validation_issues']}")
else:
print(f"分析失败:{result['error']}")
# 获取性能报告
print("\n=== 性能报告 ===")
performance_report = business_chain.get_performance_report()
for key, value in performance_report.items():
print(f"{key}: {value}")
3.2 SequentialChain:编排复杂的业务流程
SequentialChain是LangChain中最常用的复合链类型,它将多个处理步骤按顺序连接,前一步的输出成为后一步的输入。这种设计模式在企业应用中非常常见:客户需求分析→解决方案设计→风险评估→实施计划制定。
SequentialChain的真正价值在于它实现了复杂业务流程的模块化。每个步骤都是独立的链条,可以单独测试、优化和替换。这种模块化设计不仅提高了代码的可维护性,还使得业务流程的调整变得更加灵活。
在设计SequentialChain时,需要特别注意数据流的设计。每个步骤的输出必须能够被下一个步骤理解和处理,这就要求我们在设计时考虑整个流程的数据传递逻辑。
from langchain.chains import SequentialChain
from langchain import LLMChain, PromptTemplate
from langchain.llms import OpenAI
from typing import Dict, Any
import json
class EnterpriseSequentialChain:
"""企业级顺序链,支持复杂业务流程编排"""
def __init__(self, name="enterprise_sequential_chain"):
self.name = name
self.chains = []
self.chain_configs = []
self.execution_log = []
def add_chain_step(self, chain, step_name, required_inputs, output_keys, description=""):
"""添加链条步骤"""
self.chain_configs.append({
"step_name": step_name,
"required_inputs": required_inputs,
"output_keys": output_keys,
"description": description
})
self.chains.append(chain)
def build_sequential_chain(self):
"""构建完整的顺序链"""
# 收集所有输入变量
all_inputs = set()
all_outputs = []
for config in self.chain_configs:
all_inputs.update(config["required_inputs"])
all_outputs.extend(config["output_keys"])
# 移除既是输入又是输出的变量(中间变量)
initial_inputs = []
for inp in all_inputs:
if inp not in all_outputs:
initial_inputs.append(inp)
# 创建顺序链
sequential_chain = SequentialChain(
chains=self.chains,
input_variables=initial_inputs,
output_variables=all_outputs,
verbose=True
)
return sequential_chain
def execute_with_detailed_logging(self, inputs: Dict[str, Any]) -> Dict[str, Any]:
"""执行链并记录详细日志"""
self.execution_log = []
try:
sequential_chain = self.build_sequential_chain()
# 记录开始执行
self.execution_log.append({
"step": "initialization",
"timestamp": time.time(),
"inputs": inputs,
"status": "started"
})
# 执行链
start_time = time.time()
result = sequential_chain(inputs)
execution_time = time.time() - start_time
# 记录完成
self.execution_log.append({
"step": "completion",
"timestamp": time.time(),
"execution_time": execution_time,
"status": "completed"
})
return {
"success": True,
"result": result,
"execution_time": execution_time,
"execution_log": self.execution_log
}
except Exception as e:
self.execution_log.append({
"step": "error",
"timestamp": time.time(),
"error": str(e),
"status": "failed"
})
return {
"success": False,
"error": str(e),
"execution_log": self.execution_log
}
def create_execution_report(self, execution_result: Dict) -> str:
"""创建执行报告"""
if not execution_result["success"]:
return f"执行失败:{execution_result['error']}"
report = f"=== {self.name} 执行报告 ===\n"
report += f"总执行时间:{execution_result['execution_time']:.2f}秒\n"
report += f"执行步骤数:{len(self.chain_configs)}\n\n"
# 各步骤说明
report += "流程步骤:\n"
for i, config in enumerate(self.chain_configs, 1):
report += f"{i}. {config['step_name']}: {config['description']}\n"
report += f" 输入:{config['required_inputs']}\n"
report += f" 输出:{config['output_keys']}\n\n"
return report
# 创建客户服务处理流程
def create_customer_service_workflow():
"""创建完整的客户服务处理工作流"""
llm = OpenAI(temperature=0.3, max_tokens=800)
workflow = EnterpriseSequentialChain("customer_service_workflow")
# 步骤1:问题分析和分类
problem_analysis_prompt = PromptTemplate(
input_variables=["customer_message", "customer_history"],
template="""
你是专业的客服问题分析师。请分析客户问题。
客户消息:{customer_message}
客户历史:{customer_history}
请分析:
1. 问题类型(技术问题/账单问题/产品咨询/投诉建议)
2. 紧急程度(高/中/低)
3. 情感倾向(正面/中性/负面)
4. 关键信息提取
分析结果(使用JSON格式):
"""
)
problem_analysis_chain = LLMChain(
llm=llm,
prompt=problem_analysis_prompt,
output_key="problem_analysis"
)
# 步骤2:解决方案生成
solution_generation_prompt = PromptTemplate(
input_variables=["problem_analysis", "customer_message"],
template="""
基于问题分析,生成解决方案。
问题分析:{problem_analysis}
原始问题:{customer_message}
请提供:
1. 具体解决步骤
2. 所需资源和权限
3. 预计解决时间
4. 备选方案(如主方案不可行)
解决方案:
"""
)
solution_generation_chain = LLMChain(
llm=llm,
prompt=solution_generation_prompt,
output_key="solution_plan"
)
# 步骤3:客户回复生成
response_generation_prompt = PromptTemplate(
input_variables=["problem_analysis", "solution_plan", "customer_message"],
template="""
生成专业、友善的客户回复。
问题分析:{problem_analysis}
解决方案:{solution_plan}
原始问题:{customer_message}
回复风格要求:
- 表达理解和同情
- 提供清晰的解决步骤
- 语气专业但亲切
- 包含后续联系方式
客户回复:
"""
)
response_generation_chain = LLMChain(
llm=llm,
prompt=response_generation_prompt,
output_key="customer_response"
)
# 步骤4:后续行动计划
followup_planning_prompt = PromptTemplate(
input_variables=["problem_analysis", "solution_plan"],
template="""
制定后续行动计划。
问题分析:{problem_analysis}
解决方案:{solution_plan}
制定计划:
1. 内部处理流程(谁负责、何时完成)
2. 客户沟通计划(何时回访、回访内容)
3. 质量监控要点
4. 升级机制(如问题未解决)
行动计划:
"""
)
followup_planning_chain = LLMChain(
llm=llm,
prompt=followup_planning_prompt,
output_key="followup_plan"
)
# 添加所有步骤到工作流
workflow.add_chain_step(
chain=problem_analysis_chain,
step_name="问题分析",
required_inputs=["customer_message", "customer_history"],
output_keys=["problem_analysis"],
description="分析客户问题类型、紧急程度和情感倾向"
)
workflow.add_chain_step(
chain=solution_generation_chain,
step_name="解决方案生成",
required_inputs=["problem_analysis", "customer_message"],
output_keys=["solution_plan"],
description="基于问题分析生成具体解决方案"
)
workflow.add_chain_step(
chain=response_generation_chain,
step_name="客户回复生成",
required_inputs=["problem_analysis", "solution_plan", "customer_message"],
output_keys=["customer_response"],
description="生成专业友善的客户回复"
)
workflow.add_chain_step(
chain=followup_planning_chain,
step_name="后续计划制定",
required_inputs=["problem_analysis", "solution_plan"],
output_keys=["followup_plan"],
description="制定内部处理和客户沟通计划"
)
return workflow
# 使用客户服务工作流
customer_service_workflow = create_customer_service_workflow()
# 测试用例
test_customer_case = {
"customer_message": """
您好,我是贵公司的VIP客户,账号是VIP2024001。
我在使用你们的云存储服务时遇到了严重问题,昨天上传的重要文件今天完全找不到了!
这些文件对我的工作至关重要,如果丢失会造成巨大损失。
我试过刷新、重新登录,都没有用。这到底是怎么回事?!
我对你们的服务质量非常失望,考虑是否要换到其他服务商。
请立即给我解决方案!
""",
"customer_history": """
VIP客户,使用服务2年,历史满意度较高。
最近3个月内无投诉记录。
账户状态:正常,付费用户。
使用的主要功能:云存储、文件同步。
"""
}
print("=== 执行客户服务工作流 ===")
workflow_result = customer_service_workflow.execute_with_detailed_logging(test_customer_case)
if workflow_result["success"]:
print("工作流执行成功!")
# 显示各步骤结果
result = workflow_result["result"]
print(f"\n问题分析:{result.get('problem_analysis', '未生成')[:200]}...")
print(f"\n解决方案:{result.get('solution_plan', '未生成')[:200]}...")
print(f"\n客户回复:{result.get('customer_response', '未生成')[:300]}...")
print(f"\n后续计划:{result.get('followup_plan', '未生成')[:200]}...")
# 生成执行报告
report = customer_service_workflow.create_execution_report(workflow_result)
print(f"\n{report}")
else:
print(f"工作流执行失败:{workflow_result['error']}")
3.3 RouterChain:智能的条件分支处理
RouterChain是LangChain中最智能的链类型之一,它能够根据输入内容动态选择最适合的处理路径。这种能力在企业应用中极其重要,因为同一个系统往往需要处理多种不同类型的请求,每种请求都有其最优的处理方式。
RouterChain的核心价值在于它将路由决策智能化。传统的条件分支依赖硬编码的规则,而RouterChain使用AI来理解输入内容的语义,从而做出更加准确和灵活的路由决策。这种设计使得系统能够更好地适应复杂和变化的业务需求。
```python
from langchain.chains.router import MultiPromptChain
from langchain.chains.router.llm_router import LLMRouterChain, RouterOutputParser
from langchain.chains.router.multi_prompt_prompt import MULTI_PROMPT_ROUTER_TEMPLATE
from langchain import PromptTemplate, LLMChain
from langchain.llms import OpenAI
class IntelligentRouterSystem:
"""智能路由系统,支持复杂的业务场景路由"""
def __init__(self, llm):
self.llm = llm
self.route_chains = {}
self.routing_logic = {}
self.performance_metrics = {}
def create_specialized_chains(self):
"""创建专门化的处理链"""
# 技术支持链
tech_support_template = PromptTemplate(
input_variables=["input"],
template="""
你是一位资深的技术支持工程师,专精于:
- 软件故障诊断与解决
- 系统性能优化
- 用户操作指导
- 技术方案推荐
用户问题:{input}
请提供:
1. 问题原因分析
2. 具体解决步骤(编号列出)
3. 预防措施建议
4. 如需协助,提供升级路径
技术支持回复:
"""
)
# 商务咨询链
business_inquiry_template = PromptTemplate(
input_variables=["input"],
template="""
你是专业的商务顾问,擅长:
- 产品方案设计
- 价格策略制定
- 商业模式分析
- 市场趋势洞察
客户咨询:{input}
请提供:
1. 需求理解确认
2. 推荐方案及理由
3. 价值分析
4. 下一步行动建议
商务咨询回复:
"""
)
# 投诉处理链
complaint_handling_template = PromptTemplate(
input_variables=["input"],
template="""
你是经验丰富的投诉处理专员,具备:
- 强大的同理心和倾听能力
- 冲突化解和问题解决技能
- 政策灵活运用能力
- 客户关系修复经验
客户投诉:{input}
处理步骤:
1. 表达理解和歉意
2. 深入了解具体问题
3. 提供解决方案和补偿(如适用)
4. 承诺改进措施
5. 后续跟进安排
投诉处理回复:
"""
)
# 产品咨询链
product_consultation_template = PromptTemplate(
input_variables=["input"],
template="""
你是产品专家,熟悉:
- 产品功能特性
- 使用场景匹配
- 竞品对比分析
- 升级路径规划
用户咨询:{input}
请提供:
1. 产品功能介绍
2. 适用场景分析
3. 优势对比说明
4. 使用建议
产品咨询回复:
"""
)
# 创建专门化链条
self.route_chains = {
"tech_support": LLMChain(
llm=self.llm,
prompt=tech_support_template,
verbose=True
),
"business_inquiry": LLMChain(
llm=self.llm,
prompt=business_inquiry_template,
verbose=True
),
"complaint_handling": LLMChain(
llm=self.llm,
prompt=complaint_handling_template,
verbose=True
),
"product_consultation": LLMChain(
llm=self.llm,
prompt=product_consultation_template,
verbose=True
)
}
# 定义路由逻辑描述
self.routing_logic = {
"tech_support": "处理技术问题、故障报告、操作疑问等技术相关询问",
"business_inquiry": "处理商务合作、价格咨询、方案定制等商业相关询问",
"complaint_handling": "处理客户投诉、服务问题、退款申请等负面反馈",
"product_consultation": "处理产品功能、使用方法、版本对比等产品相关咨询"
}
def create_router_chain(self):
"""创建智能路由链"""
# 构建路由提示词信息
destination_chains = {}
for name, chain in self.route_chains.items():
destination_chains[name] = chain
# 创建路由器链
router_template = MULTI_PROMPT_ROUTER_TEMPLATE.format(
destinations="\n".join([
f"{name}: {description}"
for name, description in self.routing_logic.items()
])
)
router_prompt = PromptTemplate(
template=router_template,
input_variables=["input"],
output_parser=RouterOutputParser()
)
router_chain = LLMRouterChain.from_llm(
self.llm,
router_prompt,
verbose=True
)
# 创建多路由链
multi_prompt_chain = MultiPromptChain(
router_chain=router_chain,
destination_chains=destination_chains,
default_chain=self.route_chains["product_consultation"], # 默认路由
verbose=True
)
return multi_prompt_chain
def route_and_process(self, user_input: str) -> Dict[str, Any]:
"""路由并处理用户输入"""
router_chain = self.create_router_chain()
try:
start_time = time.time()
# 执行路由和处理
result = router_chain.run(input=user_input)
processing_time = time.time() - start_time
# 记录性能指标
# 这里简化了路由检测逻辑,实际应用中需要从路由链获取选择的路由
selected_route = self._detect_used_route(user_input)
self._update_performance_metrics(selected_route, processing_time, True)
return {
"success": True,
"result": result,
"selected_route": selected_route,
"processing_time": processing_time
}
except Exception as e:
self._update_performance_metrics("unknown", 0, False)
return {
"success": False,
"error": str(e),
"processing_time": 0
}
def _detect_used_route(self, user_input: str) -> str:
"""简化的路由检测(实际应用中应从router chain获取)"""
user_input_lower = user_input.lower()
# 投诉关键词
complaint_keywords = ["投诉", "不满意", "问题", "错误", "失望", "退款", "赔偿"]
if any(keyword in user_input_lower for keyword in complaint_keywords):
return "complaint_handling"
# 技术支持关键词
tech_keywords = ["故障", "错误", "bug", "无法", "不能", "怎么操作", "技术问题"]
if any(keyword in user_input_lower for keyword in tech_keywords):
return "tech_support"
# 商务咨询关键词
business_keywords = ["价格", "报价", "合作", "定制", "商务", "购买", "方案"]
if any(keyword in user_input_lower for keyword in business_keywords):
return "business_inquiry"
# 默认为产品咨询
return "product_consultation"
def _update_performance_metrics(self, route: str, processing_time: float, success: bool):
"""更新性能指标"""
if route not in self.performance_metrics:
self.performance_metrics[route] = {
"total_requests": 0,
"successful_requests": 0,
"total_processing_time": 0,
"average_processing_time": 0
}
metrics = self.performance_metrics[route]
metrics["total_requests"] += 1
if success:
metrics["successful_requests"] += 1
metrics["total_processing_time"] += processing_time
metrics["average_processing_time"] = (
metrics["total_processing_time"] / metrics["successful_requests"]
)
def get_routing_analytics(self) -> Dict[str, Any]:
"""获取路由分析报告"""
total_requests = sum(
metrics["total_requests"]
for metrics in self.performance_metrics.values()
)
analytics = {
"total_requests": total_requests,
"route_distribution": {},
"performance_summary": {}
}
for route, metrics in self.performance_metrics.items():
# 路由分布
distribution_percentage = (metrics["total_requests"] / max(total_requests, 1)) * 100
analytics["route_distribution"][route] = {
"requests": metrics["total_requests"],
"percentage": f"{distribution_percentage:.1f}%"
}
# 性能摘要
success_rate = (metrics["successful_requests"] / max(metrics["total_requests"], 1)) * 100
analytics["performance_summary"][route] = {
"success_rate": f"{success_rate:.1f}%",
"avg_processing_time": f"{metrics['average_processing_time']:.2f}s"
}
return analytics
# 创建和使用智能路由系统
llm = OpenAI(temperature=0.5, max_tokens=1000)
router_system = IntelligentRouterSystem(llm)
router_system.create_specialized_chains()
# 测试不同类型的用户输入
test_cases = [
"我们公司想要了解你们的企业版产品价格和功能,希望能定制一个适合我们的方案。",
"系统登录总是出现500错误,我试了清除缓存和重启浏览器都没用,这是什么问题?",
"我对你们的服务非常不满意!客服态度差,产品功能也有问题,我要投诉并要求退款!",
"请问你们的Pro版本和基础版本有什么区别?我应该选择哪个版本?",
"能否介绍一下你们产品的主要功能特点?"
]
print("=== 智能路由系统测试 ===")
for i, test_input in enumerate(test_cases, 1):
print(f"\n测试用例 {i}: {test_input[:50]}...")
result = router_system.route_and_process(test_input)
if result["success"]:
print(f"路由选择: {result['selected_route']}")
print(f"处理时间: {result['processing_time']:.2f}秒")
print(f"处理结果: {result['result'][:150]}...")
else:
print(f"处理失败: {result['error']}")
# 显示路由分析报告
print("\n=== 路由分析报告 ===")
analytics = router_system.get_routing_analytics()
print(f"总请求数: {analytics['total_requests']}")
print("\n路由分布:")
for route, distribution in analytics["route_distribution"].items():
print(f" {route}: {distribution['requests']}次 ({distribution['percentage']})")
print("\n性能摘要:")
for route, performance in analytics["performance_summary"].items():
print(f" {route}: 成功率{performance['success_rate']}, 平均耗时{performance['avg_processing_time']}")
通过这种方式,Chains组件将复杂的AI应用开发从线性思维转向流程化思维,从单一功能转向系统化能力。无论是简单的LLMChain、复杂的SequentialChain,还是智能的RouterChain,都为构建企业级AI应用提供了强大的基础设施。
4. Agents:构建自主决策的智能系统
如果说Chains代表了预先设计的固定流程,那么Agents则体现了AI的自主决策能力。Agent是LangChain中最接近"智能助手"概念的组件,它能够根据任务需求动态选择工具、制定执行计划,并在执行过程中根据反馈调整策略。这种能力使得AI应用从简单的问答系统升级为能够解决复杂问题的智能代理。
Agents的革命性在于它改变了人机交互的范式。传统的AI应用中,人类需要将复杂任务分解为简单步骤,然后逐一指导AI执行。而在Agent模式中,人类只需要描述目标,AI会自行分解任务、选择工具、执行操作,直到达成目标。
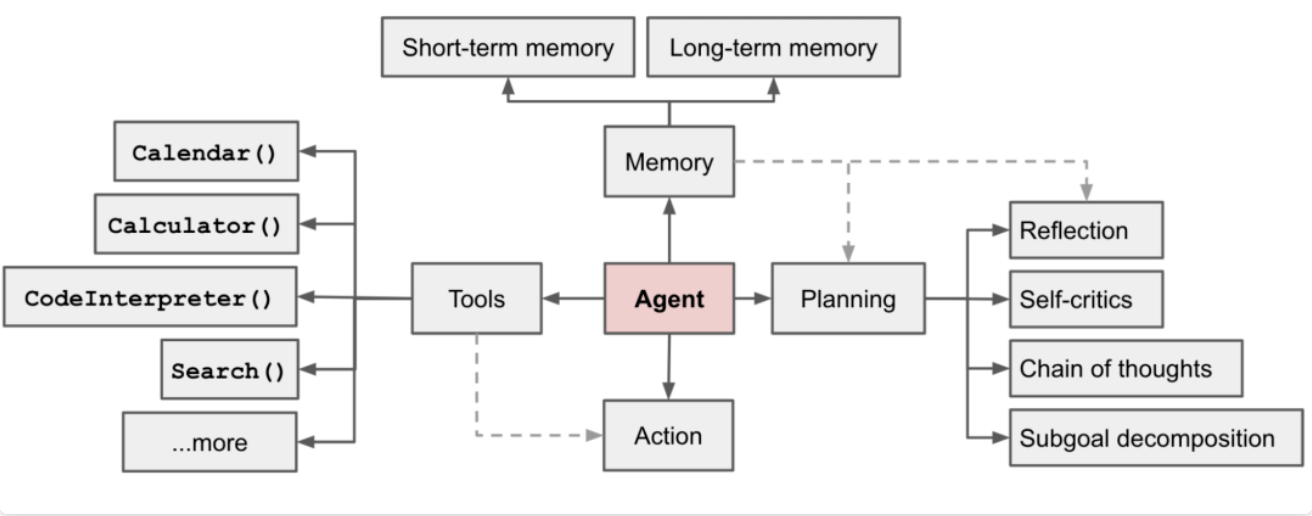
4.1 ReAct框架:推理与行动的循环
ReAct(Reasoning and Acting)是Agent架构的理论基础,它将人类解决问题的思维过程系统化:观察现状→分析思考→选择行动→观察结果→继续推理。这个循环过程使得AI能够像人类一样处理复杂的、需要多步骤解决的问题。
ReAct框架的核心价值在于它使AI的决策过程变得透明和可控。通过明确的"思考"和"行动"分离,我们可以清楚地看到AI是如何分析问题、为什么选择特定工具、以及如何根据结果调整策略。
让我们通过一个具体的客户服务场景来理解ReAct的工作原理:
用户问题:“我的订单ORD-2024-001已经下单3天了,但是物流信息显示还没有发货,这是什么情况?”
Agent的ReAct处理过程:
-
思考(Thought):用户询问订单状态,我需要先查询订单信息,然后查看物流状态,如果确实有问题还需要提供解决方案。
-
行动(Action):使用订单查询工具查询ORD-2024-001的详细信息。
-
观察(Observation):订单状态显示"已确认",但库存显示该商品缺货。
-
思考(Thought):原来是库存问题导致延迟发货,需要查询补货时间,并为客户提供解决方案。
-
行动(Action):查询商品补货时间,同时查看是否有替代商品。
-
观察(Observation):预计2天后补货,有类似的商品现货。
-
思考(Thought):现在可以给客户完整的回复了,包括延迟原因、预计时间和替代方案。
这种循环式的推理过程让Agent能够处理复杂的、需要多步骤解决的问题。
from langchain.agents import initialize_agent, Tool, AgentType
from langchain.llms import OpenAI
from langchain.memory import ConversationBufferMemory
# 简单的工具示例
def order_query_tool(order_id):
"""订单查询工具"""
# 模拟订单查询
orders = {
"ORD-2024-001": {
"status": "已确认",
"product": "智能手表Pro",
"stock_status": "缺货",
"estimated_restock": "2天"
}
}
return orders.get(order_id, "订单不存在")
def inventory_check_tool(product_name):
"""库存检查工具"""
inventory = {
"智能手表Pro": {"stock": 0, "restock_date": "2024-01-25"},
"智能手表标准版": {"stock": 50, "restock_date": "现货"}
}
return inventory.get(product_name, "商品不存在")
# 创建工具列表
tools = [
Tool(
name="订单查询",
func=order_query_tool,
description="查询订单状态和详细信息,输入订单号"
),
Tool(
name="库存检查",
func=inventory_check_tool,
description="检查商品库存情况,输入商品名称"
)
]
# 创建Agent
llm = OpenAI(temperature=0)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
agent = initialize_agent(
tools=tools,
llm=llm,
agent=AgentType.CHAT_CONVERSATIONAL_REACT_DESCRIPTION,
memory=memory,
verbose=True # 显示推理过程
)
# 执行查询
result = agent.run("我的订单ORD-2024-001已经下单3天了,但是物流信息显示还没有发货,这是什么情况?")
print(result)
4.2 工具生态系统的设计原则
Agent的能力边界很大程度上取决于其可用的工具集。一个设计良好的工具生态系统应该遵循以下几个原则:
功能完整性:工具集应该覆盖Agent需要完成的主要任务类型。对于企业客服Agent,这可能包括订单查询、库存检查、客户信息管理、通知发送等。
抽象层次适中:工具不应该过于底层(如直接的SQL操作),也不应该过于高层(如"解决所有客户问题")。理想的抽象层次是让Agent能够理解工具的用途,又不需要了解实现细节。
描述清晰准确:工具的描述是Agent选择工具的重要依据。描述应该明确说明工具的功能、输入格式和适用场景。
错误处理机制:工具应该提供清晰的错误信息,帮助Agent理解问题并选择合适的替代方案。
让我们看一个工具设计的对比例子:
# ❌ 设计不良的工具
class BadDatabaseTool(BaseTool):
name = "database"
description = "数据库操作" # 描述过于模糊
def _run(self, query):
# 直接执行SQL,抽象层次过低
return execute_sql(query)
# ✅ 设计良好的工具
class GoodCustomerTool(BaseTool):
name = "customer_info_query"
description = """
查询客户信息工具。可以查询客户的基本信息、订单历史、会员等级等。
输入格式:customer_id:客户ID 或 phone:手机号 或 email:邮箱
返回:客户详细信息的JSON格式数据
"""
def _run(self, query):
# 解析查询参数
if "customer_id:" in query:
customer_id = query.split("customer_id:")[1].strip()
return self._query_by_id(customer_id)
elif "phone:" in query:
phone = query.split("phone:")[1].strip()
return self._query_by_phone(phone)
# ... 其他查询方式
def _query_by_id(self, customer_id):
# 具体的查询逻辑
pass
4.3 Agent性能优化策略
在生产环境中,Agent的性能直接影响用户体验和系统成本。有效的性能优化策略包括:
提示词优化:精心设计的提示词可以减少Agent的推理步骤。比如,在提示词中明确说明何时应该停止推理,可以避免Agent进行不必要的工具调用。
工具选择策略:通过工具使用统计和成功率数据,可以优化工具推荐顺序。经常使用且成功率高的工具可以优先推荐。
并发控制:对于可以并行执行的工具调用,实现并发处理可以显著提升响应速度。
缓存机制:对于频繁查询的数据(如商品信息、客户基本信息),实现智能缓存可以减少重复的数据库查询。
错误恢复:当工具调用失败时,Agent应该能够选择替代方案或简化处理流程,而不是直接失败。
4.4 企业级Agent的最佳实践
在企业环境中部署Agent需要考虑更多的因素:
权限控制:不同的Agent应该有不同的权限级别。客服Agent可能只能查询信息,而管理Agent可能可以修改数据。
审计日志:所有Agent的行为都应该被记录,包括使用了哪些工具、获取了哪些数据、做出了什么决策。
性能监控:实时监控Agent的响应时间、成功率、资源使用情况,及时发现和解决问题。
安全考虑:Agent可能处理敏感信息,需要实现数据脱敏、访问控制等安全措施。
人工干预机制:当Agent遇到复杂问题或不确定的情况时,应该能够将问题升级给人工处理。
通过这些设计原则和最佳实践,我们可以构建出既智能又可靠的企业级Agent系统。Agent不仅能够提升工作效率,还能在保证质量和安全的前提下处理大量的常规任务,让人类专注于更有价值的工作。
5. Memory:构建有记忆的智能对话系统
Memory(记忆系统)是LangChain中最容易被忽视,但却极其重要的组件。如果说Models提供了AI的"大脑",Prompts提供了"指令",Chains提供了"流程",Agents提供了"决策能力",那么Memory就是AI的"记忆"—— 它使AI能够在对话中保持上下文连贯性,记住用户的偏好,并基于历史交互不断优化服务质量。
在没有记忆的AI系统中,每次交互都是独立的,AI无法根据之前的对话来调整回应策略。这就像是患有短期记忆缺失症的人,每次对话都要重新开始。Memory组件的引入,使得AI能够建立起连续的对话体验,这对于构建真正智能的应用至关重要。
现代的记忆系统不仅仅是简单的对话历史存储,而是一个智能的信息管理系统,它需要在记忆容量、检索效率、信息重要性之间找到最佳平衡。
5.1 对话记忆的多重挑战
在设计对话记忆系统时,我们面临着几个核心挑战:
容量限制问题:大语言模型都有token限制,完整的对话历史很容易超出这个限制。一次复杂的客服对话可能包含数千个token,如果保存完整历史,很快就会达到模型的上下文窗口上限。
信息重要性权衡:并不是所有的对话内容都同等重要。用户的核心需求、关键决策点、个人偏好等信息的价值远高于礼貌用语和闲聊内容。记忆系统需要能够识别和保留重要信息。
检索效率要求:在长期的对话历史中快速找到相关信息是一个技术挑战。用户可能在第100轮对话中询问第5轮对话中提到的某个细节,系统需要能够迅速定位并提取相关context。
个性化与隐私平衡:记忆系统能够记住用户偏好是好事,但也带来了隐私保护的挑战。如何在提供个性化服务的同时保护用户隐私,是设计中必须考虑的因素。
LangChain提供了多种记忆策略来应对这些挑战:
from langchain.memory import ConversationBufferMemory, ConversationSummaryMemory, ConversationBufferWindowMemory
from langchain import ConversationChain
from langchain.llms import OpenAI
# 1. 缓冲记忆:适合短期对话
buffer_memory = ConversationBufferMemory()
buffer_conversation = ConversationChain(
llm=OpenAI(temperature=0.7),
memory=buffer_memory,
verbose=True
)
# 2. 摘要记忆:适合长期对话
summary_memory = ConversationSummaryMemory(
llm=OpenAI(temperature=0),
max_token_limit=1000 # 超过1000 tokens时自动摘要
)
summary_conversation = ConversationChain(
llm=OpenAI(temperature=0.7),
memory=summary_memory,
verbose=True
)
# 3. 滑动窗口记忆:保留最近的N轮对话
window_memory = ConversationBufferWindowMemory(k=5) # 保留最近5轮
window_conversation = ConversationChain(
llm=OpenAI(temperature=0.7),
memory=window_memory,
verbose=True
)
5.2 智能记忆管理策略
企业级应用需要更智能的记忆管理策略。简单的缓冲或摘要往往不能满足复杂业务场景的需求。我们需要构建分层的、智能的记忆系统:
短期工作记忆:保存当前任务相关的即时信息,类似人类的工作记忆。这部分信息会在任务完成后清理。
中期对话记忆:保存当前对话会话的重要信息,包括用户需求、已提供的服务、待解决的问题等。
长期用户记忆:保存用户的基本信息、偏好设置、历史交互模式等,用于个性化服务。
知识记忆:保存业务相关的事实性信息,如产品信息、政策规定、常见问题解答等。
from langchain.schema import BaseMessage, HumanMessage, AIMessage
import json
from datetime import datetime, timedelta
from typing import Dict, List, Any, Optional
class EnterpriseMemoryManager:
"""企业级记忆管理系统"""
def __init__(self, llm):
self.llm = llm
self.short_term_memory = [] # 工作记忆
self.session_memory = {} # 会话记忆
self.user_profile = {} # 用户档案
self.knowledge_base = {} # 知识库
def add_interaction(self, user_input: str, ai_response: str, user_id: str = None):
"""添加交互记录"""
timestamp = datetime.now()
# 提取关键信息
key_info = self._extract_key_information(user_input, ai_response)
# 更新短期记忆
self.short_term_memory.append({
"timestamp": timestamp,
"user_input": user_input,
"ai_response": ai_response,
"key_info": key_info
})
# 更新用户档案
if user_id:
self._update_user_profile(user_id, user_input, key_info)
# 管理记忆容量
self._manage_memory_capacity()
def _extract_key_information(self, user_input: str, ai_response: str) -> Dict[str, Any]:
"""提取关键信息"""
key_info = {
"entities": [], # 提到的实体
"intents": [], # 用户意图
"sentiment": "neutral", # 情感倾向
"satisfaction": None, # 满意度
"follow_up_needed": False # 是否需要跟进
}
# 简化的信息提取逻辑
user_lower = user_input.lower()
# 提取产品名称
products = ["手机", "电脑", "平板", "耳机", "手表"]
for product in products:
if product in user_input:
key_info["entities"].append({"type": "product", "value": product})
# 识别意图
if any(word in user_lower for word in ["购买", "买", "下单"]):
key_info["intents"].append("purchase")
elif any(word in user_lower for word in ["退货", "退款", "不满意"]):
key_info["intents"].append("return")
elif any(word in user_lower for word in ["咨询", "了解", "请问"]):
key_info["intents"].append("inquiry")
# 情感分析
if any(word in user_lower for word in ["不满", "失望", "生气", "问题"]):
key_info["sentiment"] = "negative"
elif any(word in user_lower for word in ["满意", "喜欢", "好", "棒"]):
key_info["sentiment"] = "positive"
return key_info
def _update_user_profile(self, user_id: str, user_input: str, key_info: Dict):
"""更新用户档案"""
if user_id not in self.user_profile:
self.user_profile[user_id] = {
"preferences": {},
"purchase_history": [],
"interaction_count": 0,
"satisfaction_scores": [],
"last_contact": datetime.now()
}
profile = self.user_profile[user_id]
profile["interaction_count"] += 1
profile["last_contact"] = datetime.now()
# 更新偏好
for entity in key_info["entities"]:
if entity["type"] == "product":
product = entity["value"]
if product not in profile["preferences"]:
profile["preferences"][product] = 0
profile["preferences"][product] += 1
def _manage_memory_capacity(self):
"""管理记忆容量"""
# 保持短期记忆在合理范围内
if len(self.short_term_memory) > 20:
# 将较老的记忆转移到摘要或删除
old_memories = self.short_term_memory[:10]
self.short_term_memory = self.short_term_memory[10:]
# 生成摘要
summary = self._generate_interaction_summary(old_memories)
if summary:
self.session_memory["summary"] = summary
def _generate_interaction_summary(self, memories: List[Dict]) -> str:
"""生成交互摘要"""
if not memories:
return ""
# 提取关键点
key_points = []
for memory in memories:
key_info = memory.get("key_info", {})
if key_info.get("intents"):
key_points.append(f"用户{key_info['intents']}相关需求")
if key_info.get("entities"):
entities = [e["value"] for e in key_info["entities"]]
key_points.append(f"涉及产品:{', '.join(entities)}")
return ";".join(key_points)
def get_relevant_context(self, current_input: str, max_length: int = 1000) -> str:
"""获取相关上下文"""
context_parts = []
current_length = 0
# 1. 添加用户档案信息
if hasattr(self, 'current_user_id') and self.current_user_id:
user_info = self.get_user_context(self.current_user_id)
if user_info and current_length + len(user_info) < max_length:
context_parts.append(user_info)
current_length += len(user_info)
# 2. 添加会话摘要
if "summary" in self.session_memory:
summary = self.session_memory["summary"]
if current_length + len(summary) < max_length:
context_parts.append(f"对话摘要:{summary}")
current_length += len(summary)
# 3. 添加最近的交互记录
for memory in reversed(self.short_term_memory):
user_input = memory["user_input"]
ai_response = memory["ai_response"]
memory_text = f"用户:{user_input}\nAI:{ai_response}\n"
if current_length + len(memory_text) < max_length:
context_parts.insert(-1 if context_parts else 0, memory_text)
current_length += len(memory_text)
else:
break
return "\n".join(context_parts)
def get_user_context(self, user_id: str) -> str:
"""获取用户上下文信息"""
if user_id not in self.user_profile:
return ""
profile = self.user_profile[user_id]
context = []
# 用户偏好
if profile["preferences"]:
top_preferences = sorted(profile["preferences"].items(),
key=lambda x: x[1], reverse=True)[:3]
pref_text = "、".join([pref[0] for pref in top_preferences])
context.append(f"用户偏好产品:{pref_text}")
# 交互历史
if profile["interaction_count"] > 0:
context.append(f"历史交互次数:{profile['interaction_count']}次")
# 满意度
if profile["satisfaction_scores"]:
avg_satisfaction = sum(profile["satisfaction_scores"]) / len(profile["satisfaction_scores"])
context.append(f"历史满意度:{avg_satisfaction:.1f}/5.0")
return ";".join(context)
def add_satisfaction_score(self, user_id: str, score: float):
"""添加满意度评分"""
if user_id in self.user_profile:
self.user_profile[user_id]["satisfaction_scores"].append(score)
# 只保留最近的10次评分
if len(self.user_profile[user_id]["satisfaction_scores"]) > 10:
self.user_profile[user_id]["satisfaction_scores"].pop(0)
def get_memory_statistics(self) -> Dict[str, Any]:
"""获取记忆系统统计信息"""
return {
"short_term_count": len(self.short_term_memory),
"user_profiles": len(self.user_profile),
"total_interactions": sum(
profile["interaction_count"]
for profile in self.user_profile.values()
),
"knowledge_items": len(self.knowledge_base)
}
# 使用示例
memory_manager = EnterpriseMemoryManager(OpenAI(temperature=0))
# 模拟对话
memory_manager.current_user_id = "USER001"
# 第一轮对话
memory_manager.add_interaction(
user_input="我想了解一下你们的最新款手机",
ai_response="我们有多款最新手机,包括...",
user_id="USER001"
)
# 第二轮对话
memory_manager.add_interaction(
user_input="这款手机的价格是多少?",
ai_response="价格为2999元,现在有优惠活动...",
user_id="USER001"
)
# 获取上下文
context = memory_manager.get_relevant_context("我想买这款手机")
print("相关上下文:")
print(context)
# 获取统计信息
stats = memory_manager.get_memory_statistics()
print(f"\n记忆系统统计:{stats}")
5.3 个性化与长期记忆
真正智能的对话系统不仅要记住单次会话的内容,还要能够建立用户的长期档案,实现个性化服务。这种长期记忆涉及用户偏好学习、行为模式识别、服务质量持续改进等多个维度。
个性化记忆的价值在于它能够让AI系统随着时间推移越来越了解用户,提供越来越贴近用户需求的服务。比如,一个经常购买数码产品的用户,系统会逐渐学会优先推荐技术参数详细的产品信息;而一个注重性价比的用户,系统会更多地提供价格对比和优惠信息。
但个性化记忆也带来了新的挑战:
隐私保护:长期记忆必然涉及大量个人信息,如何在提供个性化服务的同时保护用户隐私是关键问题。
记忆偏差:系统可能因为早期的几次交互而对用户形成固定认知,难以适应用户需求的变化。
数据质量:长期记忆的质量直接影响个性化效果,错误或过时的信息可能导致不当的服务建议。
遗忘机制:人类会自然遗忘不重要的信息,但AI系统需要明确的遗忘策略来避免信息过载。
通过合理的记忆系统设计,我们可以构建既智能又负责任的AI对话系统。这样的系统不仅能够提供高质量的即时服务,还能够通过学习不断提升服务质量,最终实现真正意义上的智能客服或智能助手。
Memory组件虽然在技术栈中不如其他组件那样显眼,但它是构建真正智能的对话系统不可或缺的基础设施。只有具备了适当的记忆能力,AI系统才能从简单的问答工具进化为真正理解用户、关心用户需求的智能伙伴。
6、环境配置与快速开始
理论虽然重要,但动手实践才是掌握LangChain的关键。让我们从零开始搭建开发环境,并构建几个实际可用的示例应用,帮助您快速上手LangChain开发。
6.1 开发环境搭建
基础环境要求
LangChain对开发环境的要求相对温和,但正确的配置能够避免后续开发中的许多坑:
Python版本要求:推荐使用Python 3.8或更高版本。LangChain充分利用了Python的类型提示和异步特性,较新的Python版本能够提供更好的开发体验。
系统兼容性:LangChain支持Windows、macOS和Linux系统。不过,在Windows系统上可能会遇到一些依赖库的编译问题,建议使用conda环境管理器来简化安装过程。
标准安装流程
# 1. 创建虚拟环境(强烈推荐)
python -m venv langchain-env
# 2. 激活虚拟环境
# Windows:
langchain-env\Scripts\activate
# macOS/Linux:
source langchain-env/bin/activate
# 3. 安装核心包
pip install langchain
# 4. 安装常用扩展包
pip install langchain-openai # OpenAI集成
pip install langchain-community # 社区工具包
pip install chromadb # 向量数据库
pip install python-dotenv # 环境变量管理
pip install streamlit # 快速Web界面构建
# 5. 验证安装
python -c "import langchain; print(langchain.__version__)"
API密钥配置管理
正确的API密钥管理是LangChain应用开发的基础,也是安全性的重要保障:
# .env 文件配置(推荐方式)
OPENAI_API_KEY=your-openai-api-key-here
ANTHROPIC_API_KEY=your-anthropic-key-here
SERPAPI_API_KEY=your-search-api-key-here
# 安全配置建议
OPENAI_ORGANIZATION=your-org-id # 可选,用于团队管理
LANGCHAIN_TRACING_V2=true # 启用LangSmith追踪
LANGCHAIN_API_KEY=your-langsmith-key # LangSmith API密钥
在代码中安全地使用这些配置:
import os
from dotenv import load_dotenv
from langchain.llms import OpenAI
# 加载环境变量
load_dotenv()
# 安全的API密钥使用
def create_llm_safely():
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("请设置OPENAI_API_KEY环境变量")
return OpenAI(
api_key=api_key,
temperature=0.7
)
llm = create_llm_safely()
常见问题解决指南
依赖冲突问题:LangChain生态包含大量第三方依赖,版本冲突是常见问题。建议使用requirements.txt固定版本:
# 生成当前环境的依赖清单
pip freeze > requirements.txt
# 在新环境中安装相同版本
pip install -r requirements.txt
网络连接问题:某些依赖包可能因为网络问题安装失败,可以使用国内镜像源:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ langchain
权限问题:在某些系统上可能遇到权限问题,避免使用sudo,而是使用用户级安装:
pip install --user langchain
6.2 第一个LangChain应用
简单的智能问答程序
让我们从最基本的问答程序开始,这个例子展示了LangChain的核心工作流程:
from langchain.llms import OpenAI
from langchain import PromptTemplate, LLMChain
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
class SimpleQABot:
def __init__(self):
# 初始化语言模型
self.llm = OpenAI(temperature=0.7)
# 创建提示词模板
self.qa_template = PromptTemplate(
template="""
你是一个知识渊博、友善耐心的AI助手。请根据用户的问题提供准确、有帮助的回答。
用户问题:{question}
请用简洁明了的语言回答:
""",
input_variables=["question"]
)
# 创建LLM链
self.qa_chain = LLMChain(
llm=self.llm,
prompt=self.qa_template
)
def ask(self, question):
"""处理用户问题"""
try:
response = self.qa_chain.run(question=question)
return response.strip()
except Exception as e:
return f"抱歉,处理您的问题时出现了错误:{str(e)}"
# 使用示例
if __name__ == "__main__":
bot = SimpleQABot()
# 交互式问答
print("🤖 智能问答助手已启动,输入'quit'退出")
while True:
question = input("\n👤 您的问题:")
if question.lower() == 'quit':
break
answer = bot.ask(question)
print(f"🤖 回答:{answer}")
带记忆的对话机器人
在问答程序的基础上,让我们添加记忆功能,使对话更加自然连贯:
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationChain
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
class MemoryBot:
def __init__(self):
self.llm = OpenAI(
temperature=0.8,
streaming=True,
callbacks=[StreamingStdOutCallbackHandler()]
)
# 创建对话记忆
self.memory = ConversationBufferMemory(
return_messages=True,
memory_key="chat_history"
)
# 创建对话链
self.conversation = ConversationChain(
llm=self.llm,
memory=self.memory,
verbose=True # 显示内部处理过程
)
# 设置个性化的开场白
self.conversation.predict(input="你好,我是你的AI助手,很高兴为您服务!")
def chat(self, message):
"""进行对话"""
try:
response = self.conversation.predict(input=message)
return response
except Exception as e:
return f"对话出现错误:{str(e)}"
def get_conversation_summary(self):
"""获取对话摘要"""
history = self.memory.chat_memory.messages
if not history:
return "暂无对话记录"
return f"对话轮数:{len(history)//2},最后更新:刚刚"
def clear_memory(self):
"""清除对话记忆"""
self.memory.clear()
print("对话记忆已清除")
# 使用示例
if __name__ == "__main__":
bot = MemoryBot()
print("🤖 带记忆的对话机器人已启动")
print("💡 提示:我会记住我们的对话内容哦!")
print("🔧 输入'summary'查看对话摘要,'clear'清除记忆,'quit'退出\n")
while True:
user_input = input("👤 您:")
if user_input.lower() == 'quit':
break
elif user_input.lower() == 'summary':
print(f"📊 {bot.get_conversation_summary()}")
continue
elif user_input.lower() == 'clear':
bot.clear_memory()
continue
print("🤖 机器人:", end="")
response = bot.chat(user_input)
print(f"\n") # 换行
集成工具的智能助手
最后,让我们构建一个集成了多种工具的智能助手,展示Agent的强大能力:
from langchain.agents import initialize_agent, Tool, AgentType
from langchain.tools import DuckDuckGoSearchRun
from langchain.utilities import PythonREPL
from langchain.memory import ConversationBufferMemory
import datetime
class SmartAssistant:
def __init__(self):
self.llm = OpenAI(temperature=0.3)
# 创建工具集
self.tools = self._create_tools()
# 创建记忆
self.memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
# 创建Agent
self.agent = initialize_agent(
tools=self.tools,
llm=self.llm,
agent=AgentType.CHAT_CONVERSATIONAL_REACT_DESCRIPTION,
memory=self.memory,
verbose=True,
max_iterations=3 # 限制推理步骤,避免过长指令
)
def _create_tools(self):
"""创建工具集合"""
# 搜索工具
search = DuckDuckGoSearchRun()
# Python计算工具
python_repl = PythonREPL()
# 时间查询工具
def get_current_time(format_type="详细"):
"""获取当前时间"""
now = datetime.datetime.now()
if format_type == "简单":
return now.strftime("%H:%M")
else:
return now.strftime("%Y年%m月%d日 %H:%M:%S")
# 天气查询工具(模拟)
def get_weather(location="北京"):
"""获取天气信息(模拟)"""
return f"{location}今天天气晴朗,温度20-28℃,空气质量良好"
return [
Tool(
name="网络搜索",
func=search.run,
description="搜索最新的互联网信息,获取实时资讯"
),
Tool(
name="Python计算",
func=python_repl.run,
description="执行Python代码进行计算、数据处理等"
),
Tool(
name="时间查询",
func=get_current_time,
description="获取当前时间,可指定格式:详细或简单"
),
Tool(
name="天气查询",
func=get_weather,
description="查询指定城市的天气情况"
)
]
def assist(self, request):
"""处理用户请求"""
try:
response = self.agent.run(request)
return response
except Exception as e:
return f"处理请求时出现错误:{str(e)}"
def list_capabilities(self):
"""列出助手能力"""
capabilities = [
"🔍 网络搜索 - 获取最新信息",
"🧮 Python计算 - 数学运算和数据处理",
"⏰ 时间查询 - 获取当前时间",
"🌤️ 天气查询 - 查询天气信息",
"💭 智能对话 - 记忆上下文的自然对话"
]
return "\n".join(capabilities)
# 使用示例
if __name__ == "__main__":
assistant = SmartAssistant()
print("🚀 智能助手已启动!")
print("🎯 我的能力包括:")
print(assistant.list_capabilities())
print("\n💡 试试问我:'现在几点了?'、'帮我计算 123*456'、'搜索最新的AI新闻'\n")
while True:
request = input("👤 您的需求:")
if request.lower() == 'quit':
break
print("🤖 正在处理您的请求...\n")
response = assistant.assist(request)
print(f"✅ 完成!结果:{response}\n")
创建简单的Web界面
为了让我们的应用更容易使用,我们可以使用Streamlit快速创建一个Web界面:
import streamlit as st
from langchain.llms import OpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
def create_streamlit_app():
"""创建Streamlit Web应用"""
st.set_page_config(
page_title="LangChain智能助手",
page_icon="🤖",
layout="wide"
)
st.title("🤖 LangChain智能助手")
st.sidebar.title("配置选项")
# 侧边栏配置
temperature = st.sidebar.slider("创造性程度", 0.0, 1.0, 0.7, 0.1)
model_name = st.sidebar.selectbox(
"选择模型",
["gpt-3.5-turbo-instruct", "text-davinci-003"]
)
# 初始化会话状态
if "conversation" not in st.session_state:
llm = OpenAI(temperature=temperature, model_name=model_name)
memory = ConversationBufferMemory(return_messages=True)
st.session_state.conversation = ConversationChain(
llm=llm,
memory=memory
)
st.session_state.messages = []
# 显示对话历史
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# 用户输入
if prompt := st.chat_input("请输入您的问题"):
# 添加用户消息
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
# 生成回复
with st.chat_message("assistant"):
with st.spinner("思考中..."):
response = st.session_state.conversation.predict(input=prompt)
st.markdown(response)
# 添加助手回复
st.session_state.messages.append({"role": "assistant", "content": response})
# 清除对话按钮
if st.sidebar.button("清除对话"):
st.session_state.messages = []
st.session_state.conversation.memory.clear()
st.rerun()
# 运行应用
if __name__ == "__main__":
create_streamlit_app()
运行这个应用非常简单:
streamlit run your_app.py
代码示例已经覆盖了LangChain的基本使用方法。从简单的问答到复杂的智能助手,从命令行交互到Web界面,这些例子涵盖了大部分常见的应用场景。
三、总结与展望
经过这一篇深入的探索,我们全面掌握了LangChain的核心概念和实用技能。让我们快速回顾要点,并展望未来的学习路径。
1. 核心要点回顾
五大组件的价值:
- Models:统一的模型抽象,实现"一套代码,多种模型"
- Prompts:提示词工程的工业化,从硬编码到模板管理
- Chains:流程化的业务逻辑组合,从简单到复杂的渐进式构建
- Agents:自主决策的智能代理,从固定流程到动态推理
- Memory:有记忆的对话系统,从无状态到个性化服务
开发范式转变:
从确定性编程转向概率性编程,从线性流程转向动态推理,从无状态应用转向智能记忆。LangChain不仅是技术工具,更是AI应用开发的方法论。
2. 系列预告
下篇内容:《RAG检索增强生成——让大模型拥有专业知识》
- RAG架构原理与应用场景
- 文档处理到向量检索的完整流程
- 企业级知识问答系统构建实战
完整系列:基础篇(LangChain核心)→ 进阶篇(RAG、Agent、LangGraph)→ 实战篇(生产部署)
LangChain为我们打开了AI应用开发的新世界。掌握它的核心理念,意味着能够将AI技术转化为实际价值。最好的学习方式就是动手实践——现在就开始构建你的第一个LangChain应用吧!
下节预告: RAG —— 为AI注入专业知识的灵魂
更多推荐


 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)