
deep search框架deerflow
·
介绍
DeerFlow(Deep Exploration and Efficient Research Flow)是字节跳动于2025年5月开源的深度研究框架,旨在通过多智能体协作和AI技术简化复杂研究任务与内容创作流程。
# Github地址
https://github.com/bytedance/deer-flow/tree/main
核心功能
- 自动化研究:集成网络搜索(如Tavily、Brave Search)、爬虫、Python代码执行等工具,支持从数据收集到报告生成的端到端流程。
- 多模态输出:可生成包含图像的综合报告、PPT演示文稿、播客脚本及语音合成(借助火山引擎TTS技术)。
- 人机协作:支持自然语言交互修改研究计划,提供“人在回路”(Human-in-the-loop)的实时调整能力。
- 动态任务规划:基于多Agent架构自动分解任务并优化研究路径,支持迭代式改进。
- 无缝集成MCP服务。
技术架构
- 多Agent系统:包含协调器(管理流程)、规划器(任务分解)、研究团队(信息收集与代码分析)、报告生成器等模块,基于LangGraph构建工作流。
- 工具集成:支持多种语言模型(如Qwen、OpenAI兼容接口),并扩展私有域访问和知识图谱能力。
- 分布式设计:高效处理大规模数据,具备容错机制。
前端
- Next.js:用于 Web UI 的 React 框架
- Shadcn UI:极简 UI 组件
- Zustand: 状态管理
- Framer Motion:动画库
- React Markdown:Markdown 渲染
后端
- FastAPI:API 端点的服务器框架
- LangGraph:工作流编排
- LangChain:LLM 交互框架
系统架构
- 前端:next.js web应用
- 后端:FastAPI python应用
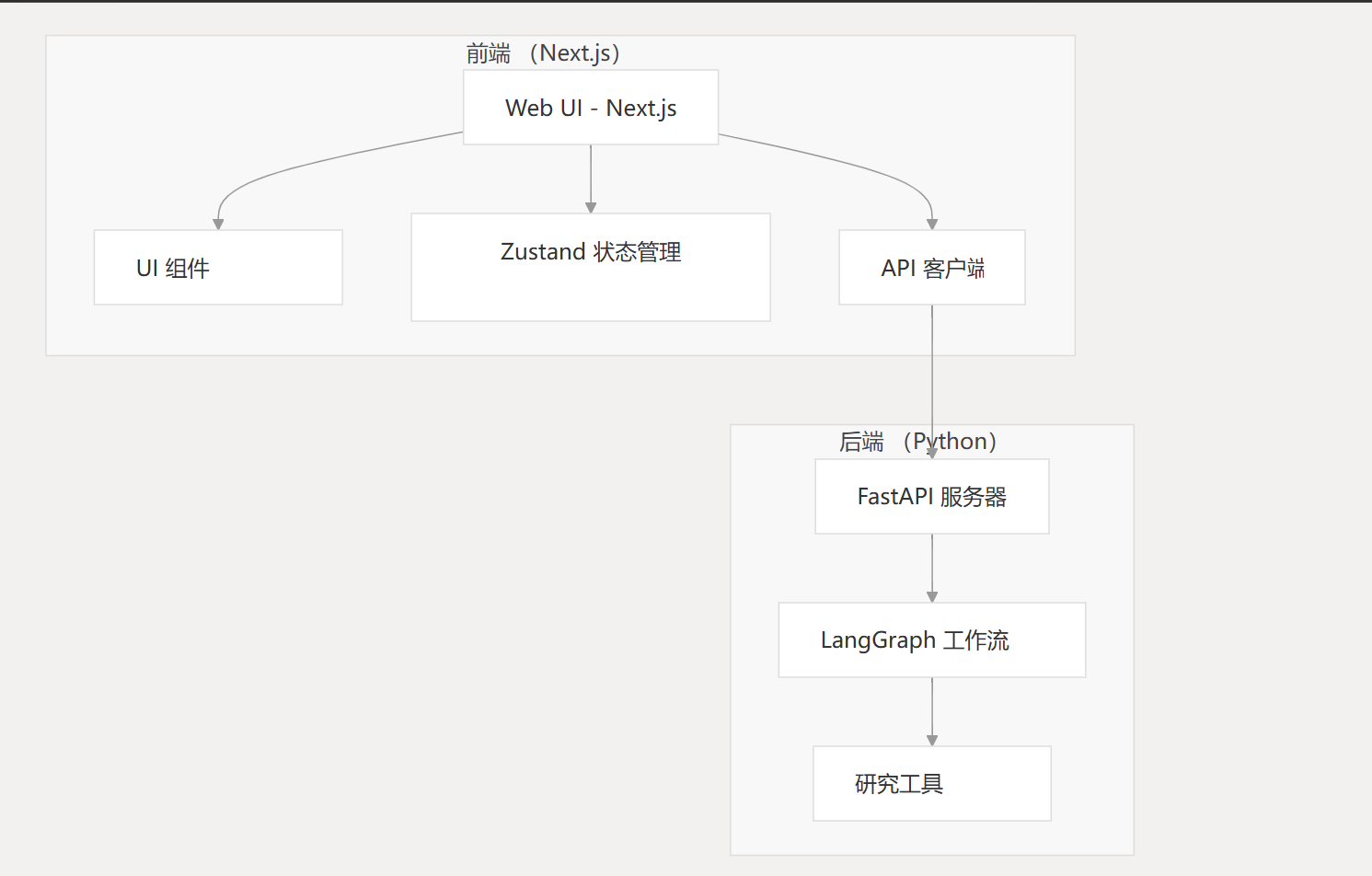
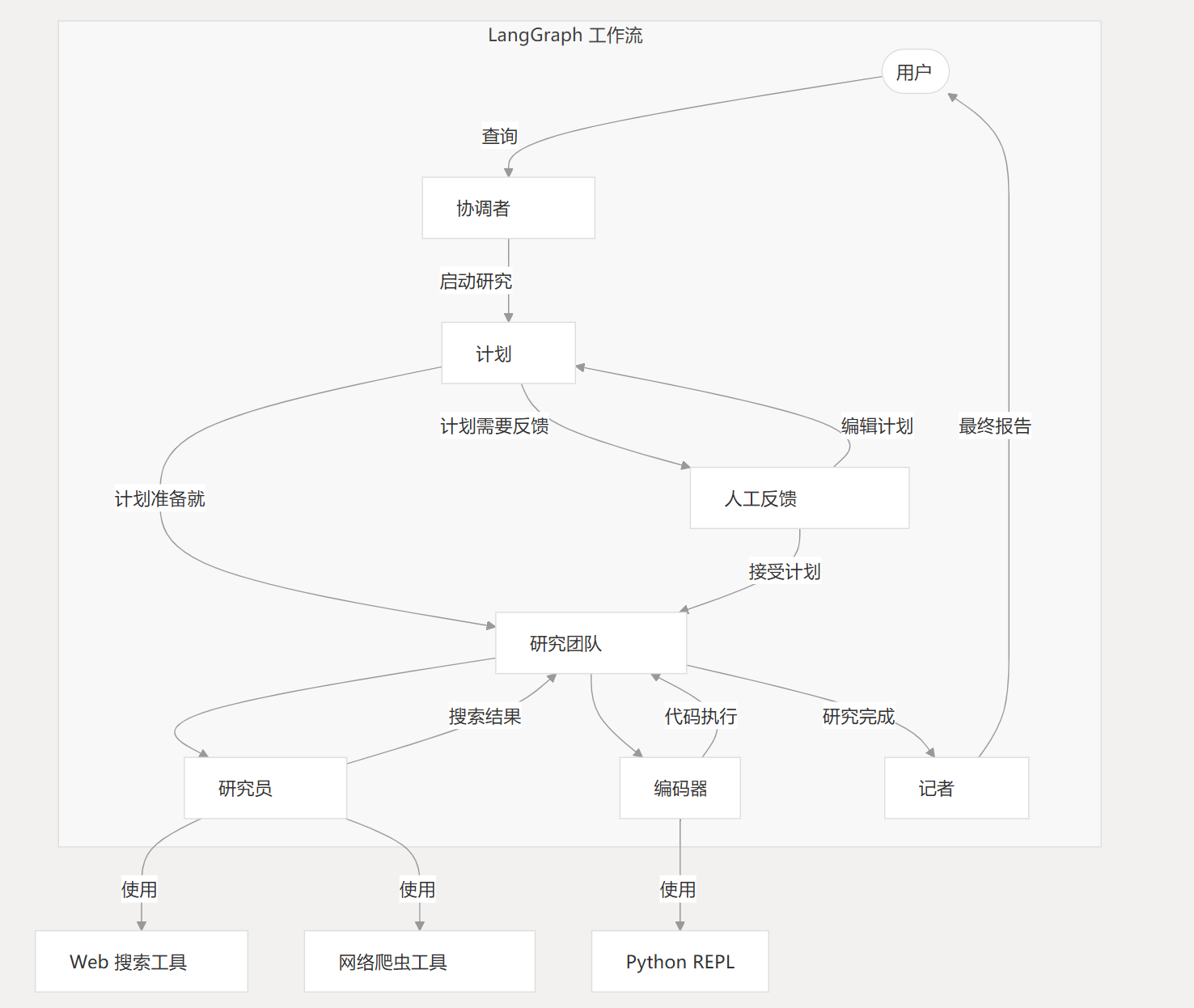
工作流架构
- 协调器:管理工作流生命周期的入口点
- 根据用户输入启动研究流程
- 在适当的时候将任务委派给规划者
- Planner:任务分解的战略组件
- 创建结构化执行计划
- 确定是否需要更多研究
- 研究团队:执行计划的专业代理
- 研究员:进行网络搜索和信息收集
- 编码员:处理代码分析和技术任务
- Reporter:研究成果的最终阶段处理器
- 汇总研究团队的发现
- 生成全面的研究报告
应用场景
- 学术/市场研究:快速生成文献综述或行业分析报告。
- 内容创作:自动化生成播客、PPT及技术文档。
- 企业决策:辅助技术评估与战略规划。
部署
DeerFlow 使用 Python 开发,并配有用 Node.js 编写的 Web UI。
- ubuntu服务器部署
# 克隆仓库
git clone https://github.com/bytedance/deer-flow.git
cd deer-flow
# uv:Python 项目管理和包管理工具
curl -LsSf https://astral.sh/uv/install.sh | sh
source ~/.bashrc
# 安装依赖,uv将负责Python解释器和虚拟环境的创建,并安装所需的包
uv sync
# 配置各API
cp .env.example .env
vim .env
# 去Tavily:https://app.tavily.com/home 官网注册账号并拿到API Keys填上
TAVILY_API_KEY=XXX
# 配置LLM模型和API秘钥
cp conf.yaml.example conf.yaml
vim conf.yaml
# 注意DeerFlow目前仅支持非推理模型,目前还不支持 OpenAI 的 o1/o3 或 DeepSeek 的 R1 等模型
# 支持doubao-1.5-pro-32k-250115、 以及理论上实现 OpenAI API 规范的任何其他非推理聊天模型。gpt-4oqwen-max-latestgemini-2.0-flashdeepseek-v3
# 注册豆包账号并开通模型权限获得API Key
base_url: https://ark.cn-beijing.volces.com/api/v3
model: "doubao-1-5-pro-32k-250115"
api_key: XXX
# 此时应该就可以运行main.py服务进行命令行提问了
uv run main.py
# 项目中还提供了node.js开发的Web UI界面使用。
# 先安装nvm(管理Node.js版本)并安装node.js
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.7/install.sh | bash
source ~/.bashrc
nvm install --lts
# 再安装pnpm(管理 Node.js 项目的依赖。)
curl -fsSL https://get.pnpm.io/install.sh | sh -
# 安装Web UI依赖
cd deer-flow/web
pnpm install
# 运行前后端服务
cd deer-flow
./bootstrap.sh -d
# 此时在浏览器访问服务IP:3000即可,如果是在本地电脑上部署的,那应该没有问题。
# 如果是在服务器上部署的,会报错:An error occurred while generating the response.Please try again.
# 需要将server.py中的localhost改为0.0.0.0,让所有ip都可访问。
vim deer-flow/server.py
# 前端deer-flow/web/src/core/api/resolve-service-url.ts中的localhost需要改成服务器ip。
vim deer-flow/web/src/core/api/resolve-service-url.ts
# 根据报告增加生成语音博客
# 注册火山引擎账号,然后搜索语音技术,进入控制台,点击创建应用
# 填写应用名称,应用简介,选择大模型语音合成,选择默认项目,点击确定。
# 左侧栏选择音频生成-语音合成,在最下面复制APP ID和Access Token填入项目的.env文件中。
# Optional, volcengine TTS for generating podcast
VOLCENGINE_TTS_APPID=8436084360
VOLCENGINE_TTS_ACCESS_TOKEN=VuENEXyVuENEXyVuENEXyVuENEXy
#VOLCENGINE_TTS_CLUSTER=volcano_tts # Optional, default is volcano_tts
#VOLCENGINE_TTS_VOICE_TYPE=BV700_V2_streaming # Optional, default is BV700_V2_streaming
# Web页面右上角点击生成音频即可
# 该项目支持MCP工具,如Github排名
# https://github.com/hetaoBackend/mcp-github-trending
# 找到Published Servers Configuration中的配置,复制到右上角配置的MCP中即可。
{
"mcpServers": {
"mcp-github-trending": {
"command": "uvx",
"args": [
"mcp-github-trending"
]
}
}
}
# 高德地图MCP
# https://lbs.amap.com/api/mcp-server/gettingstarted#s2
{
"mcpServers": {
"amap-amap-sse": {
"url": "https://mcp.amap.com/sse?key=您在高德官网上申请的key"
}
}
}
# 前端端口是默认的3000,想更换端口可以
cd web
# 这是开发环境
pnpm dev --port 1030
# 下面是生产环境
pnpm build
pnpm start --port 1030
# 后端想换端口,将文件中的8000可以直接换
vim deer-flow/server.py
- docker部署
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)