
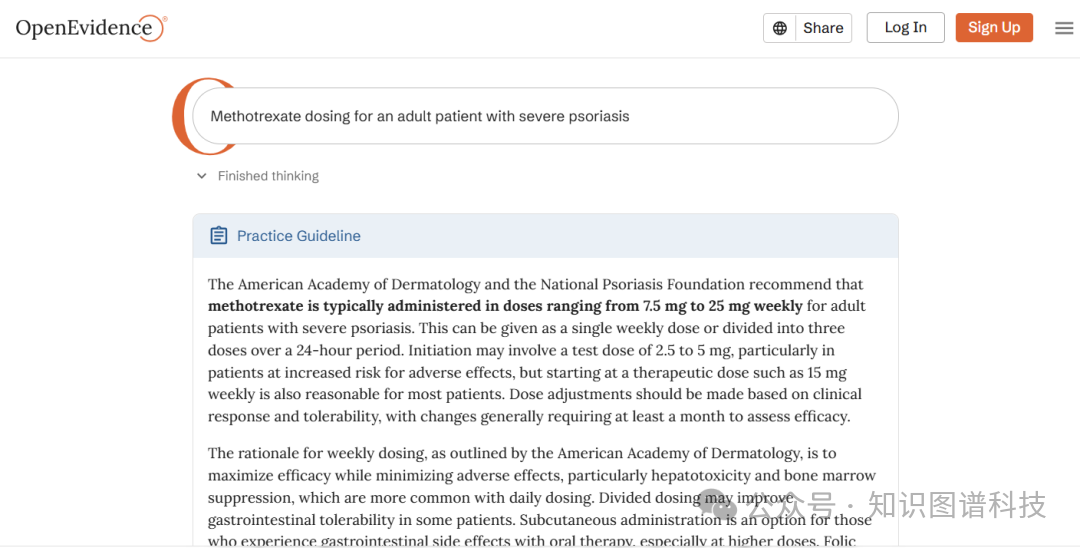
200亿估值AI医生上岗!美国40%医生都在用,连USMLE都考过了!
AI医疗公司OpenEvidence获2.1亿美元B轮融资,估值达35亿美元。该公司由哈佛经济学博士Daniel Nadler创立,专注开发临床级AI诊断工具。其突破性创新在于构建了首个"知识溯源"医疗AI系统,通过多智能体协作架构实现专业级医学推理,在USMLE模拟测试中准确率超90%。核心技术包括:LoRA轻量精调、人类数据飞轮、多智能体协作(分设检索/摘要/综合/安全代理

摘要&前言:
近日,AI医疗公司OpenEvidence获得了2.1亿美元的B轮融资,估值飙升至35亿美元(约合人民币251亿元)。OpenEvidence成立于2022年,总部位于美国迈阿密,致力于为医生提供临床级诊断工具。公司由Daniel Nadler创办,他是一名哈佛大学经济学博士,也是一位非常成功的连续创业者。曾经创立了知名AI金融公司Kensho并被标普以5.5亿美元收购。
本文深入解读通过USMLE(美国医师执照考试)的临床级大模型OpenEvidence如何为医疗领域带来革命性变革。文章详细拆解其架构创新、数据飞轮、模型精调与安全可信机制,并展望这一技术范式向法律、金融、网络安全等高风险领域复制的可能性。阅读后,你将理解“以证据为本”的智能是医疗等高风险行业AI落地的未来。

1. 场景设定:凌晨2点的急诊室
一位患有心房颤动且合并复杂基础病的患者被送至急诊。主治医生面对两种抗凝药物的选择,标准指南虽明确,但最新发表(仅一个月前)的研究论文提示:对于该患者特定遗传标记,应采用另一种方案。这篇论文是当日全球新发4000篇生物医学文献之一,要在有限时间内准确找到、阅读并解释其临床意义,几乎不可能。
这正是2025年各类高风险专业的普遍危机:数据淹没,洞察匮乏。
通用型大语言模型(LLM)或许能为我们提供某种“救命稻草”,但也暗藏风险。
在当前跨高风险领域的 LLM 部署浪潮中,OpenEvidence 脱颖而出,成为第一个为现实世界的医疗保健工作流程构建的可靠临床推理系统。与依赖随机流畅性的通用模型不同,OpenEvidence 的结构是为认识可追溯性而构建的:每个答案都基于检索到的、经过同行评审的证据,通过研究设计进行过滤,并通过领域微调推理引擎进行综合。
2. OpenEvidence:医疗领域的首个可信推理系统
OpenEvidence以临床现实工作流为导向,强调“知识溯源”,区别于依赖“流畅言辞”的通用模型。每一个答案都基于可检索的、同行评议的证据,按研究设计过滤,并通过行业化优化的推理引擎综合得出。
在模拟USMLE Step 2临床病例、多项选择题测试中,OpenEvidence准确率超90%。虽然并非真实考场,但这些受控评测模拟了医生在不确定环境下的决策力——成绩甚至和持证医生相当。
更核心的竞争力,其实是信息筛选和证据提取的极致效率。

3. 架构创新:专科大模型的崛起
3.1 通用型与专科型之分
GPT-4、LLaMA等模型是“语言全才”,但难以胜任专业推理。例如问及具体药物交互,通用LLM可能会“幻觉”出不存在的论文,甚至误解重要药理机制,给出“自信而致命”的建议。
终极分岔:用提示微调通才,还是重铸其“神经网络”成专业选手?OpenEvidence选择了后者。
3.2 为什么“RAG检索增强”远远不够
RAG(Retrieval-Augmented Generation)——即为LLM接入动态学术数据库,让它在回答问题时可检索海量文献。但要是“学生”根本看不懂专业论文,检索再准也无用。例如:“A药患者能否安全服用B药吗?”
-
检索:RAG 系统正确检索了两份文件:药物 B 的临床试验显示出低副作用,以及一篇指出药物 A 是 CYP3A4 酶的有效抑制剂的药理学论文。
-
生成(失败):仿制药法学硕士看到药物B试验呈阳性,不了解神秘的药理学,自信地回应道:“是的,根据临床试验数据,药物B总体耐受性良好。
-
检索正确论文后,通用LLM却忽视了A药严重抑制B药代谢的风险,导致毒性过量,给出错误判断。这种情况下,RAG带来了信息,但通用模型缺乏专业理解。
3.3 精调与“人类数据飞轮”
对LLM的精调不是“死记硬背”,而是通过领域数据微调其概率分布,让推理方式趋近行业专家。
大规模高质量“专家数据”难以依靠人工。OpenEvidence首创“人-机循环”数据飞轮:用强大的通用LLM先生成大批Q&A,由专家快速验证/修正,再反哺模型精调。新一轮模型又更擅长生成高质量数据,形成正向飞轮。
3.4 LoRA轻量精调,“多脑可插拔”
传统全参精调像“锤子砸脑子”,易遗忘通识能力且算力成本惊人。OpenEvidence采用LoRA(低秩适配)——只对模型部分参数注入可训练小矩阵,实现高效、可控、微损耗的领域微调。不止成本低,还可快速切换“多科专家大脑”。
技术公式:
W = W₀ + BA
(W₀为原模型权重,B与A为小型自适应矩阵,通常仅需训练总参数的0.1%)
4. 第二代架构:多智能体协作
OpenEvidence已超越RAG+精调,全面引入多智能体(Multi-Agent)协作,每个子智能体各司其职:
-
调度员代理(Dispatcher):解析用户意图,分流到不同工作链条。接收初始查询并确定用户的意图。这是关于治疗效果、副作用或作用机制的问题吗?它将任务路由到相应的工作流。
-
检索代理(Retrieval):多库检索(如PubMed、ClinicalTrials、院内知识库),理解各自检索语法
-
摘要代理(Summarization):将检索到的复杂文献抽取为结构化摘要(如受试者规模、p值、主要结论等)
-
综合代理(Synthesis):这是核心的、经过 LoRA 调整的“专家推理器”。它看不到完整、凌乱的文档。它只看到 Summarizer 中干净、结构化的摘要,使其能够在多项研究中比较苹果,并综合出连贯的、基于证据的答案。只接收结构化摘要,比较多篇证据,输出严谨推理结论
-
安全代理(Safety):全流程末端校验,不允许未被证实的信息或暗示
这种“模块化专科团队+专家大脑”方式,比单一大模型更稳健、可解释、易扩展。
5. 信任架构:合规AI与Red Team攻防
-
Constitutional AI(合规人工智能)
先制定“宪法”原则(如不直接给诊断建议仅提供引文证据;必声明证据局限性例如,样本量小、非随机试验;碰到证据矛盾不站队),再让一个AI写答案,另一个AI严格依照合规要求批评指正,强化安全与透明。 -
专业Red Team攻击测试
组建专家“黑客团队”,专门设计容易诱使AI出错的测试题,持续迭代安全边界。这也是高风险领域最有效的安全机制。 -
源数据溯源
每条输出均严密追溯到有时戳的学术来源,杜绝“幻觉”造假,真正实现“以证据为依据”。
6. 蓝图复制:法律、金融、网络安全下一个风口
-
法律行业
专有代理监控最新判例、识别活案冲突,宪法规定严禁主动给出法律建议,仅可说明“某判例为约束性先例”等。 -
网络安全
模型专精CVEs和事故日志,主动预警新威胁,如:“检测到与Cobalt Strike相关的新C2服务器IP,已于过去24小时映射你的服务器流量。” -
金融领域
对SEC公告、财报电话会转录精调,主动推送如“企业最新8-K披露新债务条款,可能影响并购扩张”的动态,坚守“不做投资建议”红线。
7. 总结:从医学检索问答工具到真正数字智能分身
OpenEvidence代表了企业级大模型飞跃的四个阶段:
- Phase 1(全才模型):
智能玩具
- Phase 2(RAG):
信息搜索引擎
- Phase 3(RAG+精调):
拥有专业推理力的助手
- Phase 4(多智能体&宪法AI):
安全、可信、协作式专家系统


真正的终局,是从被动响应转向主动预警的数字孪生体。系统自动追踪海量上下文,针对你的患者、案件、网络环境,主动推送关键信号,实现“危中见机”。

OpenEvidence证明了面向“高证据可追溯性”的智能已可落地——而这只会加速蔓延至每一个高风险专业。
8.大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

更多推荐


 25
25 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)