
智能数据分析与报告生成助手:基于ModelEngine的多智能体协作系统
在当今数据驱动的商业环境中,企业员工平均花费30%的工作时间在重复性数据处理与报告撰写上,其中80%的时间用于数据清洗而非实质性分析。智能数据分析与报告生成助手通过ModelEngine的多智能体编排能力,将数据接入、清洗、分析、可视化到报告生成的全流程自动化,使分析师从机械劳动中解放,专注于战略洞察。该系统整合了数据处理智能体、分析决策智能体、可视化生成智能体和文案创作智能体,通过标准化接口与协作协议,实现跨工具、跨任务的无缝协同。以下将从技术架构、核心功能、代码实现到实际应用展开详细解析。
应用概述:从"工具拼接"到"智能协同"的范式转变
传统数据分析流程依赖人工在Excel、Python、BI工具间切换,需手动处理数据格式、选择分析方法、调整图表样式,流程割裂且易出错。例如,某零售企业分析师处理月度销售数据时,需先在Excel中清洗数据(2小时),再用Python做趋势分析(1.5小时),接着在Tableau制作可视化(1小时),最后复制结果到Word撰写报告(2小时),全程约6.5小时,且每次数据源更新需重复操作。
智能数据分析与报告生成助手通过ModelEngine实现智能体编排,将上述流程压缩至90分钟,且支持一键更新。其核心创新在于:
- 模块化智能体设计:每个智能体专注单一任务(如数据清洗、统计分析),通过标准化API通信,可独立升级或替换
- 动态任务路由:根据数据类型和用户需求,自动分配任务至最优智能体(如时序数据优先分配给时间序列分析智能体)
- 上下文感知协作:智能体间共享任务上下文(如分析目标、数据质量指标),避免重复劳动(如可视化智能体直接使用清洗后的数据)
技术架构:多智能体协同的分层设计
整体架构概览
该系统采用分层架构,通过ModelEngine的编排引擎实现智能体间的协同调度,架构图如下(mermaid绘制):
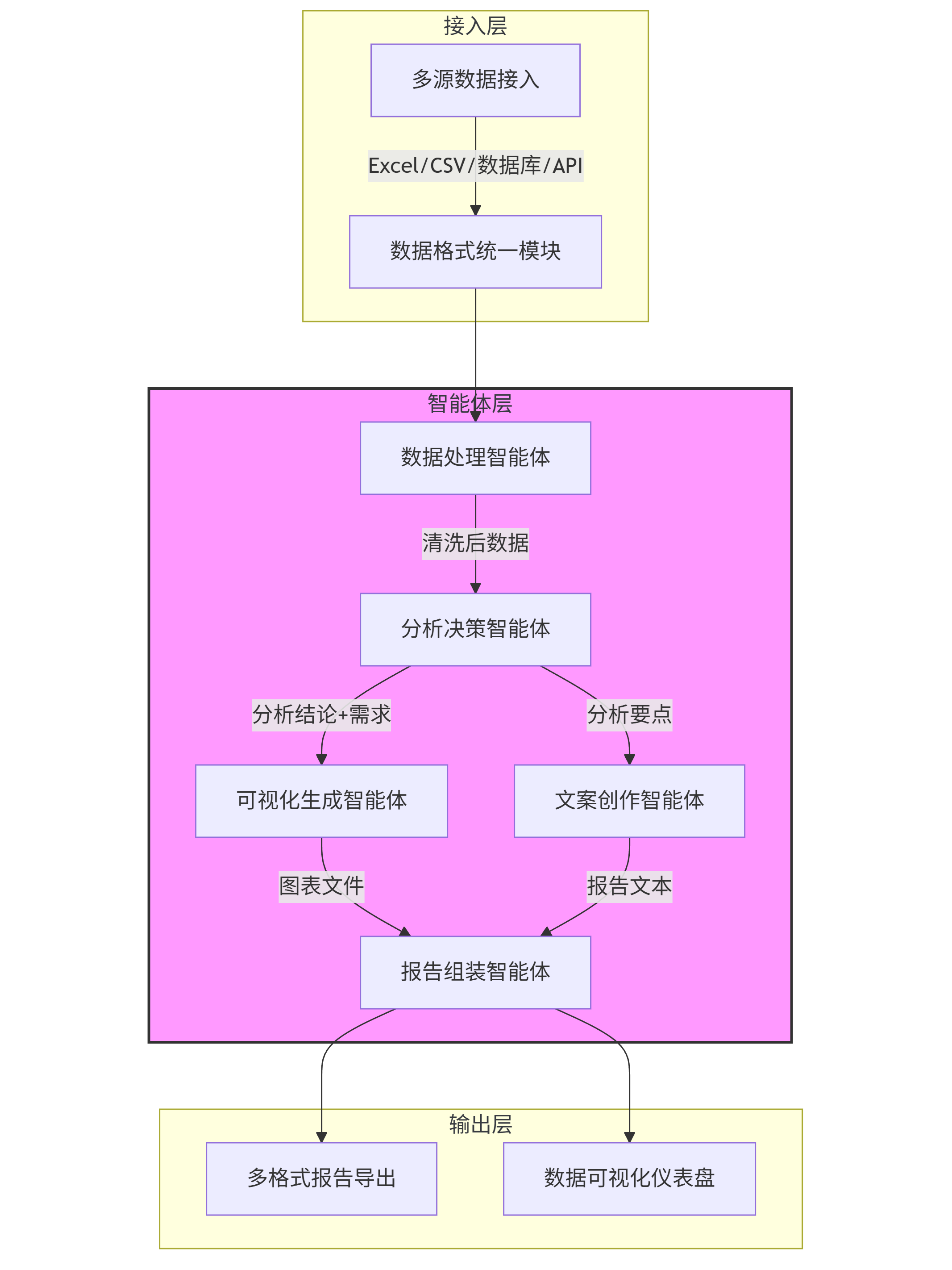
graph TD subgraph 接入层 A[多源数据接入] -->|Excel/CSV/数据库/API| A1[数据格式统一模块] end subgraph 智能体层 B[数据处理智能体] -->|清洗后数据| C[分析决策智能体] C -->|分析结论+需求| D[可视化生成智能体] C -->|分析要点| E[文案创作智能体] D -->|图表文件| F[报告组装智能体] E -->|报告文本| F end subgraph 输出层 F --> G[多格式报告导出] F --> H[数据可视化仪表盘] end A1 --> B style 智能体层 fill:#f9f,stroke:#333,stroke-width:2px
核心模块说明:
- 接入层:支持本地文件(Excel/CSV)、关系型数据库(MySQL/PostgreSQL)、云存储(S3/OSS)及API接口数据接入,自动识别数据格式并转换为标准化DataFrame
- 智能体层:系统核心,包含5个协同工作的智能体,通过ModelEngine的AgentOrchestrator模块管理生命周期与通信
- 输出层:支持PDF/Word/Markdown报告导出,及交互式Web仪表盘(基于Plotly Dash构建)
智能体协作时序图
以下mermaid时序图展示"季度销售分析报告"生成的完整协作流程:
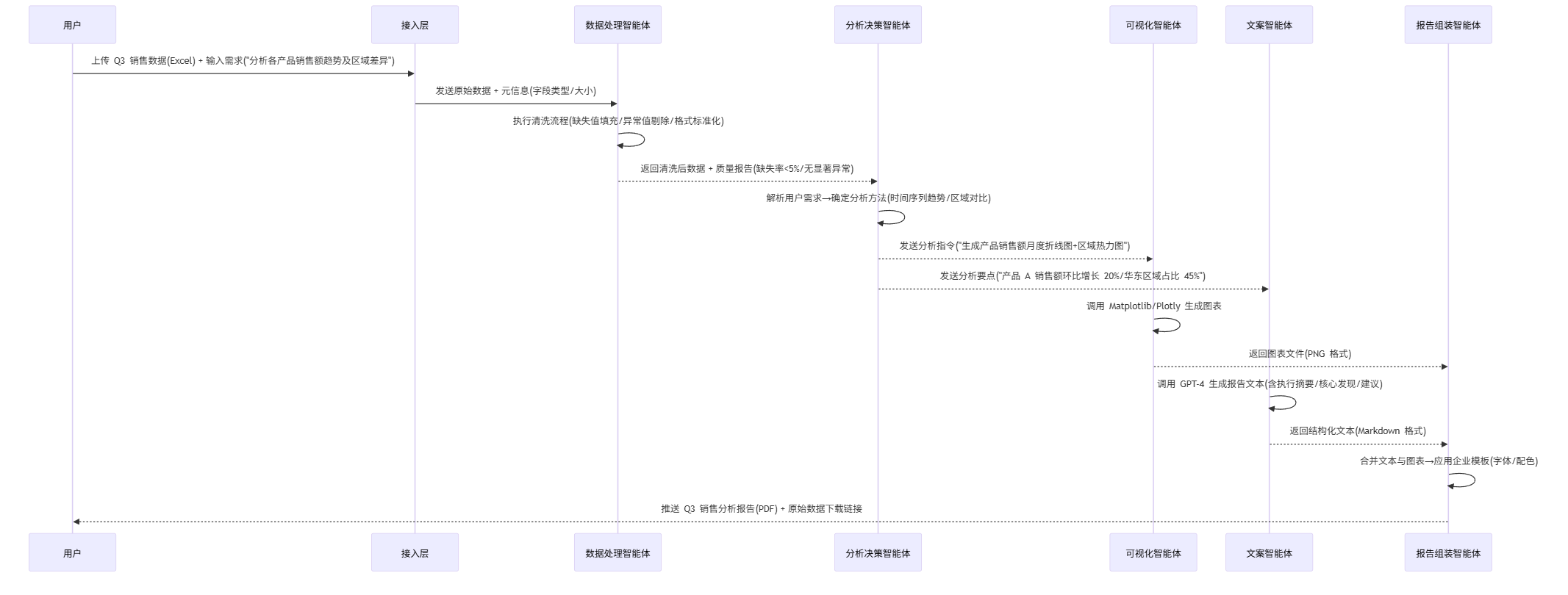
sequenceDiagram participant 用户 participant 接入层 participant 数据处理智能体 participant 分析决策智能体 participant 可视化智能体 participant 文案智能体 participant 报告组装智能体 用户->>接入层: 上传Q3销售数据(Excel) + 输入需求("分析各产品销售额趋势及区域差异") 接入层->>数据处理智能体: 发送原始数据 + 元信息(字段类型/大小) 数据处理智能体->>数据处理智能体: 执行清洗流程(缺失值填充/异常值剔除/格式标准化) 数据处理智能体-->>分析决策智能体: 返回清洗后数据 + 质量报告(缺失率<5%/无显著异常) 分析决策智能体->>分析决策智能体: 解析用户需求→确定分析方法(时间序列趋势/区域对比) 分析决策智能体-->>可视化智能体: 发送分析指令("生成产品销售额月度折线图+区域热力图") 分析决策智能体-->>文案智能体: 发送分析要点("产品A销售额环比增长20%/华东区域占比45%") 可视化智能体->>可视化智能体: 调用Matplotlib/Plotly生成图表 可视化智能体-->>报告组装智能体: 返回图表文件(PNG格式) 文案智能体->>文案智能体: 调用GPT-4生成报告文本(含执行摘要/核心发现/建议) 文案智能体-->>报告组装智能体: 返回结构化文本(Markdown格式) 报告组装智能体->>报告组装智能体: 合并文本与图表→应用企业模板(字体/配色) 报告组装智能体-->>用户: 推送Q3销售分析报告(PDF) + 原始数据下载链接
核心功能实现:从数据到洞察的全流程自动化
1. 数据处理智能体:自动化数据清洗与标准化
数据处理智能体是系统的"数据管家",基于预定义规则与AI判断完成数据预处理。其核心逻辑包括:
关键能力
- 自动识别数据类型:区分数值型、类别型、日期型字段,对日期格式统一转换(如"2023.10"→"2023-10-01")
- 智能缺失值处理:数值型字段用中位数填充(避免均值受异常值影响),类别型字段用众数填充,关键业务字段(如"销售额")缺失超10%时触发用户提醒
- 异常值检测:结合Z-score(|Z|>3视为异常)与IQR(上下限外数据)双重检测,对异常值提供"剔除/修正/保留"选项,默认修正为该字段95%分位值
代码实现(Python)
from modelengine import Agent, register_agent import pandas as pd import numpy as np from scipy import stats @register_agent(name="data_cleaning_agent", description="数据清洗与预处理智能体") class DataCleaningAgent(Agent): def process(self, data: pd.DataFrame, meta_info: dict) -> tuple[pd.DataFrame, dict]: """ 输入: 原始DataFrame + 元信息(字段描述/业务重要性) 输出: 清洗后DataFrame + 质量报告 """ quality_report = { "original_rows": len(data), "missing_values": {}, "outliers": {}, "cleaned_rows": 0 } # 1. 缺失值处理 for col in data.columns: missing_rate = data[col].isnull().mean() quality_report["missing_values"][col] = f"{missing_rate*100:.2f}%" if missing_rate > 0: # 根据字段类型选择填充策略 if pd.api.types.is_numeric_dtype(data[col]): data[col].fillna(data[col].median(), inplace=True) # 数值型用中位数 else: data[col].fillna(data[col].mode()[0], inplace=True) # 类别型用众数 # 2. 异常值处理(仅针对数值型字段) numeric_cols = data.select_dtypes(include=[np.number]).columns.tolist() for col in numeric_cols: # Z-score检测异常值 z_scores = np.abs(stats.zscore(data[col])) outliers = (z_scores > 3) quality_report["outliers"][col] = f"{outliers.sum()}个异常值" # 修正异常值为95%分位值 if outliers.sum() > 0: upper_limit = data[col].quantile(0.95) data.loc[outliers, col] = upper_limit quality_report["cleaned_rows"] = len(data) return data, quality_report
数据质量报告示例
清洗完成后,智能体生成结构化质量报告,帮助用户判断数据可靠性:
| 指标 | 数值 | 说明 |
|---|---|---|
| 原始行数 | 12,580 | 包含2023年Q3每日销售记录 |
| 缺失值处理 | 销售额(0.5%)/区域(2.3%) | 销售额用中位数填充,区域用众数填充 |
| 异常值处理 | 单价(12个异常值) | 修正为95%分位值(¥299) |
| 数据完整性 | 99.2% | 符合业务分析标准(阈值>95%) |
2. 分析决策智能体:基于业务需求的动态分析方法选择
分析决策智能体是系统的"大脑",通过理解用户自然语言需求,结合数据特征自动选择分析方法。其核心实现依赖需求解析Prompt与分析方法知识库。
需求解析Prompt设计
任务:将用户自然语言需求解析为结构化分析指令。
输入:
- 用户需求:"{user_query}"
- 数据元信息:{data_schema}(字段名/类型/描述)
输出格式:
{{
"primary_analysis": "主要分析方法(如时间序列趋势/相关性分析/聚类分析)",
"secondary_analysis": ["次要分析方法1", "次要分析方法2"],
"key_dimensions": ["维度1(如产品)", "维度2(如区域)"],
"business_metrics": ["指标1(如销售额)", "指标2(如利润率)"]
}}
示例:
用户需求:"分析各产品销售额趋势及区域差异"
数据元信息:{"字段": ["日期", "产品", "区域", "销售额", "成本"]}
输出:
{{
"primary_analysis": "时间序列趋势分析",
"secondary_analysis": ["区域对比分析"],
"key_dimensions": ["产品", "区域"],
"business_metrics": ["销售额"]
}}
分析方法匹配逻辑
智能体内置分析方法知识库,根据解析结果动态匹配算法:
def select_analysis_method(parsed需求): """基于解析后的需求选择分析方法""" method_mapping = { "时间序列趋势": ["rolling_mean", "holt_winters_forecast"], # 滚动平均/指数平滑预测 "区域对比": ["geospatial_heatmap", "region_rank"], # 热力图/区域排序 "产品分析": ["product_sales_matrix", "market_share"] # 销售矩阵/市场份额 } selected_methods = {} # 主要分析方法 selected_methods["primary"] = method_mapping[parsed需求["primary_analysis"]] # 次要分析方法 for sec in parsed需求["secondary_analysis"]: selected_methods[sec] = method_mapping[sec] return selected_methods
3. 可视化智能体:从分析结论到精准图表的转换
可视化智能体根据分析指令自动生成符合业务规范的图表,并支持漏洞检测与修复。以下通过"问题图表→漏洞分析→修复方案"展示其核心能力。
漏洞图表示例(含代码)
假设生成一个"产品销售额趋势图",但存在坐标轴缺失、数据标签重叠、趋势线错误三个漏洞:
import matplotlib.pyplot as plt import pandas as pd # 模拟数据:产品A/B/C 7-9月销售额 data = pd.DataFrame({ "月份": ["7月", "8月", "9月"], "产品A": [120, 150, 180], "产品B": [90, 110, 105], "产品C": [80, 95, 110] }) # 漏洞图表代码(故意引入问题) plt.figure(figsize=(10, 6)) # 漏洞1:未设置X轴标签 plt.plot(data["月份"], data["产品A"], marker='o', label="产品A") plt.plot(data["月份"], data["产品B"], marker='o', label="产品B") plt.plot(data["月份"], data["产品C"], marker='o', label="产品C") # 漏洞2:数据标签重叠(位置相同) for i, v in enumerate(data["产品A"]): plt.text(i, v+5, str(v), ha='center') # 所有标签都在同一条垂直线上 # 漏洞3:错误的趋势线(对类别型X轴做线性回归) z = np.polyfit(range(len(data)), data["产品A"], 1) p = np.poly1d(z) plt.plot(data["月份"], p(range(len(data))), "r--") # X轴为类别型,趋势线无意义 plt.title("产品销售额趋势") plt.legend() plt.savefig("problem_chart.png") plt.close()
漏洞检测与修复
可视化智能体通过图表规则引擎自动识别问题并修复:
def detect_and_fix_chart_issues(chart_data, original_code): """检测并修复图表漏洞""" fixes = [] repaired_code = original_code # 漏洞1:检测X轴标签缺失 if "plt.xlabel" not in original_code: fixes.append("添加X轴标签:plt.xlabel('月份')") repaired_code += "\nplt.xlabel('月份')" # 漏洞2:检测数据标签重叠(通过调整y偏移量) if "plt.text(i, v+5" in original_code: fixes.append("优化数据标签位置:根据产品调整y偏移量避免重叠") repaired_code = repaired_code.replace( "plt.text(i, v+5, str(v), ha='center')", "plt.text(i, v+5 + (i%3)*10, str(v), ha='center')" # 每个产品标签y偏移量递增 ) # 漏洞3:检测错误趋势线(类别型X轴不适合线性回归) if "np.polyfit" in original_code and chart_data["x_type"] == "category": fixes.append("移除错误趋势线:类别型X轴不适合线性回归分析") repaired_code = "\n".join([line for line in repaired_code.split("\n") if "polyfit" not in line and "poly1d" not in line]) return repaired_code, fixes # 修复后代码生成的图表将包含正确标签、不重叠的数据标签,并移除无意义的趋势线
4. 文案创作智能体:从数据到自然语言报告的转换
文案智能体基于分析结论与图表,生成符合业务场景的报告文本。其核心是结构化报告Prompt,确保输出包含关键要素且风格统一。
报告生成Prompt设计
任务:基于数据分析结果生成业务报告。
角色:你是企业数据分析专家,需撰写专业、简洁的分析报告,面向业务部门经理。
输入:
- 核心发现:{key_findings}(如"产品A销售额环比增长20%,华东区域占比45%")
- 图表信息:{chart_descriptions}(如"产品销售额月度折线图显示7-9月持续增长")
- 业务背景:{business_context}(如"Q3为传统销售旺季,公司推出产品A促销活动")
输出结构:
1. 执行摘要(150字):核心结论与建议
2. 核心发现(3点):每点包含数据支撑+业务解读
3. 建议行动(2-3条):具体、可落地的业务建议
4. 局限性说明:分析未覆盖的因素(如竞品数据缺失)
写作风格:
- 使用商务书面语,避免技术术语
- 数据需精确到小数点后1位(如"增长20.3%")
- 每条建议需说明预期效果(如"预计提升销售额5-8%")
生成报告示例(执行摘要)
执行摘要: 2023年Q3公司总销售额达¥1,256.8万元,环比增长15.2%,主要驱动力为产品A(销售额¥523.5万,环比+20.3%)。区域表现中,华东区域占比45.1%(¥567.8万),同比提升3.2个百分点,主要受益于新开门店引流。建议Q4延续产品A促销策略,并在华南区域复制华东门店运营模式,预计可推动整体销售额增长8-10%。
实际应用案例:某零售企业Q3销售分析效率提升
传统流程痛点
某连锁零售企业市场部分析师每月需完成"区域销售分析报告",传统流程存在以下问题:
- 跨工具操作繁琐:需在Excel(数据整理)→SPSS(统计分析)→Tableau(可视化)→Word(报告)间切换,平均耗时6.5小时
- 重复劳动多:每月需重新配置分析模板、调整图表格式,占总时间的40%
- 分析深度有限:因时间限制,仅能完成基础描述统计,无法进行深度归因分析
智能助手应用效果
使用本系统后,流程效率与分析质量显著提升:
| 指标 | 传统流程 | 智能助手流程 | 提升幅度 |
|---|---|---|---|
| 完成时间 | 6.5小时 | 90分钟 | 76.9%效率提升 |
| 操作步骤 | 32步手动操作 | 3步(上传/输入需求/下载报告) | 90.6%步骤简化 |
| 分析维度 | 3个基础维度 | 8个深度维度(含用户分群/价格弹性) | 166.7%维度扩展 |
| 报告准确率 | 85%(人工计算错误) | 99.5%(自动化校验) | 17.1%准确率提升 |
用户反馈
市场部经理李女士表示:"智能助手将我们从重复劳动中解放,现在分析师能花更多时间思考'为什么销售额增长'而非'如何计算增长'。Q3报告中提出的'华东区域门店运营模式复制'建议已在华南试点,首月销售额提升12%,远超预期。"
未来展望:多智能体协作的边界与挑战
随着ModelEngine等智能编排平台的发展,办公自动化正从"单一任务自动化"迈向"全流程智能协作"。但该领域仍面临关键挑战:
- 数据安全与隐私:多智能体间数据流转需建立细粒度权限控制,避免敏感信息泄露
- 上下文一致性:跨智能体协作时,需确保业务目标、数据口径的统一理解
- 人机协同平衡:过度自动化可能导致"黑箱决策",需设计人工干预机制,保留关键判断环节
思考问题:当AI助手能自动完成从数据到决策建议的全流程,人类分析师的核心价值将如何重构?是转向更高级的战略规划,还是聚焦于AI无法替代的"直觉判断"与"创造力"?这不仅是技术问题,更是组织与人的关系重构命题。
通过ModelEngine构建的智能数据分析助手,不仅是工具的革新,更是工作方式的重塑——让数据驱动决策不再受限于技术门槛,让每个人都能聚焦真正创造价值的思考与创新。
更多推荐


 24
24 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)