
DocAgent:一种用于自动生成代码文档的多智能体系统
高质量的代码文档对于软件开发至关重要,尤其是在人工智能时代。然而,使用大型语言模型(LLMs)自动生成它仍然具有挑战性,因为现有的方法通常会产生不完整、无用或事实错误的输出。我们引入了DocAgent,这是一种新颖的多智能体协作系统,采用拓扑代码处理以逐步构建上下文。专门的智能体(Reader、Searcher、Writer、Verifier、Orchestrator)随后协同生成文档。我们还提出
Dayu Yang <{ }^{<}< Antoine Simoulin †{ }^{\dagger}† Xin Qian †{ }^{\dagger}† Xiaoyi Liu †{ }^{\dagger}† Yuwei Cao †{ }^{\dagger}† Zhaopu Teng †{ }^{\dagger}† Grey Yang Meta AI
{dayuyang, antoinesimoulin, xinqian, xiaoyiliu, yuweicao, zhaoputeng, glyang}@meta.com
摘要
高质量的代码文档对于软件开发至关重要,尤其是在人工智能时代。然而,使用大型语言模型(LLMs)自动生成它仍然具有挑战性,因为现有的方法通常会产生不完整、无用或事实错误的输出。我们引入了DocAgent,这是一种新颖的多智能体协作系统,采用拓扑代码处理以逐步构建上下文。专门的智能体(Reader、Searcher、Writer、Verifier、Orchestrator)随后协同生成文档。我们还提出了一种多方面的评估框架,评估完整性、有用性和真实性。全面的实验表明,DocAgent在各个方面显著优于基线方法。我们的消融研究证实了拓扑处理顺序的关键作用。DocAgent为复杂和专有存储库中的可靠代码文档生成提供了一种强大的方法。我们的代码1{ }^{1}1 和视频2{ }^{2}2 是公开可用的。
1 引言
高质量的代码文档对于有效的软件开发至关重要(De Souza 等人,2005;Garousi 等人,2015;Chen 和 Huang,2009),随着AI模型依赖于准确的docstring进行代码理解任务(Zhou 等人,2022;Yang 等人,2024;Anthropic,2025),其重要性日益增加。然而,创建和维护文档是一项劳动密集型工作,并且容易出错(McBurney 等人,2017;Parnas,2010)。即使是在GitHub上获得顶级星标的开源存储库,也常常表现出低覆盖率和质量的docstring,4{ }^{4}4 导致文档经常
落后于代码变更(Aghajani 等人,2019;Robillard,2009;Uddin 等人,2021)。
尽管基于LLM的解决方案——例如Fill-in-the-Middle(FIM)预测器(Roziere 等人,2023;GitHub,2024)和聊天代理(Meta,2025;OpenAI,2022)——提供了自动化,但广泛的研究(Dvivedi 等人,2024;Zhang 等人,2024;Zan 等人,2022;Zheng 等人,2024)以及我们的实证分析($4)揭示了三个反复出现的局限性。首先,这些方法经常遗漏关键信息(例如参数或返回值描述)。其次,它们通常提供的上下文或理由最少,限制了生成文档的实用性。第三,它们有时会幻想不存在的组件,特别是在大型或专有存储库中,损害了事实准确性(Zan 等人,2022;Ma 等人,2024;Abedu 等人,2024)。
我们确定了导致这些缺点的三个主要挑战。(1)上下文识别和检索:大型、复杂的存储库使得很难确定哪些文件、依赖项或外部参考与给定组件真正相关。(2)导航复杂依赖项:代码库经常表现出超出典型LLM上下文限制的依赖链,需要战略性地管理上下文。(3)稳健和可扩展的评估:现有的评估指标如BLEU或ROUGE(Roy 等人,2021;Guelman 等人,2024)不能完全捕捉文档的多方面目标,而人工评估虽然更可靠,但昂贵且主观(Luo 等人,2024)。
为了解决这些挑战,我们介绍了DocAgent,这是一个多智能体系统,按照拓扑排序顺序处理代码,并利用专门的智能体(Reader、Searcher、Writer、Verifier、Orchestrator)协同生成文档。这模仿了人类的工作流程并有效地管理上下文。我们还提出了一个自动且稳健的多方面评估
${ }^{1}$ 对应作者。
${ }^{1}$ 贡献相等。
${ }^{1}$ 代码目前正在进行法律审查。很快将更新。
${ }^{2}$ https://youtu.be/e9Ij0bGe9_1
${ }^{3}$ 在本文中,我们交替使用“代码文档”和“docstring”。
${ }^{4}$ 有关更多详细信息,请参阅附录C。

图1:DocAgent架构:(1) 导航模块使用AST解析进行依赖DAG和拓扑遍历。(2) 多智能体框架使用专门的智能体(Reader、Searcher、Writer、Verifier)生成上下文感知的文档。
框架通过确定性检查和LLM-as-judge评估完整性、有用性和真实性。我们的主要贡献是:1)DocAgent,一个多智能体、拓扑结构化的系统,用于上下文感知的文档生成。2)一个稳健的评估框架,衡量代码文档的完整性、有用性和事实一致性。3)在不同存储库上的全面实验表明,DocAgent始终显著优于最先进的基线方法。
2 方法论
DocAgent分两个阶段运行,以处理复杂的依赖关系并确保上下文的相关性。首先,导航器确定最优的依赖感知处理顺序(§2.1)。其次,多智能体系统逐步生成文档,利用专门的智能体进行代码分析、信息检索、起草和验证(§2.2)。图1说明了这一架构。
2.1 导航器:依赖感知顺序
生成准确的文档通常需要理解其依赖关系。然而,天真地包括所有直接和传递依赖关系的完整上下文很容易超过上下文窗口限制,特别是在大型、复杂的存储库中。为了解决这个问题,导航器模块建立了一个处理顺序,确保只有在处理完其依赖项之后才对组件进行文档化,从而实现增量上下文构建。
依赖图构建。DocAgent首先对整个目标存储库进行静态分析。它解析源文件的抽象语法树(ASTs),以识别代码组件(函数、方法、类)及其相互依赖关系。这些依赖关系包括函数/方法调用、类继承、属性访问和模块导入。这些组件和关系用于构造一个有向图,其中节点表示代码组件,从A到B的有向边表示A依赖于B(A→B\mathrm{A} \rightarrow \mathrm{B}A→B)。为了启用拓扑排序,使用Tarjan算法(Tarjan,1972)检测图中的循环并将它们压缩成一个超级节点。这产生了一个有向无环图(DAG),表示存储库的依赖结构。
该过程从整个目标存储库的静态分析开始。解析所有源文件的抽象语法树(ASTs),以识别核心代码组件(例如,函数、方法、类)及其相互依赖关系。这些依赖关系包括函数/方法调用、类继承关系、属性访问和模块导入。基于此分析,构造一个有向图,其中节点代表代码组件,从组件A到组件B的有向边(A→B\mathrm{A} \rightarrow \mathrm{B}A→B)表示A依赖于B(即,必须理解B才能完全理解A)5{ }^{5}5。
按层次生成的拓扑遍历。使用DAG,导航器执行拓扑排序以确定文档生成顺序。遍历遵循“先依赖”的原则:仅在处理完所有直接依赖的组件后才处理某个组件6{ }^{6}6。这种拓扑排序确保了,在多智能体系统为给定组件生成文档时,
${ }^{5}$ 使用Tarjan算法(Tarjan,1972)检测图中的循环并将其压缩成一个节点。
${ }^{6}$ 方法在其包含的类之前被记录。

图2:DocAgent实时代码文档生成页面的截图。
所有的依赖关系都已经描述过。因此,每个代码文档只需要其一跳依赖的信息,无需拉取不断增长的背景信息链。
2.2 多智能体文档生成
按照导航器的顺序,多智能体系统使用四个由协调器协调的专业智能体为每个组件生成文档。输入是焦点组件的源代码,包括新生成的文档。
阅读器。阅读器智能体通过分析焦点组件的代码启动过程。其主要目标是确定生成全面且有用的代码文档所需的信息。它评估组件的复杂性、可见性(公共/私有)和实现细节,以决定:是否需要额外的上下文信息:简单的、自包含的组件可能不需要外部信息。需要什么上下文信息:这涉及识别特定的内部依赖(使用的函数/类)、使用上下文(组件被调用的地方,揭示其目的)或隐式或显式引用的外部概念(算法、库、领域知识)。
该智能体输出两种类型的信息请求的结构化XML请求(1)关于相关代码组件的内部信息,以及(2)针对专门算法或技术的外部知识。
内部信息请求包括依赖和参考。依赖意味着焦点组件调用了存储库中定义的其他组件,其中阅读器将确定是否需要依赖项以提供必要的上下文信息。
参考意味着焦点组件在代码存储库中的某处被调用,显示它如何在实际应用中使用,
因此揭示焦点代码组件的目的。这对于暴露给存储库用户的公共函数或API尤为重要。
外部请求针对无法直接从代码库中获取或推断的信息,例如特定领域的知识或第三方库功能(见附录B)。
搜索器。搜索器智能体负责使用专用工具满足阅读器的信息请求:内部代码分析工具:该工具利用静态分析能力导航代码库。它可以检索指定内部组件的源代码和现有文档,识别焦点组件的调用站点,使用预计算的图或即时分析跟踪依赖关系,并提取相关的结构信息(例如,类层次结构、方法签名)。外部知识检索工具:该工具通过通用检索API与外部知识源接口。它根据阅读器对外部概念的请求制定查询,并处理结果以提取相关的解释、定义或描述。
搜索器将检索到的内部代码信息和外部知识整合为结构化格式,作为后续智能体的上下文。
就像两个人工智能体在项目上合作并互相交谈一样,搜索器将检索到的信息发送回阅读器后,阅读器读取更新后的上下文和焦点代码组件,并查看上下文是否足以生成文档。如果阅读器仍然觉得检索到的上下文还不够充分,阅读器可以进一步向搜索器发送信息请求。因此,信息请求和新信息可以在阅读器和搜索器之间来回传递,直到检索到足够的信息为止。
写作者。写作者智能体接收焦点组件的代码和搜索器编译的结构化上下文。其任务是生成代码文档。生成过程由提示引导,提示根据组件类型指定所需的结构和内容:函数/方法:通常需要摘要、扩展描述、参数描述(Args)、返回值描述(Returns)、引发的异常(Raises)以及潜在的使用示例(特别是面向公众的组件)。类:通常需要摘要、扩展描述、初始化示例、构造函数参数描述(Args)和公共属性描述(Attributes)。
写作者综合来自代码和所提供上下文的信息,生成符合这些要求的草稿代码文档。
验证者。验证者接受写作者生成的上下文、代码组件和生成的代码文档作为输入,根据预定义的标准评估代码文档的质量:信息价值、详细程度和完整性。经过评估后,验证者要么批准文档,要么通过结构化反馈提供具体的改进建议。
如果问题可以在没有额外上下文信息的情况下解决,例如格式问题,可以通过要求写作者重写来轻松解决,则验证者可以与写作者沟通。
如果问题是由于缺乏信息而需要额外的上下文,则验证者也可以向阅读器提供建议,并通过另一个阅读器-搜索器周期收集额外的信息。
协调器。协调器通过迭代过程管理智能体的工作流程。循环从阅读器分析焦点组件并请求必要的上下文开始。搜索器收集此信息,然后写作者生成文档字符串。验证者随后评估文档字符串的质量,要么批准它,要么将其退回修改。此过程持续进行,直到生成令人满意的代码文档或达到最大迭代次数。
自适应上下文管理:为了处理搜索器可能检索到的大量上下文,特别是对于复杂组件,协调器实施了一种自适应上下文截断机制。它监控提供给写作者的上下文的总标记数。如果上下文超过了可配置的阈值(基于底层LLM的限制),协调器应用有针对性的截断策略。它识别结构化上下文中最大的部分(例如,外部知识片段、特定依赖详情),并选择性地从这些部分的末尾删除内容以减少标记数,同时保留整体结构。这确保上下文保持在操作限制内,平衡上下文丰富度与模型约束。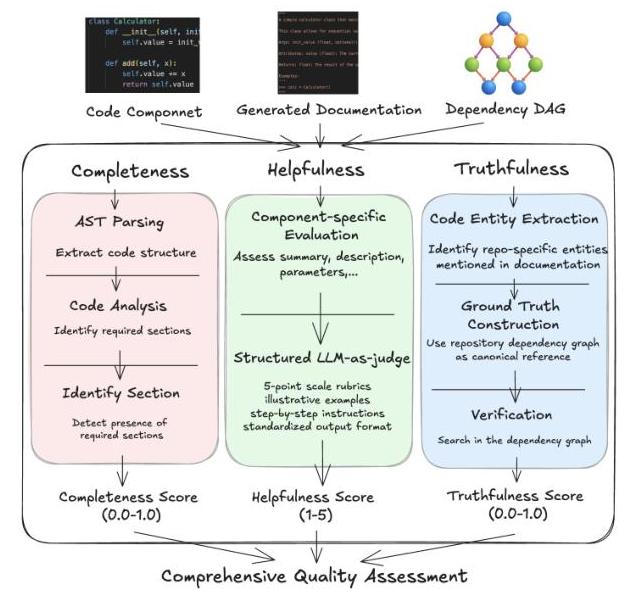
图3:代码文档的多维度评估框架,从三个维度评估质量:(1)完整性衡量对文档约定的结构遵循程度;(2)有用性评估实际效用;(3)真实性验证事实准确性。
3 评估框架
评估自动生成代码文档的质量具有挑战性。传统的自然语言生成常用指标,如BLEU或ROUGE,因缺乏黄金参考而无法使用(Roy et al., 2021; Guelman et al., 2024)。简单的启发式指标如文档长度不足以反映实际效用。尽管人工评估提供了最准确的评估(Luo et al., 2024),但它本质上是主观的、昂贵的且难以扩展,使其不适合大规模实验或持续集成场景。
为克服这些限制,我们提出了一种全面且可扩展的评估框架,旨在系统地从三个关键维度评估文档质量:完整性、有用性和真实性。这种多维度方法结合了确定性的结构检查、基于LLM的定性评估和对代码库本身的事实核查,提供了生成文档价值的整体视图。我们的方法论借鉴了软件工程中已建立的最佳文档实践,并解决了现有基于LLM的生成系统观察到的具体不足。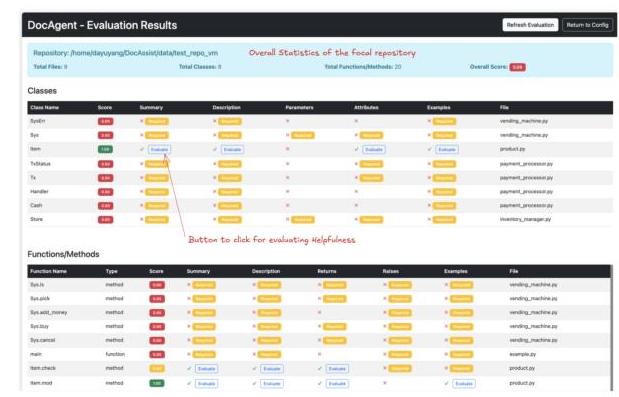
图4:DocAgent实时评估框架的截图
3.1 完整性
完整性衡量生成的文档在多大程度上遵守标准结构约定,并包含给定代码元素(例如,函数、类)预期的基本组件。高质量的代码文档通常不仅包括摘要,还包括参数、返回值、引发异常的描述,以及潜在的使用示例,具体取决于元素的签名、主体和可见性。
为了量化完整性,我们采用基于抽象语法树(AST)分析和正则表达式的自动化检查器。该过程包括:AST解析:识别代码组件(类、函数、方法)并提取其生成的docstrings。代码分析:分析代码签名和主体(例如,参数的存在、返回语句、引发语句)以及可见性(公共/私有),以动态确定所需的文档部分。例如,一个没有参数的函数不需要"Args"部分,而一个公共类方法可能比私有辅助函数更受益于"Example"部分。部分识别:使用预定义模式和结构线索检测docstring中是否存在标准部分(例如,Summary、Description、Args、Returns、Raises、Examples、Attributes for classes)。评分:计算每个docstring的完整性分数,作为存在部分的比例。这产生了一个归一化的0.0到1.0之间的分数。
这种确定性方法提供了一个客观的结构遵守度量,指示文档是否满足基本形式要求。
3.2 有用性
有用性评估文档内容的语义质量和实际效用。一个有用的docstring不仅仅重述代码元素;它阐明了代码的目的、使用上下文、设计原理和潜在的约束条件。关键方面包括:清晰和简洁:总结是否信息丰富但简短?描述深度:扩展描述是否提供了足够的上下文,解释代码背后的"为什么"或提及相关场景或边缘情况?参数/属性效用:输入和属性的描述是否有意义,指定预期类型、值范围或约束,而不是仅仅重复名称?指导:文档是否有效地指导开发者何时以及如何使用组件?
自动评估这些定性方面具有挑战性。受最近关于评估复杂生成任务工作的启发(Wang et al., 2024; Zhuge et al., 2024),我们采用了LLM-as-judge方法,精心设计以增强稳健性和一致性。为减轻与LLM判断相关的潜在偏差和变化,我们实施了一个复杂的框架:组件特定评估:我们通过分别评估docstring的不同部分(例如,摘要、主要描述、参数描述)来分解评估,使用为每部分定制的提示。结构化提示工程:每个提示包括:1)明确的评分标准:详细的五点李克特量表评分标准(1=差到5=优秀),定义每个评分级别的清晰度、深度和实用性的期望。2)示例说明:对应不同评分级别的良好和不良文档片段的具体示例,使评估标准具体化。3)逐步指示:引导LLM分析代码,将docstring与评分标准进行比较,考虑代码的上下文,并证明其评分理由。4)标准化输出格式:要求LLM提供结构化输出,包括详细的推理、具体的改进建议(如适用)和最终的数字评分。这有助于分析和一致性检查。
这种结构化方法允许对语义质量进行可扩展的评估,超越表面级检查,衡量文档对开发者的实际价值。
3.3 真实性
文档质量的一个关键维度是其事实准确性,或真实性。文档,尤其是由对特定私有代码库不熟悉的LLM生成的文档,可能会受到“幻觉”的影响——自信地引用不存在的方法、参数或类,或错误地表示组件之间的关系。这种不准确性严重削弱了信任,并可能导致开发者误入歧途。
我们通过验证生成文档中提到的实体是否实际存在于目标存储库中并且被正确引用来评估真实性。我们的管道包括三个阶段:代码实体提取:提示LLM识别生成的docstring中存储库特定代码组件(类、函数、方法、属性)的提及。提示特别指示模型区分这些与其他标准语言关键字、内置类型(例如,list、dict)和常见外部库组件,专注于内部引用。真实数据集构建:我们利用导航器模块2.1构建的依赖图。该图作为真实数据集,包含存储库中所有代码组件及其位置的规范表示。验证:每个提取的实体提及都与依赖图进行交叉引用。
我们使用存在比率来量化真实性:文档中提到的存储库特定实体中有多少比例对应于代码库中的实际实体。存在比率 =∣ 已验证实体 ∣ 提取实体 ∣=\frac{|\text { 已验证实体 }|}{\text { 提取实体 }|}= 提取实体 ∣∣ 已验证实体 ∣。
高比率表示文档牢固地基于实际代码结构,最小化了虚构引用的风险。
这三个维度——完整性、有用性和真实性——共同提供了一个强大而细致的框架,用于评估自动代码文档系统,使定量比较和深入了解其优缺点成为可能。
4 实验
4.1 基线
我们将DocAgent与两种常用的代码文档生成基线系统进行比较:FIM(Fill-in-the-middle):模拟内联代码完成工具,基于周围代码预测文档。我们使用CodeLlama-13B(Roziere等人,2023),一个训练带有FIM任务的开放模型(Bavarian等人,2022)。缩写为FIM-CL。Chat:表示通过将代码片段直接提供给基于聊天的LLM来生成文档。我们测试了两个领先模型:GPT-4o mini 7{ }^{7}7(OpenAI,2022)和CodeLlama-34B-instruct(Roziere等人,2023)。分别缩写为Chat-GPT和Chat-CL。
4.2 实验设置
数据。我们选择一组具有代表性的Python存储库,以确保在大小、复杂性和领域方面的多样性。数据集包括具有不同程度依赖密度的模块、函数、方法和类(详见附录D)。
系统。我们评估了我们提出的系统的两个变体,唯一的区别在于代理使用的主干LLM:DA-GPT:使用GPT4o mini的DocAgent。DA-CL:使用CodeLlama-34B-instruct 8{ }^{8}8 的DocAgent。
统计显著性。所有统计显著性的声明均基于配对t检验,显著性阈值为 p<0.059p<0.05^{9}p<0.059。
4.3 实验结果
我们使用第3节中提出的框架评估系统,重点关注完整性、有用性和真实性。
4.3.1 完整性
| 系统 | 总体 | 函数 | 方法 | 类 |
|---|---|---|---|---|
| DA-GPT | 0.934†0.934^{\dagger}0.934† | 0.945†0.945^{\dagger}0.945† | 0.935†0.935^{\dagger}0.935† | 0.914†\mathbf{0 . 9 1 4}^{\dagger}0.914† |
| DA-CL | 0.953†‡\mathbf{0 . 9 5 3}^{\dagger \ddagger}0.953†‡ | 0.985†‡\mathbf{0 . 9 8 5}^{\dagger \ddagger}0.985†‡ | 0.982†‡\mathbf{0 . 9 8 2}^{\dagger \ddagger}0.982†‡ | 0.816†‡0.816^{\dagger \ddagger}0.816†‡ |
| Chat-GPT | 0.815 | 0.828 | 0.823 | 0.773 |
| Chat-CL | 0.724 | 0.726 | 0.744 | 0.667 |
| FIM-CL | 0.314 | 0.291 | 0.345 | 0.277 |
表1:平均完整性得分。 7{ }^{7}7 :显著优于对应的Chat基线。 3{ }^{3}3 :显著优于FIM基线。
如表1所示,两种DocAgent变体均显著优于其相应的Chat对手。DocAgent(CodeLlama-34B)实现了
${ }^{7} 2024-07-18$ 版本
${ }^{8}$ 主干LLM的选择与DocAgent框架本身正交。我们在运行评估时普遍使用GPT-4o-2024-08-06以获得更稳健的结果。
${ }^{9}$ 由于篇幅限制,我们无法在论文中包含完整的提示和详细的实验设置。但是,所有配置均可在我们项目的公共发布存储库中找到。
总体得分为0.953 ,比Chat高出0.229分,显著提高。同样,DocAgent(GPT-4o mini)总体得分为0.934,显著高于Chat的0.815 。这些改进在所有组件类型中均具有统计显著性。FIM表现不佳,总体完整性得分为仅0.314 。这突显了DocAgent的结构化、上下文感知生成过程相较于简单提示LLM单独处理代码的有效性。
4.3.2 有用性
如表2所示,DocAgent(GPT-4o mini)实现了最高的总体有用性得分,显著优于相应的Chat基线。展示了其通过利用检索到的上下文生成更清晰、更有信息量的内容的能力。
| 系统 | 总体 | 摘要 | 描述 | 参数 |
|---|---|---|---|---|
| DA-GPT | 3.88†\mathbf{3 . 8 8}^{\dagger}3.88† | 4.32†\mathbf{4 . 3 2}^{\dagger}4.32† | 3.60†\mathbf{3 . 6 0}^{\dagger}3.60† | 2.71\mathbf{2 . 7 1}2.71 |
| DA-CL | 2.35‡2.35^{\ddagger}2.35‡ | 2.36†‡2.36^{\dagger \ddagger}2.36†‡ | 2.43‡2.43^{\ddagger}2.43‡ | 2.00 |
| Chat-GPT | 2.95 | 3.56 | 2.42 | 2.20 |
| Chat-CL | 2.16 | 2.04 | 2.37 | 1.80 |
| FIM-CL | 1.51 | 1.30 | 2.45 | 1.50 |
表2:平均有用性得分。 †{ }^{\dagger}† :显著优于相应的Chat。 ‡{ }^{\ddagger}‡ :显著优于FIM。
DocAgent(CodeLlama-34B)也显示出对其Chat对手的改进,生成显著更有用的摘要。此外,DocAgent(CodeLlama-34B)也在FIM上显著胜出。在各个方面,生成有用的参数描述似乎最具挑战性。DocAgent(GPT-4o mini)即使在此任务中也取得了最高得分,表明其结构化方法有助于这项困难的任务,尽管仍有改进空间。
4.3.3 真实性
表3中的结果显示,DocAgent生成的文档具有更高的事实准确性。DocAgent(GPT-4o mini)实现了最高的存在比率为 95.74%95.74 \%95.74%,表明其对内部代码组件的大部分引用都是正确的。DocAgent(CodeLlama34B)的表现也很强,比率为 88.17%88.17 \%88.17%。
这与基线形成了鲜明对比。Chat方法表现出显著较低的真实性,Chat(GPT-4o mini)为 61.10%61.10 \%61.10%,Chat(CodeLlama-34B)为 68.03%68.03 \%68.03%。这表明,简单地将代码片段提供给聊天
| 系统 | 验证 | 提取 | 存在比率(%) |
|---|---|---|---|
| DA-GPT | 265 | 305 | 95.74%\mathbf{9 5 . 7 4 \%}95.74% |
| DA-CL | 354 | 600 | 88.17%88.17 \%88.17% |
| Chat-GPT | 366 | 347 | 61.10%61.10 \%61.10% |
| Chat-CL | 366 | 488 | 68.03%68.03 \%68.03% |
| FIM-CL | 338 | 131 | 45.04%45.04 \%45.04% |
表3:真实性分析:存在比率(%)。更高更好。提取 = 提取实体;验证 = 验证实体在 §3.3 中。
模型通常会导致对代码库上下文的不准确假设或幻觉。FIM表现最差,存在比率为仅 45.04%45.04 \%45.04%,这意味着其对存储库实体的近一半引用可能是错误的。这个低分数突出显示了在使用FIM进行文档编写时误导开发人员的重大风险。
4.4 消融研究
为了隔离由导航器模块(§2.1)确定的依赖感知处理顺序的贡献,我们进行了消融研究。我们创建了DocAgent(DA-Rand-GPT,DA-Rand-CL)的变体,这些变体以随机顺序处理组件 10{ }^{10}10。
4.4.1 对有用性的影响
| 系统 | 总体 | 摘要 | 描述 | 参数 |
|---|---|---|---|---|
| DA-GPT | 3.88†\mathbf{3 . 8 8}^{\dagger}3.88† | 4.32†\mathbf{4 . 3 2}^{\dagger}4.32† | 3.60\mathbf{3 . 6 0}3.60 | 2.71\mathbf{2 . 7 1}2.71 |
| DA-Rand-GPT | 3.44(−0.44)3.44(-0.44)3.44(−0.44) | 3.62(−0.70)3.62(-0.70)3.62(−0.70) | 3.30(−0.30)3.30(-0.30)3.30(−0.30) | 2.20(−0.51)2.20(-0.51)2.20(−0.51) |
| DA-CL | 2.35†\mathbf{2 . 3 5}^{\dagger}2.35† | 2.36†\mathbf{2 . 3 6}^{\dagger}2.36† | 2.43\mathbf{2 . 4 3}2.43 | 2.00\mathbf{2 . 0 0}2.00 |
| DA-Rand-CL | 2.18(−0.17)2.18(-0.17)2.18(−0.17) | 1.88(−0.48)1.88(-0.48)1.88(−0.48) | 2.42(−0.10)2.42(-0.10)2.42(−0.10) | 2.00(0.00)2.00(0.00)2.00(0.00) |
表4:消融:平均有用性得分。 †{ }^{\dagger}† 如果DocAgent显著优于其随机变体。
表4中的结果显示了导航器的拓扑排序在提高有用性方面的益处。对于两种基础LLM,完整的DocAgent相比其随机顺序的对手实现了显著更高的总体有用性得分。使用GPT-4o mini时,完整的DocAgent得分为3.69,显著高于DocAgent-Random的3.44。摘要生成的改进尤为明显。同样,使用CodeLlama-34B时,完整的DocAgent得分为2.39,显著优于DocAgent-Random的2.18。再次,摘要得分显示出显著差异。
${ }^{10}$ 因为它依赖于代码的结构而非导航器的处理顺序,所以完整性在消融研究中被省略。
### 4.4.2 对真实性的影响
我们还评估了移除分层生成顺序对事实准确性(真实性)的影响。如果没有导航器,“先依赖”的原则未被遵循,这些组件不太可能已经有可用的文档供上下文使用。
| 系统 | 验证 | 提取 | 存在比率 (%) |
|---|---|---|---|
| DA-GPT | 187 | 224 | 94.64%\mathbf{9 4 . 6 4 \%}94.64% |
| DA-Rand-GPT | 164(−23)164(-23)164(−23) | 166(−58)166(-58)166(−58) | 86.75(−7.89)%86.75(-7.89) \%86.75(−7.89)% |
| DA-CL | 190 | 343 | 87.76%\mathbf{8 7 . 7 6 \%}87.76% |
| DA-Rand-CL | 188(−2)188(-2)188(−2) | 360(+17)360(+17)360(+17) | 83.06(−4.70)%83.06(-4.70) \%83.06(−4.70)% |
表5:消融:真实性分析(存在比率 %)。使用从完整数据中随机抽取的50个代码组件进行评估。
表5显示,拓扑排序也提高了真实性。两个完整的DocAgent变体比其随机顺序的对手实现了更高的存在比率。没有排序的情况下,DocAgent(GPT-4o-mini)的存在比率从94.64%94.64 \%94.64%下降到86.75%86.75 \%86.75%,而DocAgent(Codellama-34B)的存在比率从87.76%87.76 \%87.76%下降到83.06%83.06 \%83.06%。
总的来说,消融结果确认了导航器的依赖感知拓扑排序是DocAgent的关键组成部分,通过对上下文进行有效增量管理,显著提升了生成文档的有用性和事实准确性。
5 结论
我们解决了自动生成高质量代码文档的挑战,这是现有基于LLM的方法常在不完整性、缺乏帮助性和事实不准确性方面挣扎的任务。我们介绍了DocAgent,一种新型的工具集成、多智能体系统,利用由导航模块确定的依赖感知拓扑处理顺序。这允许专门的智能体(Reader、Searcher、Writer、Verifier、Orchestrator)通过逐步构建依赖关系的上下文来协作生成文档。我们还提出了一个强大且可扩展的评估框架,评估完整性、帮助性和真实性。我们在各种Python存储库上的实验表明,DocAgent始终显著优于FIM和Chat基线,生成更完整、更有帮助且事实更准确的文档。
通过消融研究确认了拓扑处理顺序对帮助性和真实性的关键贡献。DocAgent代表了在复杂和专有软件中实现可靠和有用的自动代码文档生成的重要一步。
6 伦理和局限性
尽管DocAgent推进了自动代码文档生成,但它仍存在固有的局限性和伦理考量。技术上,尽管有拓扑排序和上下文管理,处理极其大型的代码库可能仍会挑战LLM的上下文限制。仅依靠静态分析限制了对动态行为的理解,当前的Python重点需要努力适应其他语言。
伦理上,主要关注的是事实准确性;尽管有所改进,生成的文档仍可能包含幻觉或不准确性,可能误导开发者。底层的LLM可能会将训练数据中的偏见传播到文档中。过度依赖此类工具可能会阻碍开发者深入理解代码的能力。将DocAgent应用于专有代码需要谨慎处理,尤其是关于外部查询,以避免无意中泄露敏感信息。最后,驱动多智能体系统的计算资源代表了显著的成本和环境考量。未来的工作应解决这些局限性,重点关注稳健性、偏见缓解和更深入的评估,同时强调在实际部署中人类监督的重要性。
参考文献
Samuel Abedu, Ahmad Abdellatif, and Emad Shihab. 2024. Llm-based chatbots for mining software repositories: Challenges and opportunities. In Proceedings of the 28th International Conference on Evaluation and Assessment in Software Engineering, pages 201210 .
Emad Aghajani, Csaba Nagy, Olga Lucero VegaMárquez, Mario Linares-Vásquez, Laura Moreno, Gabriele Bavota, and Michele Lanza. 2019. Software documentation issues unveiled. In 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), pages 1199-1210. IEEE.
Wasi U Ahmad, Saikat Chakraborty, Baishakhi Ray, and Kai-Wei Chang. 2021. Unified pre-training for program understanding and generation. In ACLA C LACL.
Anthropic. 2025. Model context length increases with the new context protocol. Accessed: 2025-03-27.
Mohammad Bavarian, Heewoo Jun, Nikolas Tezak, John Schulman, Christine McLeavey, Jerry Tworek, and Mark Chen. 2022. Efficient training of language models to fill in the middle. arXiv preprint arXiv:2207.14255.
Jie-Cherng Chen and Sun-Jen Huang. 2009. An empirical analysis of the impact of software development problem factors on software maintainability. Journal of Systems and Software, 82(6):981-992.
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, and 1 others. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374.
Qian Chen, Binyuan Tang, Yankai Zhang, Binhua Wang, Zhifang Zhang, and Qun Zhang. 2023. Teaching large language models to self-debug. arXiv preprint arXiv:2305.03047.
Cheng-Han Chiang and Hung-yi Lee. 2023. Can large language models be an alternative to human evaluations? In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL).
Colin B Clement, Andrew Terrell, Hanlin Mao, Joshua Dillon, Sameer Singh, and Dan Alistarh. 2020. Pymt5: Multi-mode translation of natural language and python code with transformers. In EMNLP.
Sergio Cozzetti B De Souza, Nicolas Anquetil, and Káthia M de Oliveira. 2005. A study of the documentation essential to software maintenance. In Proceedings of the 23rd annual international conference on Design of communication: documenting & designing for pervasive information, pages 68-75.
Shubhang Shekhar Dvivedi, Vyshnav Vijay, Sai Leela Rahul Pujari, Shoumik Lodh, and Dhruv Kumar. 2024. A comparative analysis of large language models for code documentation generation. In Proceedings of the 1st ACM International Conference on AI-Powered Software, pages 65-75.
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, and Daxin Jiang. 2020. Codebert: A pre-trained model用于编程和自然语言的预训练模型。在EMNLP会议上发表。
Golara Garousi, Vahid Garousi-Yusifoğlu, Guenther Ruhe, Junji Zhi, Mahmoud Moussavi, and Brian Smith. 2015. 技术软件文档的使用与实用性:一个工业案例研究。《信息与软件技术》,57:664-682。
GitHub. 2024. GitHub Copilot如何更好地理解您的代码。访问日期:2025-03-27。
Liron Guelman, Alon Lavie, and Eran Yahav. 2024. 使用大型语言模型为代码生成文档:首次定量和定性评估。arXiv预印本arXiv:2403.04264。
Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Nan Duan, Ming Zhou, and Daxin Jiang. 2021. GraphCodeBERT:使用数据流进行代码表示的预训练。ICLR会议论文。
Seungone Kim, Soobin Kim, Alice Oh, and Gunhee Han. 2023. Prometheus:在语言模型中诱导细粒度评估能力。arXiv预印本arXiv:2310.08491。
Michael Krumdick, Jason Wei, Xinyang Chen, Shangbin Du, Shu Xu, Dale Schuurmans, and Ed H Chi. 2025. 没有免费标签:没有人类基准的情况下,LLM-as-judge的局限性。arXiv预印本arXiv:2503.05061。
Yukyung Lee, Wonjoon Cho, and Jinhyuk Kim. 2024. CheckEval:一种可靠的LLM-as-a-Judge框架,用于使用清单评估文本生成。arXiv预印本arXiv:2403.18771。
Raymond Li, Lewis Tunstall, Patrick von Platen, Jungtaek Kim, Teven Le Scao, Thomas Wolf, and Alexander M. Rush. 2023a. StarCoder:愿源代码与你同在!预印本,arXiv:2305.06161。
Xiang Li, Qinyuan Zhu, Yelong Cheng, Weizhu Xu, and Xi Liu. 2023b. CAMEL:用于“心智”探索的交流代理。arXiv预印本arXiv:2303.17760。
Minqian Liu, Cheng Feng, Qing Lyu, Wenhao Zeng, Chao Zheng, Ruidan Zhang, and Steven C H Lin. 2023a. X-Eval:通过增强指令调整实现可泛化的多方面文本评估。arXiv预印本arXiv:2311.08788。
Yang Liu, Yao Fu, Yujie Xie, Xinyi Chen, Bo Pang, Chenyan Qian, Teng Ma, and Dragomir Radev. 2023b. G-Eval:使用GPT-4进行更好的与人类对齐的NLG评估。在《2023年经验方法在自然语言处理国际会议论文集》中发表。
Qinyu Luo, Yining Ye, Shihao Liang, Zhong Zhang, Yujia Qin, Yaxi Lu, Yesai Wu, Xin Cong, Yankai Lin, Yingli Zhang, and others. 2024. RepoAgent:一种基于LLM的开源框架,用于存储库级别的代码文档生成。arXiv预印本arXiv:2402.16667。
Yingwei Ma, Qingping Yang, Rongyu Cao, Binhua Li, Fei Huang, and Yongbin Li. 2024. 如何理解整个软件仓库?arXiv预印本arXiv:2406.01422。
Paul W McBurney, Siyuan Jiang, Marouane Kessentini, Nicholas A Kraft, Ameer Armaly, Mohamed Wiem Mkaouer, and Collin McMillan. 2017. 优先化文档工作的方向。《IEEE软件工程学报》,44(9):897-913。
Meta. 2025. Meta AI. https://ai.meta.com/ meta-ai/. 访问日期:2025-03-27。
OpenAI. 2022. 引入ChatGPT。访问日期:2025-03-27。
David Lorge Parnas. 2010. 精确文档:更好的软件的关键。《未来软件工程》,第125-148页。Springer出版社。
Yuzhang Qian, Zian Zhang, Liang Pan, Peng Wang, Shouyi Liu, Wayne Xin Zhao, and Ji-Rong Wen. 2023. ChatDev:用AI协作代理革新软件开发。arXiv预印本arXiv:2307.07924。
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. 直接偏好优化:你的语言模型实际上是一个奖励模型。神经信息处理系统进展,36:5372853741。
Martin P Robillard. 2009. 为什么API难以学习?开发者的答案。《IEEE软件》,26(6):27-34。
Rahul Roy, Saikat Chakraborty, Baishakhi Ray, and Miryung Kim. 2021. 再次评估代码摘要任务的自动评估指标。《第29届ACM欧洲软件工程大会和软件工程基础研讨会论文集》(ESEC/FSE),第1344-1356页。
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, and others. 2023. Code Llama:开放的基础代码模型。arXiv预印本arXiv:2308.12950。
Noah Shinn, Margaret Labash, and Stefano Ermon. 2023. Reflexion:具有语言强化学习的代理。arXiv预印本arXiv:2303.11366。
Robert Tarjan. 1972. 深度优先搜索和线性图算法。SIAM计算杂志,1(2):146160。
Gias Uddin, Foutse Khomh, and Chanchal K Roy. 2021. 自动从技术问答网站生成API使用场景文档。《ACM软件工程与方法学交易》(TOSEM),30(3):145。
Yidong Wang, Qi Guo, Wenjin Yao, Hongbo Zhang, Xin Zhang, Zhen Wu, Meishan Zhang, Xinyu Dai, Qingsong Wen, Wei Ye, and others. 2024. AutoSurvey:大型语言模型可以自动生成调查报告。神经信息处理系统进展,37:115119-115145。
Yue Wang, Shuo Ren, Daya Lu, Duyu Tang, Nan Duan, Ming Zhou, and Daxin Jiang. 2021. CodeT5:识别符感知的统一预训练编码器-解码器模型,用于代码理解和生成。EMNLP会议论文。
Ziniu Wu, Cheng Liu, Jindong Zhang, Xinyun Li, Yewen Wang, Jimmy Xin, Lianmin Zhang, Eric Xing, Yuxin Lu, and Percy Liang. 2023. AutoGen:通过语言模型实现下一代多代理通信。arXiv预印本arXiv:2309.07864。
Dayu Yang, Tianyang Liu, Daoan Zhang, and others. 2025. 从代码到思考,从思考到代码:关于LLM中代码增强推理和推理驱动代码智能的综述。arXiv预印本arXiv:2502.19411。
Guang Yang, Yu Zhou, Wei Cheng, Xiangyu Zhang, Xiang Chen, Terry Yue Zhuo, Ke Liu, Xin Zhou, David Lo, and Taolue Chen. 2024. 少即是多:代码生成中的Docstring压缩。arXiv预印本arXiv:2410.22793。
Shinn Yao, Jeffrey Zhao, Dian Yu, Kang Chen, Karthik Narasimhan, and Yuan Cao. 2022. React:协同推理和行动的语言模型。arXiv预印本arXiv:2210.03629。
Yaqing Zan, Mingyu Ding, Bill Yuchen Lin, and Xiang Ren. 2022. 当语言模型遇到私有库时。《2022年经验方法在自然语言处理国际会议论文集》(EMNLP)。计算语言学协会。
Kaiyu Zhang, Yifei Wang, Yue Yu, Yujie Li, Zihan Lin, Dongxu Zhang, Yichi Zhou, Yifei Xu, Ang Chen, Weiyi Zhang, and others. 2024. LLM幻觉在实际代码生成中的现象、机制和缓解措施。arXiv预印本arXiv:2401.10650。
Shiyue Zhang, Binyi Li, Jason Wei, Aditi Raghunathan Vyas, and Percy Liang. 2023a. TheMis:灵活且可解释的NLG评估模型。arXiv预印本arXiv:2309.12082。
Xiaoqing Zhang, Zhirui Wang, Lichao Yang, Wei Zhang, and Yong Zhang. 2023b. MapCoder:具有多代理协作的Map-Reduce风格代码生成。arXiv预印本arXiv:2307.15808。
Lianmin Zheng, Shangbin Du, Yuhui Lin, Yukuo Shao, Zi Lin, Zhen Liu, and others. 2023. 用MT-Bench和Chatbot Arena评估LLM-as-a-Judge。arXiv预印本arXiv:2306.05685。
Zihan Zheng, Jiayi Zheng, Weiyan Liu, Yizhong Wang, Chen Liu, Xiang Lorraine Li, Mu Li, Wenhao Zhang, Diyi Huang, and Xiang Ren. 2024. LLM在不同应用领域生成代码的能力如何?arXiv预印本arXiv:2401.13727。
Shuyan Zhou, Uri Alon, Frank F Xu, Zhiruo Wang, Zhengbao Jiang, and Graham Neubig. 2022. DocPrompting:通过检索文档生成代码。arXiv预印本arXiv: 2207.05987。
Mingchen Zhuge, Changsheng Zhao, Dylan Ashley, Wenyi Wang, Dmitrii Khizbullin, Yunyang Xiong, Zechun Liu, Ernie Chang, Raghuraman Krishnamoorthi, Yuandong Tian, and others. 2024. Agent-as-a-Judge:用代理评估代理。arXiv预印本arXiv:2410.10934。
A 相关工作
LLM代理 最近LLM代理的进步使得自动化复杂的代码相关任务成为可能(Yang等人,2025)。单代理框架如ReAct(Yao等人,2022)和Reflexion(Shinn等人,2023)集成了行动-推理和自我反思。多代理系统(CAMEL(Li等人,2023b)、AutoGen(Wu等人,2023))通过角色专门化的LLM和结构化通信扩展了这些想法以处理更复杂的问题。在软件开发中,MapCoder(Zhang等人,2023b)、RGD(Chen等人,2023)和ChatDev(Qian等人,2023)利用专门的代理来完成许多下游任务,实现了最先进的代码生成。这些关于多代理协调和工作流结构化的见解构成了我们的DocAgent框架的基础,该框架采用了拓扑感知、工具集成的多代理设计。
代码总结 预训练编码器如CodeBERT(Feng等人,2020)和GraphCodeBERT(Guo等人,2021)引入了双模态和结构感知学习,而编码器-解码器模型PLBART(Ahmad等人,2021)和CodeT5(Wang等人,2021)统一了代码生成和总结。PyMT5(Clement等人,2020)扩展了T5支持Python docstring翻译的多模式功能。最近,LLM(OpenAI Codex(Chen等人,2021)、StarCoder(Li等人,2023a)、CodeLlama(Roziere等人,2023))展示了强大的零样本总结能力。然而,它们通常缺乏存储库级别的上下文、依赖意识和协作——这是我们的多代理、上下文感知DOCAGENT旨在克服的局限性。
B 为什么需要外部信息
对于一些新颖的、新提出的概念,如新的评估方法、算法、模型结构、损失函数,外部开放互联网信息请求是必要的。例如,DPO(Rafailov等人,2023)是一种2023年提出的强化学习算法。Codellama的知识截止时间为2022年9月。因此,在使用codellama生成文档时,如果不访问来自开放互联网的DPO数学直觉和描述,codellama将不可能写出有助于描述DPO实现直觉的有用文档。
C 代码文档的稀缺性
我们分析了164个顶级星标的Python存储库(创建于2025年1月1日之后),涵盖了13,314个文件和115,943个可记录节点(函数、类和方法)。其中,只有27.28%27.28 \%27.28%包含任何文档,66.46%66.46 \%66.46%的存储库覆盖率低于30%30 \%30%(图5)。此外,62.25%62.25 \%62.25%的存储库平均每段文档块包含30个单词或更少(图6),而仅3.98%3.98 \%3.98%超过平均每段100个单词,说明了代码文档的广泛简短性和整体稀缺性。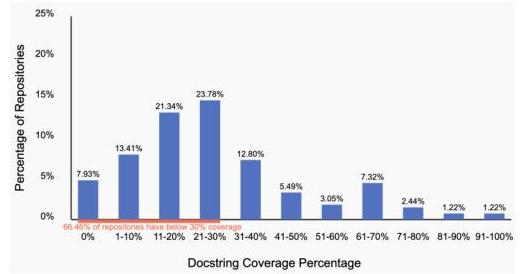
图5:按代码文档覆盖率划分的存储库分布。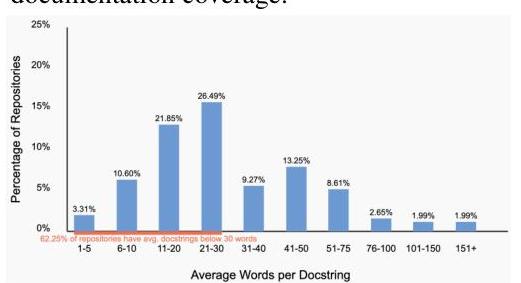
图6:按平均每段文档字数划分的存储库分布。
D 数据
我们从GitHub收集了164个顶级星标Python存储库,每个存储库均创建于2025年1月1日之后,拥有超过50颗星,并且大小超过50 KB。从这个语料库中,我们选择了9个存储库,反映了整体分布在代码行数和拓扑复杂性方面的分布。图7显示了所选存储库(红点)覆盖在更广泛的分布之上。最终,我们收集了366个代码组件(120个函数、178个方法和68个类)用于评估,其中单独的一组50个不同的代码组件(从完整集合中随机抽取)专门用于我们的真实性消融研究。
E 稳健的LLM-as-judge
由于主观性,自动评估Helpfulness的定性方面本质上具有挑战性。我们采用LLM-as-judge方法,但结合现有工作中启发的严格机制以增强可靠性和一致性,减轻已知问题如位置偏差或变化(Wang et al., 2024; Zhuge et al., 2024):分解评估:而不是单一的整体判断,LLM分别评估docstring的不同部分(例如,摘要、参数描述、整体描述),每个部分使用定制的提示(Liu et al., 2023a; Lee et al., 2024)。结构化提示:每个提示向LLM提供:
- 明确标准:详细的准则定义了针对不同水平的5点李克特量表(1=1=1=差到5=5=5=优秀)的期望,具体到正在评估的docstring部分的清晰度、细节和效用(Kim et al., 2023; Zhang et al., 2023a)。
-
- 示例说明:少量示例展示对应不同评分水平的良好和不良文档片段,使标准具体化(Zheng et al., 2023; Chiang 和 Lee, 2023)。
-
- 思维链指令:引导LLM首先分析代码,然后将相应的docstring部分与标准进行比较,逐步证明其评分理由,并识别具体的优缺点(Liu et al., 2023b; Zheng et al., 2023)。
-
- 标准化输出格式:要求LLM以结构化格式(例如JSON)输出其评分及详细理由,便于汇总和分析,同时确保LLM遵循评估协议(Liu et al., 2023b; Lee et al., 2024; Krumdick et al., 2025)。
这种结构化的LLM-as-judge方法旨在提供一种可扩展但仍细致的开发者实用价值评估。
- 标准化输出格式:要求LLM以结构化格式(例如JSON)输出其评分及详细理由,便于汇总和分析,同时确保LLM遵循评估协议(Liu et al., 2023b; Lee et al., 2024; Krumdick et al., 2025)。
F 更多系统截图
图8显示了在启动代码文档生成过程之前的配置页面。该页面主要由三部分组成:目标存储库路径、LLM配置和流程控制(用于协调器)。
图8:配置页面的截图。
图9显示了点击“Evaluate”按钮后出现的窗口。由于使用LLM作为评判员成本较高(每次评估大约消耗500个标记),此功能在Web UI中是可选的。只有当用户点击“Evaluate”按钮时才会触发评估,之后按钮会改变以显示生成的分数。
图9:有用性评估窗口的截图。
参考论文:https://arxiv.org/pdf/2504.08725
更多推荐


 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)