
【干货收藏】从DeepSeek技术突破看大模型未来,MoE架构与Agentic AI全解析
文章分析了DeepSeek模型的技术架构和对大模型未来发展的启示。核心内容包括:1) MoE架构通过稀疏激活实现万亿级参数高效训练;2) Agentic AI代表从被动响应到主动协作的范式转变;3) 下一代训练聚焦数据质量、工具学习和多智能体协作;4) AWORLD框架解决Agentic AI训练的并行计算挑战;5) 未来大模型将向超级专家系统、社会智能体和可解释AI方向发展。DeepSeek的开
文章分析了DeepSeek模型的技术架构和对大模型未来发展的启示。核心内容包括:1) MoE架构通过稀疏激活实现万亿级参数高效训练;2) Agentic AI代表从被动响应到主动协作的范式转变;3) 下一代训练聚焦数据质量、工具学习和多智能体协作;4) AWORLD框架解决Agentic AI训练的并行计算挑战;5) 未来大模型将向超级专家系统、社会智能体和可解释AI方向发展。DeepSeek的开源策略为这一演进提供了基础。
——从DeepSeek技术交底看大模型未来
🔍 一、MoE架构:万亿参数的效率革命
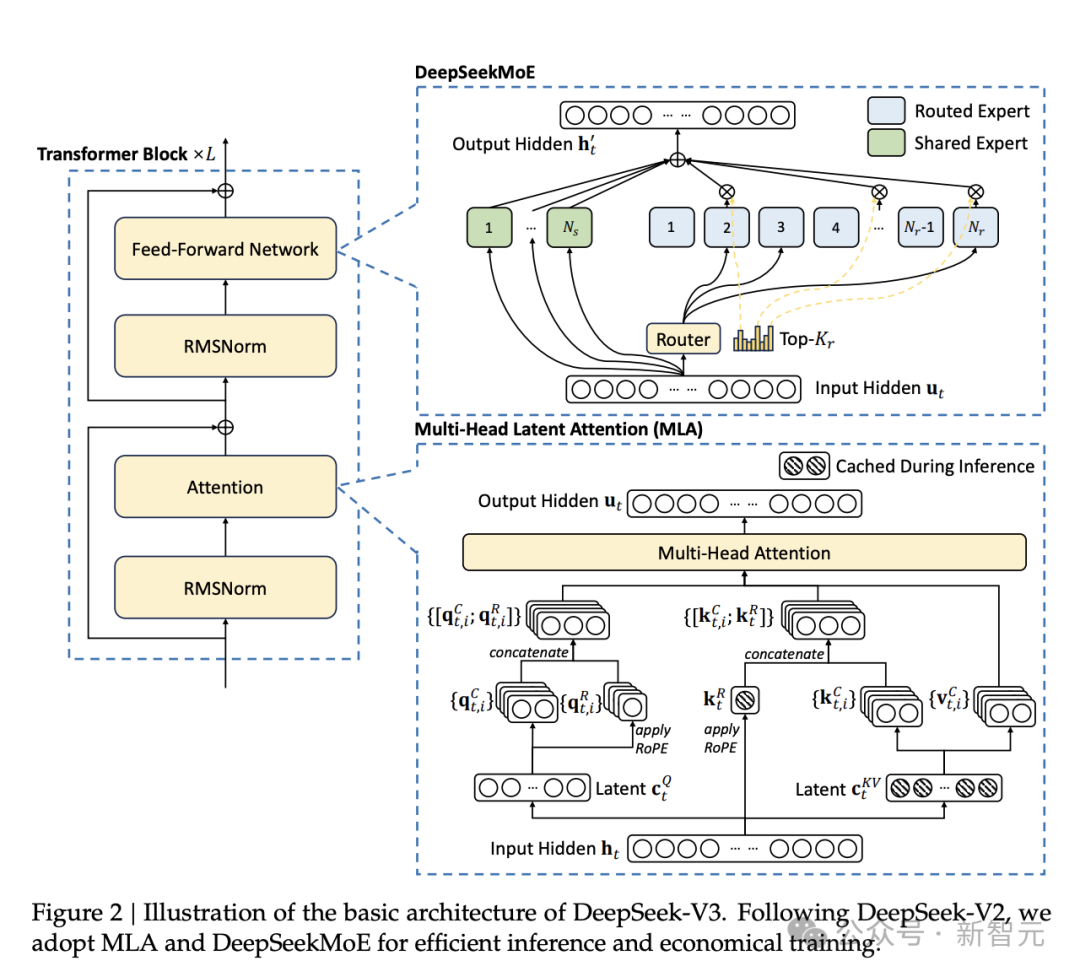
Mixture of Experts(MoE) 是当前突破千亿级参数瓶颈的核心架构。与传统Transformer不同,MoE将模型拆分为多个“专家子网络”,每个输入仅激活部分专家(如DeepSeek-V3采用稀疏激活),实现计算效率与模型容量的双重突破。
下图对比稠密模型和Moe模型差异,MoE将传统的前馈模块替换为多个专家层,每个专家层也是一个前馈模块。在推理时,一个路由器会选择一小部分专家进行激活。例如,DeepSeek V3有256个专家,但每次推理仅激活9个专家(1个共享专家和8个由路由器选择的专家)。
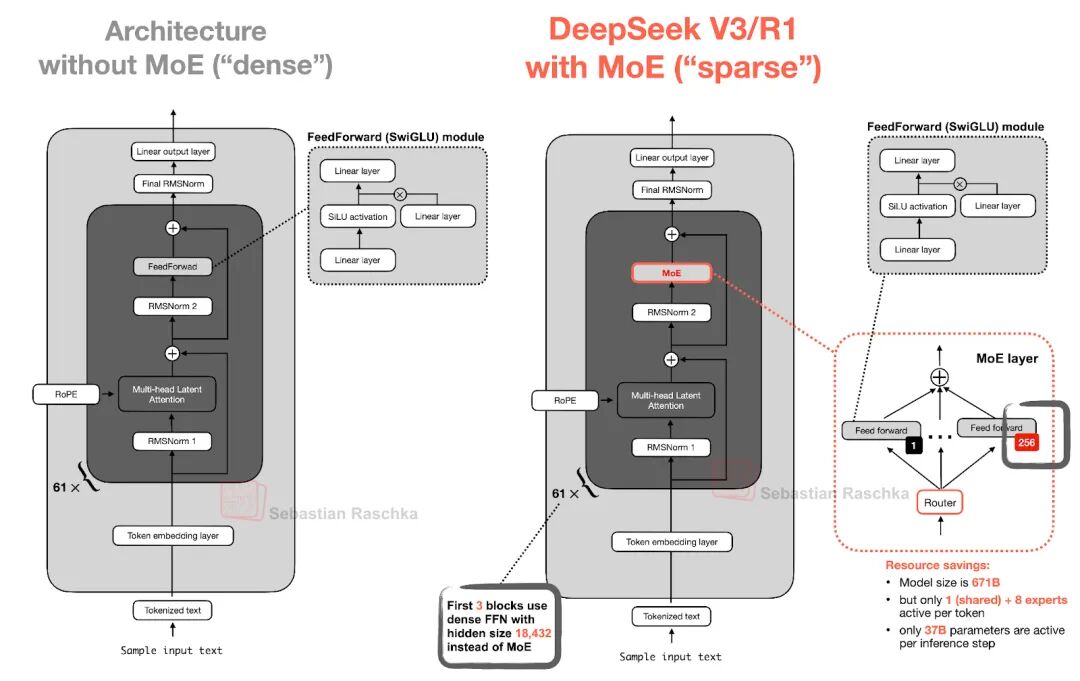
DeepSeek-V3-0324(6850亿参数)的规模背后,MoE架构功不可没:
MoE通过动态路由(如Top-k门控)选择专家,使模型在推理时仅消耗20%-30%的计算资源,却获得接近万亿参数的性能。
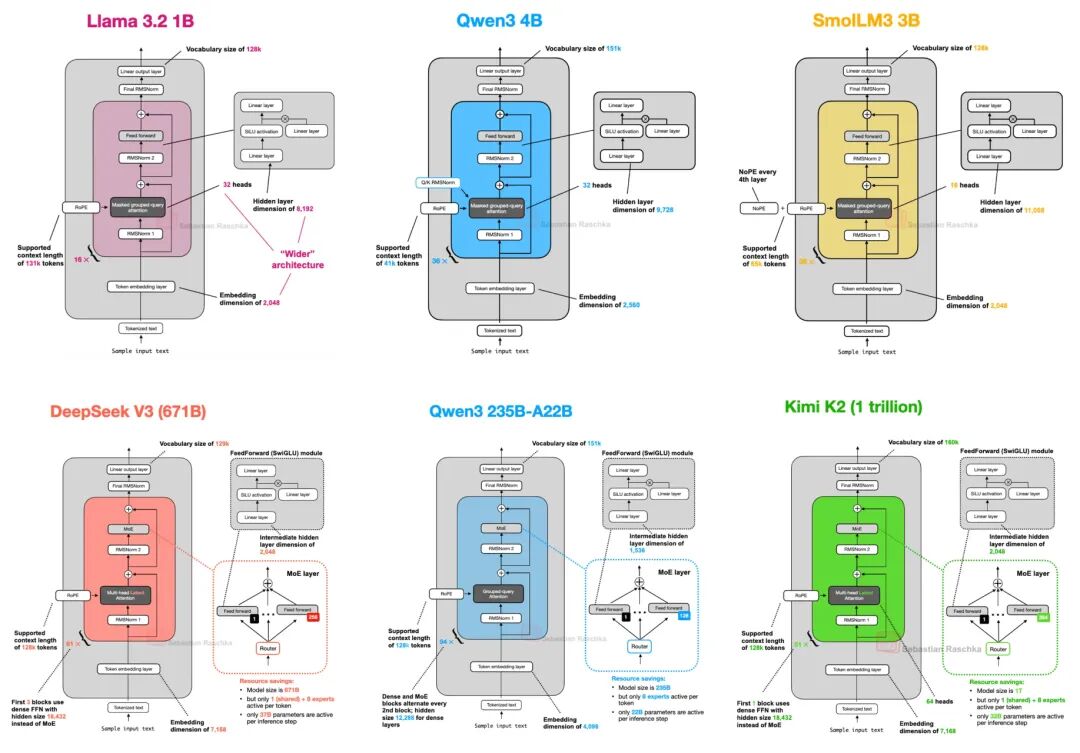
Llama 4采用了与DeepSeek V3类似的架构,但在某些细节上进行了优化,以提高模型的性能和效率。Llama 4使用了分组查询注意力(GQA)而非多头潜在注意力(MLA),并且在MoE模块中使用了更少但更大的专家。此外,Llama 4在每个Transformer块中交替使用MoE模块和密集模块。 Qwen3的MoE模型采用了与DeepSeek V3类似的架构,但在某些细节上有所不同,例如不使用共享专家。这种设计使得模型在训练时能够学习更多知识,而在推理时保持高效。 Kimi K2采用了DeepSeek V3的架构,并进行了扩展。它使用了Muon优化器而非AdamW,这可能是其训练损失曲线表现优异的原因之一。此外,Kimi K2在MoE模块中使用了更多的专家,在MLA模块中使用了更少的头。这些设计使得Kimi 2在训练过程中表现优异,训练损失曲线平滑且下降迅速。这可能有助于该模型跃居上述基准测试的榜首。 🤖 二、Agentic AI:从被动响应到主动协作
Agentic AI(智能体导向的AI)是下一代大模型的核心范式。它让模型具备目标分解、自我反思、工具调用能力,而不仅是“问答机器”。DeepSeek-R1的训练方法已初现Agentic雏形:
在优化训练阶段,研究人员引导模型生成带反思的详细答案(Self-Instruct),再通过人工修正提升逻辑严谨性:这种“自我验证+人工对齐”正是Agentic AI的早期实践——让模型像人类一样拆解任务、验证假设、修正错误。
先回顾一下人工反馈强化学习(Reinforcement Learning from Human Feedback,简称 RLHF),顾名思义,就是先训练基础模型,在训练奖励模型,然后用奖励模型给基础模型打分做强化学习,通过强化学习算法微调LLM,保证输出内容的对齐和调优。缺点也显而易见,一个是奖励模型训练复杂,决定了模型好坏;一个是这里注重结果,没有注重过程对齐训练。
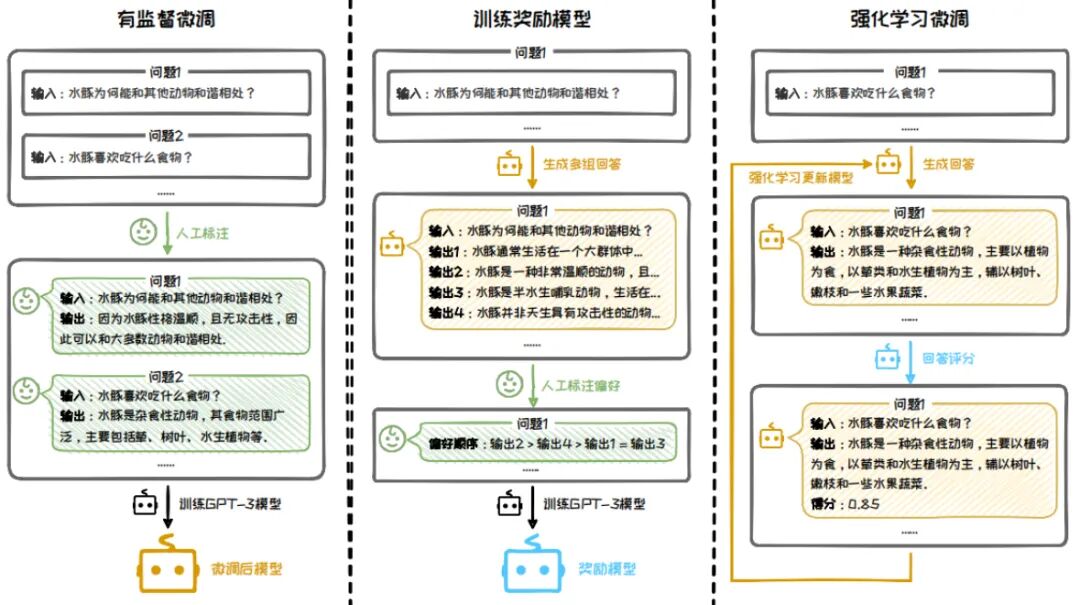
关于强化学习对齐的方法,这里主要有三种:PPO、DPO、GRPO。
近端策略优化[PPO](Schulman et al., 2017)是一种广泛应用于大语言模型强化学习精调阶段的演员-评论家强化学习算法。OpenAI 在大多数任务中使用的强化学习算法都是近端策略优化算法(Proximal Policy Optimization, PPO)。近端策略优化可以根据奖励模型获得的反馈优化模型,通过不断的迭代,让模型探索和发现更符合人类偏好的回复策略。
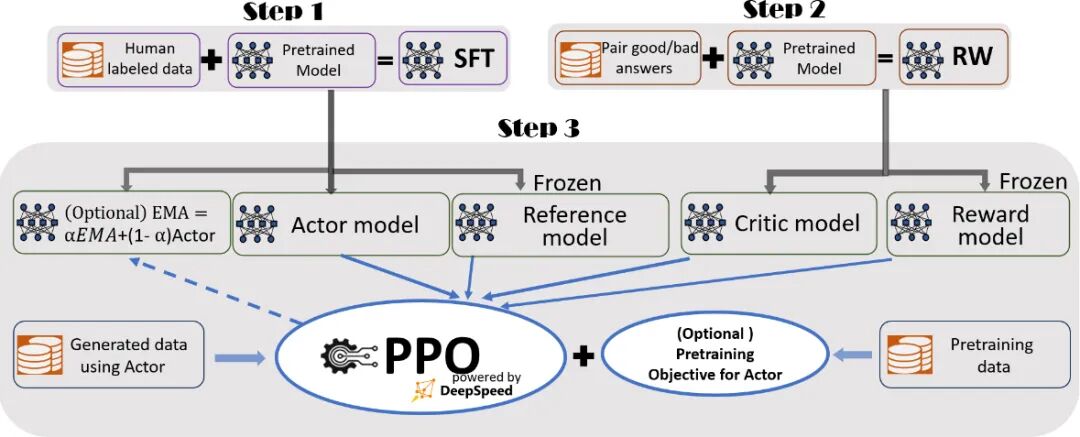
然后为了克服 RLHF 在计算效率上的缺陷,斯坦福大学在 2023 年在其基础上,提出了一种新的算法直接偏好优化(DPO)算法,成为中小模型的优选对齐方案。PPO需同时训练策略、奖励、评论、参考4个模型,且需在线采样数据,计算资源消耗大。DPO核心改进:跳过“奖励模型训练”步骤,直接用“人类偏好数据”优化LLM策略,仅需2个模型(策略模型+参考模型),无需在线采样。
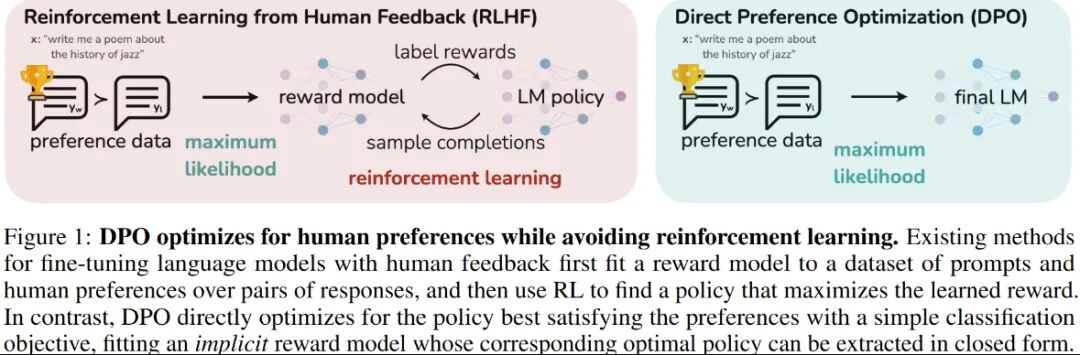
当然DPO也有一些缺点:样本利用率低:依赖离线标注数据,训练效率低,且易出现策略与数据不匹配问题。
组相对策略优化(Group Relative Policy Optimization, GRPO):是一种节省训练成本的RL框架,它避免了通常与policy model相同大小的critic model(value model),而是基于组得分估计基线。GRPO 的改进
- • 组内奖励标准化:对每个问题生成多个输出(组),用组内奖励的均值和标准差进行归一化。
- • 优势计算简化:直接使用归一化后的奖励作为优势值,无需评论家模型。
- • KL 散度正则化:通过无偏估计直接约束策略与参考模型的差异,避免奖励计算复杂化。
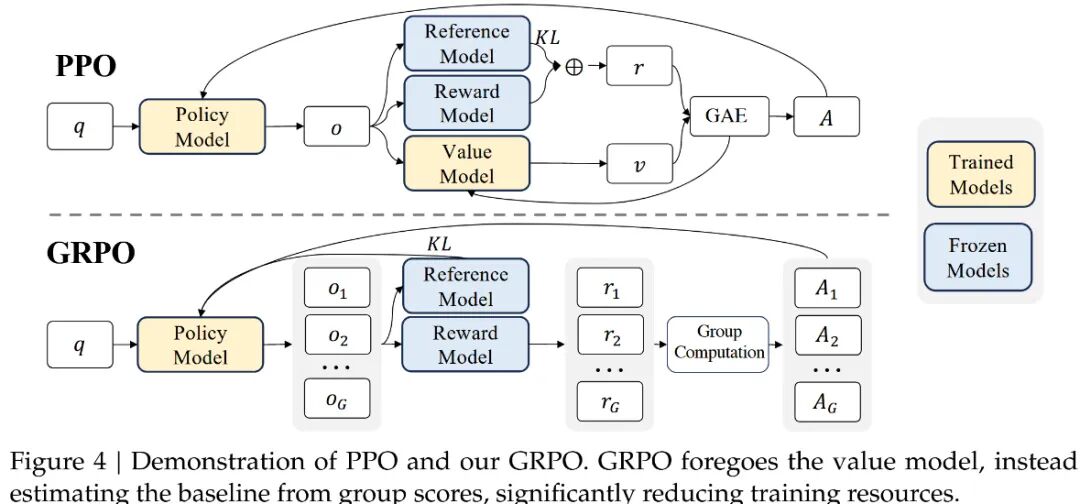
GRPO的核心是通过组内相对奖励优化策略(通过采样一组输出,计算这些输出的奖励,并根据奖励的相对值来更新模型参数。对每个输入状态,采样一组动作(如多个回答),通过奖励函数评估后,计算组内相对优势。这已经有过程对齐的那味儿了。
前面介绍了这么多还都是局部优化,之前的文章介绍了,未来的Agentic AI是强调自主规划、反馈迭代的能力,这块怎么训练呢。
🚀 三、下一代训练方法:解决三大核心挑战
1. 预训练革新:质量 > 规模
DeepSeek强调数据治理的核心地位:
- 过滤仇恨、暴力、侵权内容
- 算法+人工降低统计偏见
- 主动清除个人信息(即使偶然混入)
2. 优化训练:从SFT到Agentic微调
下一代训练将融合:
- Self-Improvement:模型生成高质量指令数据(如R1-Zero)
- 工具学习:调用API、搜索、代码解释器完成复杂任务
- 多智能体辩论:多个Agent协作验证答案可靠性
3. 推理架构:Agentic化部署
模型服务不再仅是“文本生成器”,而是具备记忆、规划、工具使用能力的智能体:
Agentic AI将动态整合外部知识(RAG)、程序执行(Code Interpreter)和长期记忆(Vector DB),实现“思考-行动”闭环。
蚂蚁团队给出的答案不是一个新算法,而是一个基础设施级别的解决方案——AWORLD框架。 你可以将 AWORLD 理解为一个为AgentAI量身打造的、高度优化的分布式计算与训练编排系统。它的核心贡献可以概括为以下三点: 1. 大规模并行执行:AWORLD 的核心设计思想是“分而治之”。它不再让一个Agent孤军奋战,而是利用Kubernetes(K8s)集群,同时启动成百上千个独立的、并行的环境。每个环境里都有一个Agent的“克隆”在尝试解决任务。这样一来,原来需要线性累加的尝试时间,现在被压缩到了接近单次尝试的时间。 2. 解耦的系统架构:AWORLD 将Agent训练的整个流程巧妙地解耦为两个主要部分: * • 推理/执行端:负责Agent与环境的高并发交互,即大规模的“实践”(Rollout)。 * • 训练端:负责收集所有“实践”数据,进行分析和学习,即更新模型参数。 这种设计允许为不同的任务匹配最合适的硬件资源,例如,用GPU集群进行高效的模型推理和训练,用CPU集群来承载大量的环境实例,从而最大化资源利用率。 3. 一套完整的“训练配方”:论文不仅提供了工具(AWORLD),更提供了一套可复现的、端到端的 Agentic AI 训练“配方”。这个配方结合了监督微调(SFT)和强化学习(RL),让模型能够平滑地从“模仿专家”过渡到“自我进化”。 🛡️ 四、对抗幻觉:Agentic AI的全新解法
DeepSeek指出当前大模型存在幻觉、偏见、滥用三大风险。下一代训练将通过:
-
红队测试(Red Teaming):模拟攻击训练模型抗干扰能力
-
可信验证链(Chain-of-Verification):强制模型分步验证输出
-
安全对齐(Safety Alignment):构造安全数据注入价值观
Agentic框架中,模型需展示推理过程,人类可实时干预修正(如“暂停生成,这一步证据不足”)
🔮 未来展望:开源生态与AGI路径
DeepSeek的全模型开源(MIT协议) 为Agentic AI社区化奠定基础。MoE+Agentic架构将推动模型向:
- 超级专家系统:医疗/法律等垂直领域MoE专家协作
- 社会智能体(Social Agent):理解人类意图并主动服务
- 可解释AI(XAI):全程可视化推理路径
“真正的AGI不是更大的参数,而是更自主的思考。”
——DeepSeek模型报告结语

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

参考资料
- DeepSeek 模型算法披露说明
- Google: Mixture of Experts for Efficient LLM Training
- Stanford: The Rise of Agentic AI Architectures
- AWorld: Orchestrating the Training Recipe for Agentic AI
推荐学习图解大模型

随着大模型的持续火爆,各行各业纷纷开始探索和搭建属于自己的私有化大模型,这无疑将催生大量对大模型人才的需求,也带来了前所未有的就业机遇。**正如雷军所说:“站在风口,猪都能飞起来。”**如今,大模型正成为科技领域的核心风口,是一个极具潜力的发展机会。能否抓住这个风口,将决定你是否能在未来竞争中占据先机。
那么,我们该如何学习大模型呢?
人工智能技术的迅猛发展,大模型已经成为推动行业变革的核心力量。然而,面对复杂的模型结构、庞大的参数量以及多样的应用场景,许多学习者常常感到无从下手。作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。
为此,我们整理了一份全面的大模型学习路线,帮助大家快速梳理知识,形成自己的体系。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
大型预训练模型(如GPT-3、BERT、XLNet等)已经成为当今科技领域的一大热点。这些模型凭借其强大的语言理解和生成能力,正在改变我们对人工智能的认识。为了跟上这一趋势,越来越多的人开始学习大模型,希望能在这一领域找到属于自己的机会。
L1级别:启航篇 | 极速破界AI新时代
- AI大模型的前世今生:了解AI大模型的发展历程。
- 如何让大模型2C能力分析:探讨大模型在消费者市场的应用。
- 行业案例综合分析:分析不同行业的实际应用案例。
- 大模型核心原理:深入理解大模型的核心技术和工作原理。

L2阶段:攻坚篇 | RAG开发实战工坊
- RAG架构标准全流程:掌握RAG架构的开发流程。
- RAG商业落地案例分析:研究RAG技术在商业领域的成功案例。
- RAG商业模式规划:制定RAG技术的商业化和市场策略。
- 多模式RAG实践:进行多种模式的RAG开发和测试。

L3阶段:跃迁篇 | Agent智能体架构设计
- Agent核心功能设计:设计和实现Agent的核心功能。
- 从单智能体到多智能体协作:探讨多个智能体之间的协同工作。
- 智能体交互任务拆解:分解和设计智能体的交互任务。
- 10+Agent实践:进行超过十个Agent的实际项目练习。

L4阶段:精进篇 | 模型微调与私有化部署
- 打造您的专属服务模型:定制和优化自己的服务模型。
- 模型本地微调与私有化:在本地环境中调整和私有化模型。
- 大规模工业级项目实践:参与大型工业项目的实践。
- 模型部署与评估:部署和评估模型的性能和效果。

专题集:特训篇
- 全新升级模块:学习最新的技术和模块更新。
- 前沿行业热点:关注和研究当前行业的热点问题。
- AIGC与MPC跨领域应用:探索AIGC和MPC在不同领域的应用。

掌握以上五个板块的内容,您将能够系统地掌握AI大模型的知识体系,市场上大多数岗位都是可以胜任的。然而,要想达到更高的水平,还需要在算法和实战方面进行深入研究和探索。
- AI大模型学习路线图
- 100套AI大模型商业化落地方案
- 100集大模型视频教程
- 200本大模型PDF书籍
- LLM面试题合集
- AI产品经理资源合集
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,全面覆盖了AI大模型的理论探索、技术落地与行业实践等多个维度。无论您是从事科研工作的学者、专注于技术开发的工程师,还是对AI大模型充满兴趣的爱好者,这套报告都将为您带来丰富的知识储备与深刻的行业洞察,助力您更深入地理解和应用大模型技术。
三、大模型经典PDF籍
随着人工智能技术的迅猛发展,AI大模型已成为当前科技领域的核心热点。像GPT-3、BERT、XLNet等大型预训练模型,凭借其卓越的语言理解与生成能力,正在重新定义我们对人工智能的认知。为了帮助大家更高效地学习和掌握这些技术,以下这些PDF资料将是极具价值的学习资源。

四、AI大模型商业化落地方案
AI大模型商业化落地方案聚焦于如何将先进的大模型技术转化为实际的商业价值。通过结合行业场景与市场需求,该方案为企业提供了从技术落地到盈利模式的完整路径,助力实现智能化升级与创新突破。

希望以上内容能对大家学习大模型有所帮助。如有需要,请微信扫描下方CSDN官方认证二维码免费领取相关资源【保证100%免费】。

祝大家学习顺利,抓住机遇,共创美好未来!
更多推荐


 20
20 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)