
单智能体的痛点,是多智能体的起点:详解多智能体的四种架构与实践
文章摘要: 本文探讨了从单Agent转向多智能体系统的必要性,分析了单Agent在处理复杂任务时的三大痛点:认知过载、工具混杂和状态混乱。作者提出多智能体协作方案,通过LangGraph框架实现四种典型架构模式(网络/主管/工具调用/分层),并重点演示了子图共享状态的实现方法。文章包含完整代码示例,展示如何构建一个包含摘要和评分功能的问答系统,利用父子图状态共享机制实现智能体间高效协作。最后还提供
最近在折腾大模型应用开发的时候,我突然意识到一个事儿:再牛的单Agent,也像是一个独行侠,遇到复杂任务就容易翻车。想想看,你让一个程序员一个人扛起整个项目,从需求分析到编码、测试、部署,最后上线——他再天才,也得累趴下吧?现实中,我们靠团队分工协作才高效,为什么AI就不行呢?
今天这篇文,我就带大家从头捋一捋,怎么用LangGraph构建一个多智能体系统。不是空谈理论,我会一步步贴代码、解释逻辑,保证你跟着敲键盘就能跑起来。咱们的目标:从简单聊天机器人,升级到能自主协作的“AI团队”。
一、为什么单Agent总卡壳?多智能体来救场
1.1 Agent到底算啥?定义还在打架
业内对Agent的定义,现在还挺乱的。宽松点说,只要接入大模型,能聊两句就算;严格派则觉得,必须像人一样思考、决策、搞定复杂活儿才行。OpenAI的路线图挺靠谱的参考:
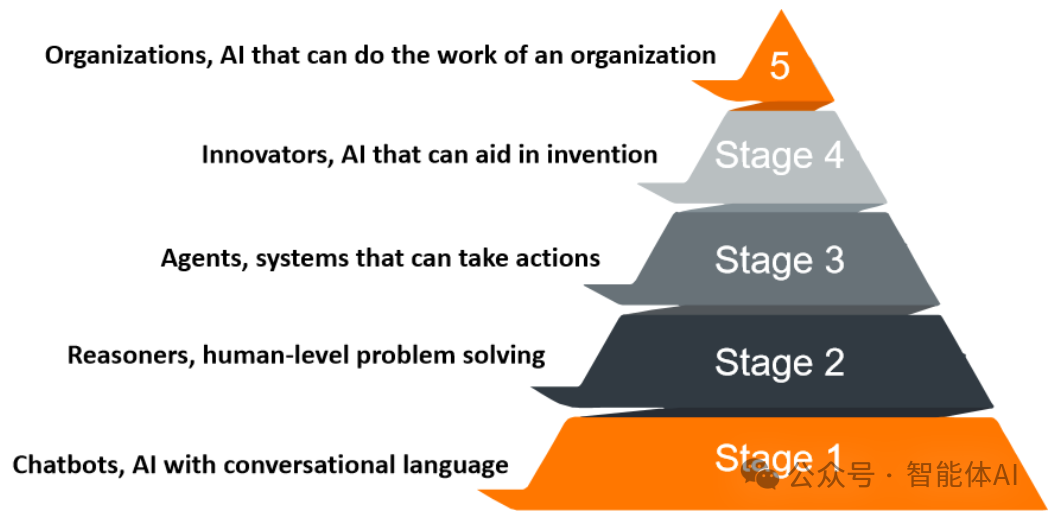
- Stage 1:聊天机器人,像ChatGPT,纯对话。
- Stage 2:推理者,o1-preview那种,能简单解决问题。
- Stage 3:Agent,能替你自主干活——这就是咱们今天的主角。
- Stage 4:创新者,帮助发明新东西。
- Stage 5:组织级AI,包揽整个团队的工作。
我个人觉得,Agent不是终点,而是起点。单干太累,得多Agent组队才行。

1.2 单Agent的三大“痛点”,你中招了吗?
给一个Agent塞二三十个工具,让它处理业务时,常碰壁:

Agent崩溃:我是谁?我在干嘛?
1.3 团队协作:像公司分工一样解锁效率
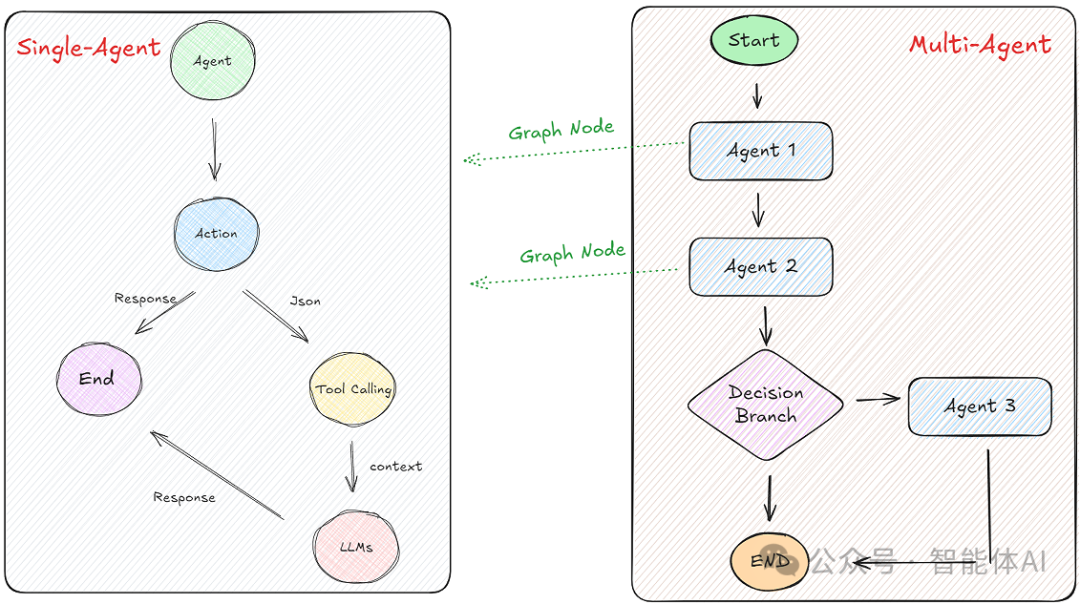
单Agent像一个人扛活儿,多Agent则是团队协作。代码上对比下:

分工明确,协作顺畅——这就是多智能体的魅力。
二、多智能体系统的“入门课”
2.1 啥是多智能体系****统?简单说,就是拆分+协作
Multi-Agent Systems (MAS):把大应用拆成小Agent,让它们分工合作。三大好处:
- 专业化:每个Agent专攻一域,不再全能尴尬。
- 模块化:独立开发、测试、维护,像乐高积木。
- 可控性:通信方式自己定,不乱套。
2.2 LangGraph里的四种玩法,选一个上手
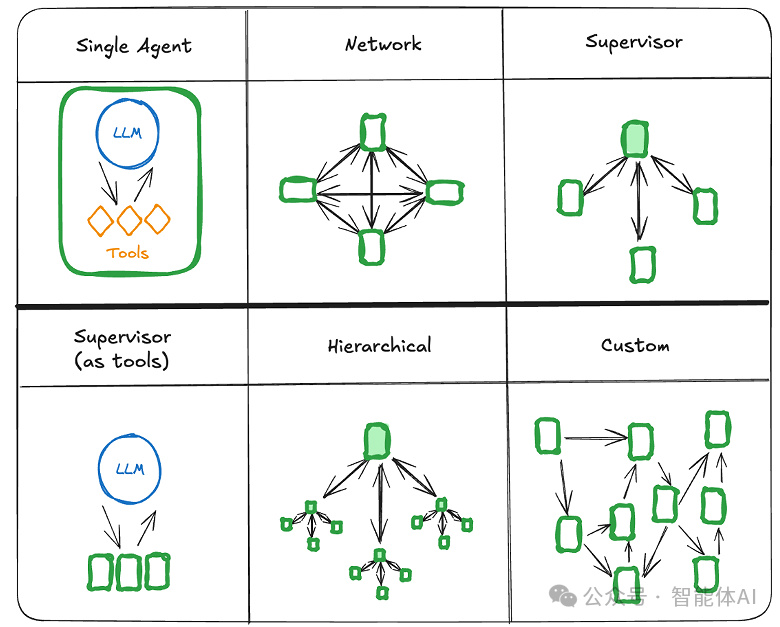
LangGraph是LangChain的扩展,专治图状工作流。常见架构:
1. Network(网络)模式
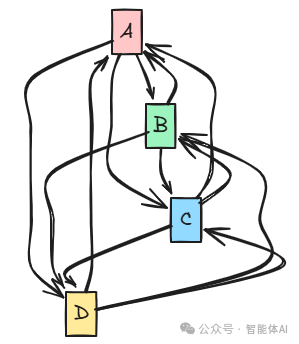
Agent间自由通信,类似网状拓扑。每个Agent都可以直接与其他Agent通信。
2. Supervisor(主管)模式
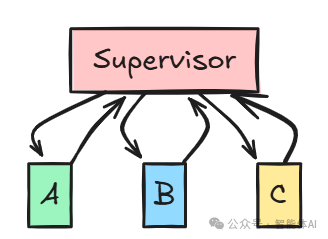
所有Agent都通过一个中心Supervisor进行通信,Agent之间不直接通信。
3. Supervisor (tool-calling) 模式
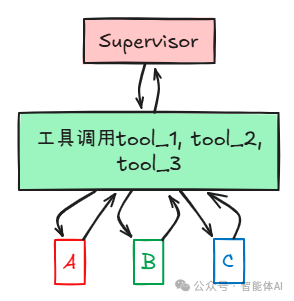
Supervisor通过工具调用来调度Agent,工具作为中间层。
4. Hierarchical(分层)模式
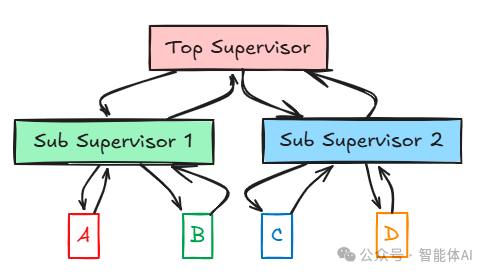
分层管理结构,顶层Supervisor管理子Supervisor,子Supervisor再管理Agent。
三、Subgraphs实战——让Agent“对话”起来
在具体实践各个不同多代理架构下的具体应用方法之前,我们需要结合LangGraph构建图的机制去思考一个问题:通过**State**可以让一个图中的所有节点共享全局的信息,那么在多代理架构中,当每一个图变成了一个节点,那么不同图之间的状态,应该怎么传递?
3.1 Subgraphs是啥?子图当节点用
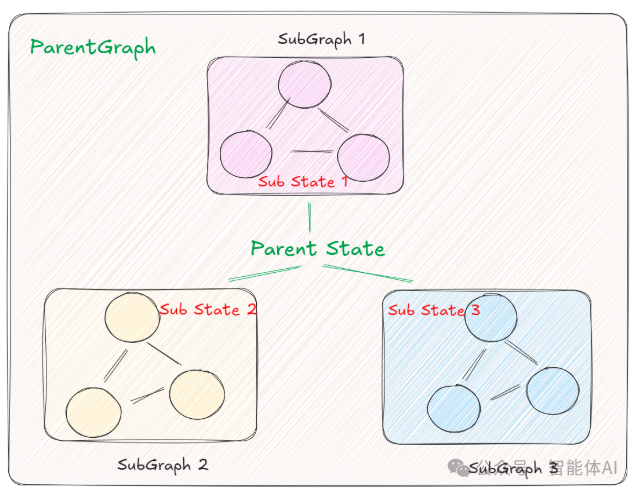
核心:Subgraph是可复用的“图块”,父图里塞进去,就能共享状态。简单比喻:

状态共享,父子聊天无障碍。
3.2 案例:建个评分系统(父子共享状态键)
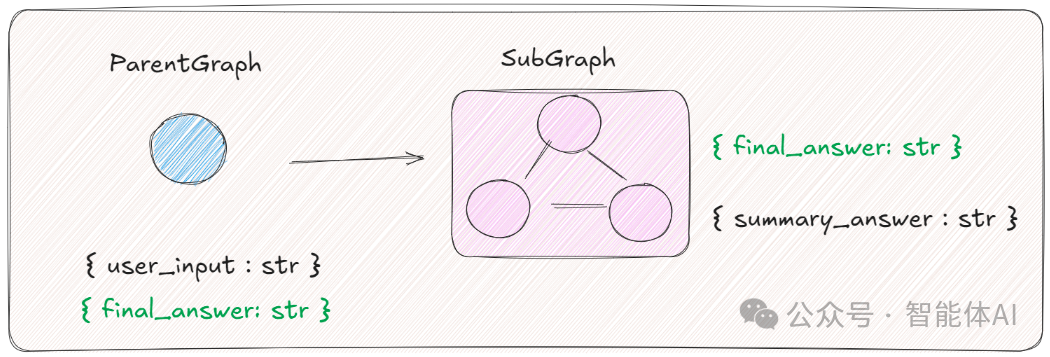
咱们做一个:用户问问题 → 生成答案 → 子图摘要+评分。

本地Ollama(推荐新手,免费):
先装Ollama(macOS: curl -fsSL https://ollama.com/install.sh | sh),拉模型ollama pull qwen2.5:72b,启动ollama serve。
from langchain_ollama import ChatOllama
llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5:72b", temperature=0)
print(llm.invoke("你好,请介绍一下你自己").content)

3.2.6 子图节点
摘要节点:
def subgraph_node_1(state: SubgraphState):
system_prompt = "请将你收到的内容总结为50字以内的摘要。要求:简洁、准确、保留核心信息。"
messages = [
SystemMessage(content=system_prompt),
HumanMessage(content=state['final_answer'].content)
]
response = llm.invoke(messages)
return {"summary_answer": response}

3.2.7 组子图
subgraph_builder = StateGraph(SubgraphState)
subgraph_builder.add_node("subgraph_node_1", subgraph_node_1)
subgraph_builder.add_node("subgraph_node_2", subgraph_node_2)
subgraph_builder.add_edge(START, "subgraph_node_1")
subgraph_builder.add_edge("subgraph_node_1", "subgraph_node_2")
subgraph = subgraph_builder.compile()
# 测试
test_input = {"final_answer": HumanMessage(content="人工智能是计算机科学的一个分支...")}
result = subgraph.invoke(test_input)
print(result['final_answer'])
流式看过程:
import asyncio
async def stream_test():
async for chunk in graph.astream({"user_input": "如何理解RAG技术?"}, stream_mode='values'):
print(chunk)
await stream_test()
子图测试:
async def subgraph_test():
async for chunk in graph.astream({"user_input": "什么是Transformer架构?"}, stream_mode='values', subgraphs=True):
print(chunk)
await subgraph_test()
3.3 无共享键?加个“翻译官”
父子状态键不同时,用中间节点转换。

关键:转换就是桥,状态不匹配时手动桥接。
四、Network架构实战——BI数据分析系统
4.1 整体设计:用户意图 → DB操作 → 代码生成 → 可视化
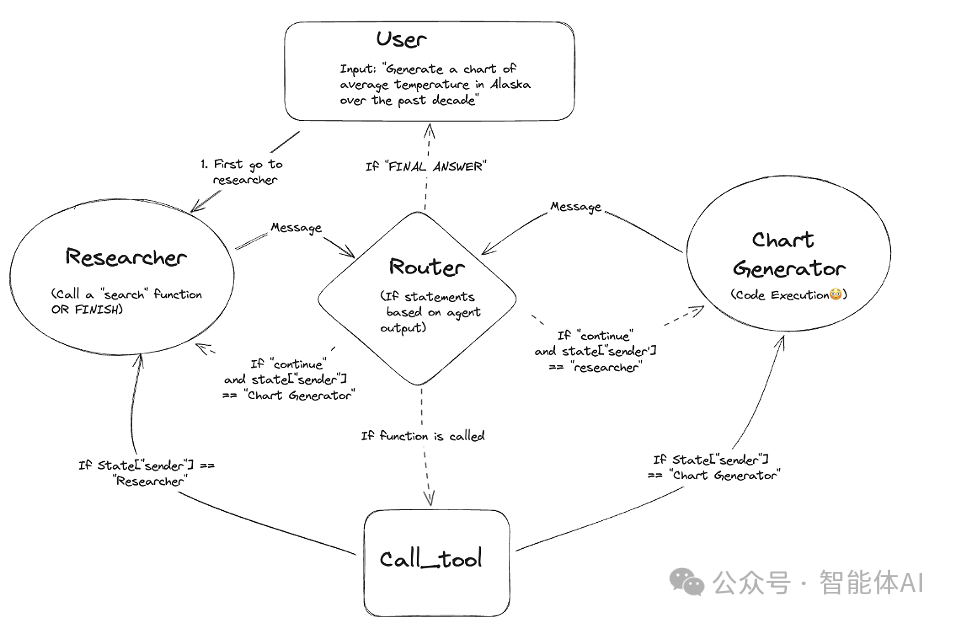
用户说“上月销售额Top5” → DBAdmin查数据 → CodeAnalyst写SQL/代码 → Visualizer出图。
4.2 环境+数据库
依赖:
pip install -U langchain langchain_openai langsmith pandas langchain_experimental matplotlib langgraph langchain_core sqlalchemy pymysql faker langchain_ollama
MySQL(Docker):
docker run --name mysql-test -e MYSQL_ROOT_PASSWORD=your_password -e MYSQL_DATABASE=langgraph_agent -p 3306:3306 -d mysql:8.0
模型:
from langchain_openai import ChatOpenAI
from langchain_ollama import ChatOllama
db_llm = ChatOpenAI(model="gpt-4o-mini", temperature=0) # DB用
coder_llm = ChatOllama(base_url="http://localhost:11434", model="qwen2.5-coder:32b", temperature=0) # 代码用
4.3 建表
from sqlalchemy import create_engine, Column, Integer, String, Float, ForeignKey
from sqlalchemy.orm import sessionmaker, declarative_base
Base = declarative_base()
class SalesData(Base):
__tablename__ = 'sales_data'
sales_id = Column(Integer, primary_key=True, autoincrement=True)
product_id = Column(Integer, ForeignKey('product_information.product_id'))
employee_id = Column(Integer)
customer_id = Column(Integer, ForeignKey('customer_information.customer_id'))
sale_date = Column(String(50))
quantity = Column(Integer)
amount = Column(Float)
discount = Column(Float)
# 其他表:CustomerInformation, ProductInformation, CompetitorAnalysis(类似,略)
DATABASE_URI = 'mysql+pymysql://root:your_password@localhost:3306/langgraph_agent?charset=utf8mb4'
engine = create_engine(DATABASE_URI, echo=True)
Base.metadata.create_all(engine)
Session = sessionmaker(bind=engine)
4.4 造测试数据
from faker import Faker
import random
fake = Faker('zh_CN')
session = Session()
# 客户50条
for i in range(50):
customer = CustomerInformation(customer_name=fake.name(), contact_info=fake.phone_number(), region=fake.province(), customer_type=random.choice(['零售', '批发']))
session.add(customer)
session.commit()
# 产品20条、对手10条、销售100条(类似,略)
session.close()
4.5 工具箱:DB CRUD + 报表
参数Schema(Pydantic):
from pydantic import BaseModel, Field
from langchain_core.tools import tool
class AddSaleSchema(BaseModel):
product_id: int = Field(description="产品ID")
# ... 其他字段
@tool(args_schema=AddSaleSchema)
def add_sale(product_id: int, employee_id: int, customer_id: int, sale_date: str, quantity: int, amount: float, discount: float):
session = get_session()
try:
sale = SalesData(product_id=product_id, employee_id=employee_id, customer_id=customer_id, sale_date=sale_date, quantity=quantity, amount=amount, discount=discount)
session.add(sale)
session.commit()
return f"✓ 添加成功,sales_id={sale.sales_id}"
except Exception as e:
session.rollback()
return f"✗ 添加失败: {e}"
finally:
session.close()
#delete_sale, update_sale 类似
class QuerySalesListSchema(BaseModel):
offset: int = Field(0)
limit: int = Field(50)
region: str = Field(None)
product_name: str = Field(None)
@tool(args_schema=QuerySalesListSchema)
def query_sales_list(offset=0, limit=50, region=None, product_name=None):
session = get_session()
try:
q = session.query(SalesData.sales_id, SalesData.sale_date, SalesData.quantity, SalesData.amount, SalesData.discount,
ProductInformation.product_name, CustomerInformation.customer_name, CustomerInformation.region
).join(ProductInformation).join(CustomerInformation)
if region: q = q.filter(CustomerInformation.region == region)
if product_name: q = q.filter(ProductInformation.product_name.like(f"%{product_name}%"))
q = q.offset(offset).limit(limit)
rows = q.all()
result = [{"sales_id": r.sales_id, "sale_date": r.sale_date, "quantity": r.quantity, "amount": float(r.amount), "discount": float(r.discount),
"product_name": r.product_name, "customer_name": r.customer_name, "region": r.region} for r in rows]
return result
except Exception as e:
return {"error": str(e)}
finally:
session.close()
class SalesReportSchema(BaseModel):
group_by: str = Field("region")
top_n: int = Field(10)
start_date: str = Field(None)
end_date: str = Field(None)
@tool(args_schema=SalesReportSchema)
def generate_sales_report(group_by="region", top_n=10, start_date=None, end_date=None):
session = get_session()
try:
if group_by == "region":
group_col = CustomerInformation.region
labels = "region"
# ... 其他group_by
q = session.query(group_col.label("group_val"), func.sum(SalesData.amount).label("total_amount"), func.sum(SalesData.quantity).label("total_quantity")
).join(ProductInformation).join(CustomerInformation)
if start_date: q = q.filter(SalesData.sale_date >= start_date)
if end_date: q = q.filter(SalesData.sale_date <= end_date)
q = q.group_by(group_col).order_by(func.sum(SalesData.amount).desc()).limit(top_n)
rows = q.all()
df = pd.DataFrame([{"group": r.group_val, "total_amount": float(r.total_amount), "total_quantity": int(r.total_quantity)} for r in rows])
# 画图
fig, ax = plt.subplots(figsize=(8, 4))
ax.bar(df["group"].astype(str), df["total_amount"])
ax.set_title(f"Sales by {group_by}")
ax.set_ylabel("total_amount")
ax.set_xlabel(group_by)
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
buf = io.BytesIO()
fig.savefig(buf, format="png")
buf.seek(0)
chart_bytes = buf.read()
buf.close()
plt.close(fig)
return {"table": df.to_dict(orient="records"), "chart_bytes": chart_bytes}
except Exception as e:
return {"error": str(e)}
finally:
session.close()
五、组队!Network多Agent实现
5.1 每个Agent一个子图
DBAdmin子图:
class DBAdminState(TypedDict):
query_intent: str
sql: str
query_result: list
def dbadmin_node_parse_intent(state: DBAdminState):
prompt = f"把这个用户意图翻译成 SQL(MySQL): {state['query_intent']}\n只返回 SQL,不要带解释。"
resp = db_llm.invoke(prompt)
return {"sql": resp.content.strip()}
def dbadmin_node_exec_sql(state: DBAdminState):
sql = state["sql"].strip().lower()
if not sql.startswith("select"):
return {"query_result": [{"error": "仅允许 SELECT 查询。"}]}
session = get_session()
try:
res = session.execute(sql).fetchall()
cols = res[0].keys() if res else []
rows = [dict(zip(cols, r)) for r in res]
return {"query_result": rows}
except Exception as e:
return {"query_result": [{"error": str(e)}]}
finally:
session.close()
dbadmin_builder = StateGraph(DBAdminState)
dbadmin_builder.add_node("parse_intent", dbadmin_node_parse_intent)
dbadmin_builder.add_node("exec_sql", dbadmin_node_exec_sql)
dbadmin_builder.add_edge(START, "parse_intent")
dbadmin_builder.add_edge("parse_intent", "exec_sql")
dbadmin = dbadmin_builder.compile()
CodeAnalyst子图:
class CodeAnalystState(TypedDict):
requirement: str
sql: str
code: str
def codeanalyst_generate_sql(state: CodeAnalystState):
prompt = f"""
你是一个 SQL 与 数据分析专家。根据需求生成一条安全的 MySQL SELECT 语句(只返回 SQL),
需求:{state['requirement']}
数据库表结构:sales_data(product_id, sale_date, quantity, amount, customer_id ...),
product_information(product_id, product_name), customer_information(customer_id, region)
"""
resp = coder_llm.invoke(prompt)
return {"sql": resp.content.strip()}
def codeanalyst_generate_code(state: CodeAnalystState):
prompt = f"根据 SQL
{state['sql']}
,写一段 Python (pandas) 代码:读取查询结果的 JSON 转成 DataFrame 并画图。只返回代码,不要解释。"
resp = coder_llm.invoke(prompt)
return {"code": resp.content}
codeanalyst_builder = StateGraph(CodeAnalystState)
codeanalyst_builder.add_node("gen_sql", codeanalyst_generate_sql)
codeanalyst_builder.add_node("gen_code", codeanalyst_generate_code)
codeanalyst_builder.add_edge(START, "gen_sql")
codeanalyst_builder.add_edge("gen_sql", "gen_code")
codeanalyst = codeanalyst_builder.compile()
Visualizer子图:
class VisualizerState(TypedDict):
table: list
chart_bytes: bytes
output_path: str
def visualizer_save_chart(state: VisualizerState):
path = state.get("output_path", "output_chart.png")
if state.get("chart_bytes"):
with open(path, "wb") as f:
f.write(state["chart_bytes"])
return {"output_path": path}
else:
df = pd.DataFrame(state["table"])
fig, ax = plt.subplots(figsize=(8,4))
if "group" in df.columns and "total_amount" in df.columns:
ax.bar(df["group"].astype(str), df["total_amount"])
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
fig.savefig(path)
plt.close(fig)
return {"output_path": path}
visualizer_builder = StateGraph(VisualizerState)
visualizer_builder.add_node("save_chart", visualizer_save_chart)
visualizer_builder.add_edge(START, "save_chart")
visualizer = visualizer_builder.compile()
5.2 父图Orchestrator:串联Network
class ParentStateNetwork(TypedDict):
user_input: str
generated_sql: str
query_result: list
generated_code: str
report_path: str
def parent_node_receive_input(state: ParentStateNetwork):
return {"generated_sql": None, "query_result": None, "generated_code": None, "report_path": None}
def parent_node_call_codeanalyst(state: ParentStateNetwork):
sub_in = {"requirement": state["user_input"]}
sub_out = codeanalyst.invoke(sub_in)
return {"generated_sql": sub_out.get("sql"), "generated_code": sub_out.get("code")}
def parent_node_call_dbadmin(state: ParentStateNetwork):
sub_in = {"query_intent": state["generated_sql"]}
sub_out = dbadmin.invoke(sub_in)
return {"query_result": sub_out.get("query_result", [])}
def parent_node_call_visualizer(state: ParentStateNetwork):
report = generate_sales_report(group_by="product_name", top_n=10)
chart_bytes = report.get("chart_bytes")
if chart_bytes:
path = "report_by_product.png"
with open(path, "wb") as f:
f.write(chart_bytes)
return {"report_path": path}
return {"report_path": None}
parent_builder = StateGraph(ParentStateNetwork)
parent_builder.add_node("start", parent_node_receive_input)
parent_builder.add_node("call_codeanalyst", parent_node_call_codeanalyst)
parent_builder.add_node("call_dbadmin", parent_node_call_dbadmin)
parent_builder.add_node("call_visualizer", parent_node_call_visualizer)
parent_builder.add_edge(START, "start")
parent_builder.add_edge("start", "call_codeanalyst")
parent_builder.add_edge("call_codeanalyst", "call_dbadmin")
parent_builder.add_edge("call_dbadmin", "call_visualizer")
parent_graph = parent_builder.compile()
5.3 跑起来
input_state = {"user_input": "请给我上个月每个地区销售额前5名的产品和金额。"}
result = parent_graph.invoke(input_state)
print("生成的 SQL:", result.get("generated_sql"))
print("查询结果(样例):", result.get("query_result")[:3])
print("报告路径:", result.get("report_path"))
Agent间通过状态传递“聊天”,Network就这么活了。
六、测试调试,别让小Bug毁了大局
6.1 单元测试建议
- 把每个工具(add_sale、query_sales_list 等)写成可独立测试的函数,使用 SQLite 内存库(
sqlite:///:memory:)做 CI 测试。 - 对 LLM 输出解析写 mock 测试:把 llm.invoke 替换成固定返回值,确保 pipeline 在不依赖模型时也能跑通。
6.2 本地调试技巧
- 在 测试 中使用
graph.astream(..., stream_mode='values', subgraphs=True)来观察每一步的中间状态(前文已演示)。 - 打开 SQLAlchemy 的
echo=True,观察生成的 SQL,确认没有注入或语法问题。 - 对所有外部输入(user_input, generated_sql)做白名单与正则校验,避免 accidentally destructive queries(例如不允许
delete|drop|update)。
6.3 常见错误及解决
- 错误:
llm.invoke返回对象不是字符串 -> 解决:统一处理.content或.text字段。 - 错误:子图返回结构不符合父图预期 -> 解决:在父图调用前加一个“适配器”节点(翻译官模式),做字段名转换与类型校验。
- 错误:并发写 DB 导致锁 -> 解决:Session scope 改成短生命周期、或者使用连接池参数、对写操作加重试策略。
七、上线前 checklist——生产化别马虎
-
权限与隔离
-
- 只有 DBAdminAgent 才有写权限;CodeAnalyst/Visualizer 应只拥有只读或无 DB 权限。
- 把危险 SQL 过滤在网关层(禁止
drop|truncate|delete等)。
-
可观测性
-
- 每个 Agent 的调用都打 trace(请求 id),并且记录输入摘要、输出摘要、耗时、调用的工具名。
- 使用 Prometheus + Grafana 监控延迟、错误率、模型调用成本。
-
成本控制
-
- 对每个 LLM 调用设置超时与 token 上限。
- 对复合任务拆成多步并缓存中间结果(重复查询复用结果),避免重复消费模型 token。
-
重试与幂等
-
- 工具(尤其是写操作)需要幂等设计或乐观锁机制。
- 对外部 API 抽象出重试策略(指数回退)。
-
安全审计
-
- 所有生成的 SQL/代码都应被记录,方便审计。
- 对生成代码设置沙箱执行(例如 Docker 容器,限制网络/文件权限)。
-
灰度与回滚
-
- 首次启用新 Agent 或新能力时做灰度(比如 5% 流量)。
- 监控用户行为与 KPI(一旦异常即可回滚)。
八、扩展与演进(后面持续分享)
-
引入 Supervisor 模式
-
- 当 Agent 数量与责任边界增多时,把 Orchestrator 升级为 Supervisor:负责权限分配、任务拆分、失败补偿;Agent 专注执行。
-
能力发现(Capability Registry)
-
- 为每个 Agent 注册能力标签(例如:
"sql_read","sql_write","chart_png")。Supervisor 根据任务需要动态路由到最合适 Agent。
- 为每个 Agent 注册能力标签(例如:
-
多模型协同
-
- 把不同能力绑定到不同模型(db_llm 用对话模型,coder_llm 用 code 模型,另用 smaller LLM 做校验与评分),通过能力矩阵选择模型。
-
强化学习/在线学习
-
- 对 Agent 的决策策略做在线评估(A/B),并逐步调整生成 SQL 或提示词以提高准确率。
九、如何避免智能体提桶跑路
1、Agent 会随意执行 DROP/DELETE 吗?
写操作只能通过限定工具(如 add_sale)完成,并受权限控制。
2、如何避免 LLM “幻觉”生成错误 SQL?
采用多重校验:CodeAnalyst 生成 SQL → SQL 静态解析器(AST)校验 → DBAdmin 执行前再做规则检测(禁止子句/函数等)。
3、模型调用太慢,怎么优化?
- 缓存常见 prompt 的响应;
- 分层模型策略(先用小模型做意图解析,再用大模型做结果生成);
- 减少不必要的往返调用,合并请求。
十、部署前10问自查
- 模型 Key 与服务地址已妥善管理(不要放在代码里)。
- DB 用户权限最小化(读/写分离)。
- 工具入参已做严格 Pydantic 校验。
- 所有 LLM 输出统一走 parse + 验证流程(防注入/幻觉)。
- 超时、重试、熔断策略已配置。
- 日志(trace id)与监控已接入。
- 单元测试覆盖工具函数(尤其是 DB 写入)。
- 灰度发布与回滚流程已设计。
- 隐私/合规检查(若涉及用户数据)。
- 文档与运行手册完备(让运维/产品能读懂)。
十一、总结
多智能体并不是把“所有工作拆成更多模型调用”,而是设计清晰的职责边界、可靠的通信协议、以及可观测的运行平台。LangGraph 提供了把子图当作节点复用与组合的能力,让我们能把复杂业务以工程化的方式分层落地。
本文从基础概念讲到可运行代码、到生产化考量,目标是让你拿到一套可复制的 blueprint:
1)、把职责拆清楚(谁做什么)
2)、把接口标准化(状态与工具)
3)、把运行管控好(监控、权限、成本)
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,人才需求急为紧迫!
由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
包括:AI大模型学习路线、LLM面试宝典、0基础教学视频、大模型PDF书籍/笔记、大模型实战案例合集、AI产品经理合集等等
大模型学习之路,道阻且长,但只要你坚持下去,一定会有收获。本学习路线图为你提供了学习大模型的全面指南,从入门到进阶,涵盖理论到应用。
L1阶段:启航篇|大语言模型的基础认知与核心原理
L2阶段:攻坚篇|高频场景:RAG认知与项目实践
L3阶段:跃迀篇|Agent智能体架构设计
L4阶段:精进篇|模型微调与私有化部署
L5阶段:专题篇|特训集:A2A与MCP综合应用 追踪行业热点(全新升级板块)





AI大模型全套学习资料【获取方式】
更多推荐


 8
8 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)