
从零入门 CrewAI:多智能体协作框架实战指南(附完整源码)
在大模型应用开发中,单一 AI 模型往往难以应对复杂任务场景。而 CrewAI 作为一款开源多智能体编排框架,通过模拟现实团队协作模式,让不同角色的 AI 智能体自主分工、协同完成任务,极大拓展了 AI 应用的边界。本文将结合基础理论与实战案例,带大家从零掌握 CrewAI 的核心用法,文末还附上可直接运行的完整源码,助力快速上手。

一、认识 CrewAI:多智能体协作的 “团队管理者”
1.1 什么是 CrewAI?
CrewAI 是由 João Moura 开发的开源多智能体框架,基于 LangChain 构建,核心目标是协调多个 AI 智能体协作完成复杂任务。它模拟现实世界中 “团队分工” 模式,每个智能体拥有明确角色、目标和技能,能自主委派任务、共享信息,最终实现 “1+1>2” 的协作效果。
相比单一语言模型,CrewAI 的优势在于:无需手动拆分任务流程,智能体可根据目标自动协同,尤其适合内容创作、市场分析、客户支持等多步骤场景。其官网为https://www.crewai.com/,GitHub 仓库可获取最新源码:https://github.com/crewAIInc/crewAI。
1.2 CrewAI 核心优势
- 角色驱动设计:每个智能体有明确角色(如 “研究员”“撰稿人”)、目标和背景故事,LLM 能更精准地定位任务需求;
- 智能协作能力:智能体间可自主委派任务、共享上下文,无需人工干预流程;
- 灵活工具集成:支持网络搜索、PDF 解析、向量数据库检索等各类工具,轻松扩展功能;
- 生产级就绪:内置内存管理、知识库、可观测性和安全机制,直接适配企业场景;
- 低门槛使用:简洁 API+YAML 配置支持,新手也能快速搭建多智能体系统。
1.3 典型应用场景
- 内容创作:研究员收集资料→撰稿人撰写内容→编辑审核优化,自动化完成博客 / 书籍生成;
- 市场分析:数据采集智能体爬取行业数据→分析师提炼趋势→报告生成器输出可视化结果;
- 客户支持:客服智能体解答基础问题→技术专家处理复杂故障→跟进智能体记录反馈;
- 自动化工作流:数据处理→决策分析→执行落地,全流程无需人工介入。
二、CrewAI 核心概念:理解多智能体协作的 “积木”
要熟练使用 CrewAI,需先掌握 5 个核心组件,它们是搭建多智能体系统的基础 “积木”:
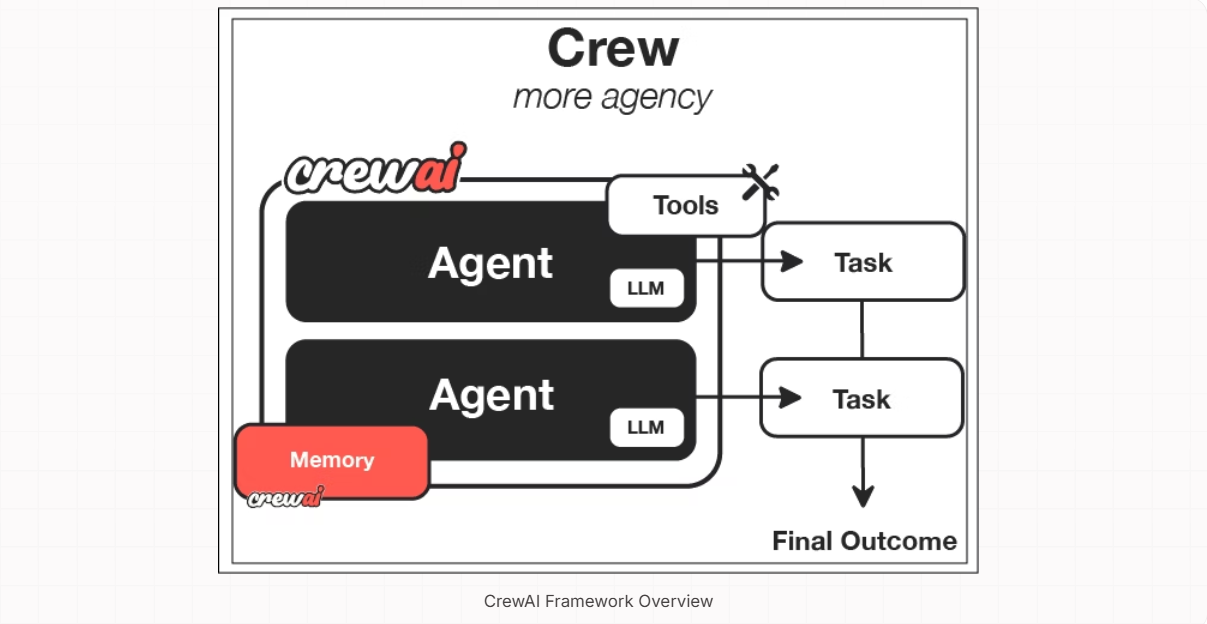
| 组件 | 作用 | 关键属性 |
|---|---|---|
| Agent(智能体) | 执行具体任务的 “团队成员”,拥有特定角色和技能 | role(角色)、goal(目标)、backstory(背景)、tools(工具)、llm(语言模型) |
| Task(任务) | 智能体需完成的具体工作单元 | description(任务描述)、agent(负责智能体)、expected_output(预期输出)、context(任务依赖) |
| Crew(团队) | 组织智能体和任务的 “协调者”,管理协作流程 | agents(智能体列表)、tasks(任务列表)、process(执行流程)、verbose(日志开关) |
| Flow(流程) | 精细化控制任务流,支持条件逻辑、循环 | @start(流程起点)、@listen(事件监听)、@router(条件路由)、状态持久化 |
| Tool(工具) | 智能体执行任务的 “武器”,如搜索、解析工具 | 需通过@tool装饰器封装,定义输入输出格式 |
三、环境搭建:5 分钟完成 CrewAI 初始化
3.1 系统要求
- Python 3.10 及以上版本;
- pip 或 uv 包管理器(推荐 pip,兼容性更强)。
3.2 基础安装
通过 pip 安装 CrewAI 核心库和工具集:
# 安装CrewAI框架
pip install crewai
# 安装CrewAI工具集(含常用工具模板)
pip install crewai-tools
# 安装其他依赖(后续实战需用到)
pip install ddgs markitdown chonkie pymilvus sentence-transformers3.3 两种实现方式对比
CrewAI 支持 “纯 Python 代码” 和 “Python+YAML 配置” 两种开发模式,各有适用场景:
| 实现方式 | 优势 | 适用场景 |
|---|---|---|
| 纯 Python 代码 | 灵活度高,可自定义复杂逻辑 | 需动态调整智能体 / 任务的场景 |
| Python+YAML 配置 | 结构清晰,配置与逻辑分离 | 任务流程固定、需频繁修改参数的场景 |
本文将以 “Python+YAML 配置” 为例(推荐新手优先掌握),兼顾灵活性与可维护性。
四、实战案例:打造 “PDF 成绩查询助手”
我们将开发一个实用工具:上传 PDF 成绩单后,用户可查询指定学生的成绩,核心流程为:
- 检索智能体:优先从 PDF 中提取成绩信息,若无结果则调用网络搜索;
- 响应合成智能体:将检索到的信息整理为自然语言回答;
- 团队协作:通过 Crew 管理两个智能体,按顺序执行任务。
4.1 项目结构
先创建如下目录结构,确保代码模块化:
crewAI_grade_assistant/
├── src/
│ ├── config/ # YAML配置文件
│ │ ├── agents.yaml # 智能体配置
│ │ └── tasks.yaml # 任务配置
│ ├── tools/ # 自定义工具
│ │ ├── custom_tool.py # PDF检索工具(基于Milvus)
│ │ └── ddgs_tools.py # 网络搜索工具
│ ├── crew.py # 团队编排逻辑
│ └── main.py # 项目入口
└── file/ # 存储PDF文件
└── 成绩单.pdf # 待查询的成绩单PDF
4.2 核心代码实现
1. 工具封装:实现 PDF 检索和网络搜索
首先编写工具代码,让智能体拥有 “读取 PDF” 和 “联网搜索” 的能力。
tools/custom_tool.py(PDF 检索工具,基于 Milvus 向量数据库):
import os
import warnings
import logging
from crewai.tools import BaseTool
from typing import Type
from pydantic import BaseModel, Field, ConfigDict
from markitdown import MarkItDown
from chonkie import SemanticChunker
from pymilvus import MilvusClient, DataType, CollectionSchema, FieldSchema
import numpy as np
# 抑制无关警告
warnings.filterwarnings('ignore')
logging.getLogger('pdfminer').setLevel(logging.ERROR)
# 定义工具输入参数模型
class DocumentSearchToolInput(BaseModel):
query: str = Field(..., description="查询以搜索文档(如:高三一班张三的成绩)。")
class DocumentSearchTool(BaseTool):
name: str = "DocumentSearchTool"
description: str = "从指定PDF文档中语义搜索相关内容,优先用于成绩查询。"
args_schema: Type[BaseModel] = DocumentSearchToolInput
model_config = ConfigDict(extra="allow")
def __init__(self, file_path: str):
super().__init__()
self.file_path = file_path
# 连接Milvus向量数据库(需提前启动Milvus服务:http://localhost:19530)
self.client = MilvusClient("http://localhost:19530")
self.collection_name = "grade_collection"
self.embedding_model = "BAAI/bge-small-zh-v1.5" # 中文嵌入模型
self._setup_collection() # 初始化Milvus集合
self._process_document() # 处理PDF并写入数据库
def _setup_collection(self):
"""创建Milvus集合和索引"""
# 定义字段(ID、来源、文档内容、向量嵌入)
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=False),
FieldSchema(name="source", dtype=DataType.VARCHAR, max_length=65535),
FieldSchema(name="document", dtype=DataType.VARCHAR, max_length=65535),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=512)
]
schema = CollectionSchema(fields=fields, description="成绩PDF检索集合")
# 若集合不存在则创建
if not self.client.has_collection(self.collection_name):
self.client.create_collection(collection_name=self.collection_name, schema=schema)
# 创建向量索引(IVF_FLAT适合中小数据量)
index_params = self.client.prepare_index_params()
index_params.add_index(
field_name="embedding",
index_type="IVF_FLAT",
metric_type="L2",
params={"nlist": 128}
)
self.client.create_index(collection_name=self.collection_name, index_params=index_params)
self.client.load_collection(self.collection_name)
def _extract_text(self) -> str:
"""从PDF中提取文本"""
md = MarkItDown()
result = md.convert(self.file_path)
return result.text_content
def _create_chunks(self, raw_text: str) -> list:
"""语义分块(避免文本过长)"""
chunker = SemanticChunker(
embedding_model=self.embedding_model,
threshold=0.5, # 语义相似度阈值
chunk_size=512, # 分块大小(适配嵌入模型维度)
min_sentences=1
)
return chunker.chunk(raw_text)
def _process_document(self):
"""将PDF分块后写入Milvus"""
raw_text = self._extract_text()
chunks = self._create_chunks(raw_text)
docs = [chunk.text for chunk in chunks]
sources = [os.path.basename(self.file_path)] * len(chunks)
ids = list(range(len(chunks)))
# 生成向量嵌入(示例用随机向量,实际需用embedding_model生成)
embeddings = [np.random.rand(512).tolist() for _ in chunks]
# 插入数据
data = [
{"id": ids[i], "source": sources[i], "document": docs[i], "embedding": embeddings[i]}
for i in range(len(chunks))
]
self.client.insert(collection_name=self.collection_name, data=data)
self.client.flush(self.collection_name)
def _run(self, query: str) -> str:
"""执行搜索并返回结果"""
# 生成查询向量(实际需用embedding_model生成)
query_vector = np.random.rand(1, 512).tolist()
# 向量搜索
results = self.client.search(
collection_name=self.collection_name,
data=query_vector,
anns_field="embedding",
search_params={"metric_type": "L2", "params": {"nprobe": 10}},
limit=5,
output_fields=["document"]
)
# 格式化结果
docs = [res['entity']['document'] for res in results[0]] if results else []
return "\n___\n".join(docs) if docs else "未从PDF中找到相关信息"tools/ddgs_tools.py(网络搜索工具,基于 DuckDuckGo):
from crewai.tools import tool
from ddgs import DDGS
@tool("DDGS Text Search")
def ddgs_text_search(query: str, max_results: int = 5) -> str:
"""
使用DuckDuckGo进行网络文本搜索,当PDF检索无结果时使用。
Args:
query: 搜索关键词(如:高三一班张三 成绩)
max_results: 最大返回结果数(默认5)
Returns:
格式化的搜索结果字符串
"""
ddgs = DDGS()
try:
results = ddgs.text(
query=query,
max_results=max_results,
backend="auto",
region='zh-cn',
safesearch='moderate'
)
output = []
for i, res in enumerate(results, 1):
output.append(f"\n结果 {i}:")
output.append(f"标题: {res.get('title', 'N/A')}")
output.append(f"链接: {res.get('href', 'N/A')}")
output.append(f"摘要: {res.get('body', 'N/A')[:200]}...")
output.append("-" * 50)
return "\n".join(output) if output else "网络搜索未找到相关信息"
except Exception as e:
return f"搜索失败: {str(e)}"2. YAML 配置:定义智能体和任务
通过 YAML 文件分离配置与逻辑,后续修改角色或任务描述无需改动代码。
config/agents.yaml(智能体配置):
# 检索智能体:负责从PDF/网络获取成绩信息
retriever_agent:
role: >
成绩信息检索专家: {query}
goal: >
从可用资源中检索与用户查询{query}最相关的成绩信息,优先使用PDF搜索工具;
若PDF无结果,再使用网络搜索工具补充。
backstory: >
你是一位细致的教育数据分析师,擅长从文档和网络中精准提取学生成绩信息,
熟悉成绩单格式,能快速定位姓名、班级、分数等关键信息,确保检索结果准确无误。
# 响应合成智能体:整理结果为自然语言
response_synthesizer_agent:
role: >
成绩查询响应合成器: {query}
goal: >
根据检索到的成绩信息,为用户{query}提供简洁连贯的回答;
若未找到信息,统一回应“抱歉,我找不到该学生的成绩信息。”
backstory: >
你是一位耐心的客服专员,擅长将复杂的原始数据转化为通俗易懂的自然语言,
回答成绩查询时会明确包含姓名、班级、科目分数(若有),语气友好且专业。config/tasks.yaml(任务配置):
# 检索任务:分配给retriever_agent
retrieval_task:
description: >
从可用资源(优先PDF,其次网络)中检索与用户查询{query}最相关的成绩信息,
需提取关键信息:学生姓名、班级、科目分数(如有)、排名(如有)。
expected_output: >
文本形式的原始检索结果,包含来源(PDF/网络链接)和具体成绩信息;
若未找到,需注明“PDF无结果”和“网络无结果”。
agent: retriever_agent
# 响应合成任务:分配给response_synthesizer_agent
response_task:
description: >
基于检索到的原始信息,为用户查询{query}合成最终回答,要求:
1. 结构清晰:先说明是否找到信息,再分点列出成绩(若有);
2. 语言简洁:避免冗余,不超过300字;
3. 来源透明:注明信息来自PDF还是网络。
expected_output: >
自然语言回答,示例:
“已找到高三一班张三的成绩信息(来自PDF):
- 语文:120分
- 数学:135分
- 英语:118分
总分:373分,班级排名第5。”
若未找到:“抱歉,我找不到该学生的成绩信息。”
agent: response_synthesizer_agent3. 团队编排:通过 Crew 管理协作流程
crew.py(核心逻辑,组织智能体和任务):
import os
from crewai import Agent, Crew, Process, Task, LLM
from crewai.project import CrewBase, agent, crew, task
from crewai.agents.agent_builder.base_agent import BaseAgent
from typing import List
from tools.ddgs_tools import ddgs_text_search
from tools.custom_tool import DocumentSearchTool
# 初始化PDF工具(指定成绩单路径)
pdf_tool = DocumentSearchTool(file_path=r"../file/成绩单.pdf")
# 配置DeepSeek语言模型(需替换为自己的API密钥)
def deepseek_llm():
return LLM(
model="deepseek/deepseek-chat",
api_key="sk-23c834bcca994706a105abb54a77f22e", # 替换为真实API密钥
base_url="https://api.deepseek.com/v1",
model_kwargs={"llm_provider": "deepseek"}
)
@CrewBase
class GradeQueryCrew:
"""成绩查询多智能体团队"""
agents: List[BaseAgent]
tasks: List[Task]
# 加载YAML配置文件
agents_config = "../config/agents.yaml"
tasks_config = "../config/tasks.yaml"
# 定义检索智能体
@agent
def retriever_agent(self) -> Agent:
return Agent(
config=self.agents_config['retriever_agent'],
verbose=True, # 输出详细日志(便于调试)
tools=[pdf_tool, ddgs_text_search], # 绑定工具
llm=deepseek_llm()
)
# 定义响应合成智能体
@agent
def response_synthesizer_agent(self) -> Agent:
return Agent(
config=self.agents_config['response_synthesizer_agent'],
verbose=True,
llm=deepseek_llm()
)
# 定义检索任务
@task
def retrieval_task(self) -> Task:
return Task(
config=self.tasks_config['retrieval_task']
)
# 定义响应合成任务(依赖检索任务结果)
@task
def response_task(self) -> Task:
return Task(
config=self.tasks_config['response_task'],
context=[self.retrieval_task()], # 任务依赖:先执行检索再合成
output_file='成绩查询结果.md' # 结果保存到文件
)
# 定义团队协作流程
@crew
def crew(self) -> Crew:
return Crew(
agents=self.agents,
tasks=self.tasks,
process=Process.sequential, # 顺序执行:检索→合成
verbose=True # 输出团队协作日志
)4. 项目入口:启动多智能体系统
main.py(入口文件,接收用户查询并执行)
import warnings
from datetime import datetime
from crew import GradeQueryCrew
# 抑制无关警告
warnings.filterwarnings("ignore", category=SyntaxWarning, module="pysbd")
def run_grade_query():
"""启动成绩查询系统"""
# 接收用户输入(可替换为命令行参数或Web界面输入)
user_query = input("请输入查询内容(如:高三一班张三的成绩怎么样?):")
inputs = {
'query': user_query,
'current_year': str(datetime.now().year)
}
try:
# 启动团队并执行任务
print(f"\n=== 开始处理查询:{user_query} ===")
GradeQueryCrew().crew().kickoff(inputs=inputs)
print("\n=== 查询完成!结果已保存到「成绩查询结果.md」===")
except Exception as e:
raise Exception(f"执行出错:{e}")
if __name__ == "__main__":
run_grade_query()4.3 运行步骤
- 启动 Milvus 服务:确保本地 Milvus 服务已启动(参考Milvus 官方文档);
- 准备 PDF 文件:将成绩单 PDF 放入
file/目录,命名为 “成绩单.pdf”; - 执行代码:
cd src
python main.py- 输入查询:按提示输入查询(如 “高三一班张三的成绩怎么样?”),等待结果输出。

五、总结与进阶方向
本文通过 “成绩查询助手” 案例,带大家掌握了 CrewAI 的核心流程:工具封装→智能体 / 任务配置→团队编排→执行任务。从理论到实战,我们可以看到 CrewAI 的优势在于降低多智能体协作的开发门槛,让开发者无需关注复杂的流程调度,只需聚焦 “角色定义” 和 “任务拆分”。
更多推荐


 24
24 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)