
中国科学院信工所发布首篇LLM智能体幻觉综述!梳理5类幻觉、18大诱因与10种缓解方案,300+论文资源开源
不同于传统LLM仅在文本生成中出现的“语言错误”,LLM智能体的幻觉是跨模块、长链条的“复合偏差”:可能是规划行程时误解用户需求(推理幻觉),可能是调用工具时填充错误参数(执行幻觉),甚至可能在多智能体协作中传递虚假信息(通信幻觉),最终导致任务失败、设备故障,乃至现实世界的安全风险。其诱因包括“初始记忆有偏差”(如训练数据中的性别、国籍偏见)、“检索机制低效”(如仅按关键词匹配,忽略语义相关性)
当大语言模型驱动的智能体(LLM-based Agent)逐渐渗透进教育辅导、科学研究、金融分析等关键领域,成为实现通用人工智能(AGI)的核心载体时,一个致命问题正制约其落地——幻觉。不同于传统LLM仅在文本生成中出现的“语言错误”,LLM智能体的幻觉是跨模块、长链条的“复合偏差”:可能是规划行程时误解用户需求(推理幻觉),可能是调用工具时填充错误参数(执行幻觉),甚至可能在多智能体协作中传递虚假信息(通信幻觉),最终导致任务失败、设备故障,乃至现实世界的安全风险。
正是在这一背景下,来自中国科学院信息工程研究所、中国科学院自动化研究所、中国科学院数学与系统科学研究院、武汉大学、中国人民大学、麦考瑞大学、格里菲斯大学等机构的研究者,联合小米等企业团队,发布了首篇聚焦LLM智能体幻觉的全面综述——《LLM-based Agents Suffer from Hallucinations: A Survey of Taxonomy, Methods, and Directions》。这篇综述不仅首次厘清了智能体幻觉的本质,更提出全新分类框架、拆解18大触发原因、总结10种缓解策略,并开源300+相关研究论文库,为打造可靠、安全的智能体系统提供了关键参考。

-
论文链接:https://arxiv.org/pdf/2509.18970
-
Github:https://github.com/ASCII-LAB/Awesome-Agent-Hallucinations
打破认知:LLM智能体幻觉≠传统语言幻觉
在讨论智能体幻觉前,必须先明确一个核心区别:LLM智能体不是“会说话的模型”,而是“会决策、会行动的智能系统”。
传统LLM的幻觉多局限于文本生成,比如编造不存在的文献引用或事实错误;但LLM智能体拥有“大脑-感知-动作”三大核心模块:“大脑”负责记忆与推理,“感知”处理多模态环境输入,“动作”可调用工具(如日历API、智能家居指令)。这种复杂性使得智能体幻觉呈现出三大独特性:
-
类型更复杂:不是单一错误,而是模块交互产生的复合行为偏差,比如“感知错误→记忆存储→推理误用”的连锁问题;
-
传播链更长:幻觉可能出现在推理、执行、记忆等任一中间环节,随时间累积放大,而非仅存在于最终输出;
-
后果更严重:错误会转化为“物理可执行动作”,比如智能家居Agent误判环境亮度导致持续开灯,或金融Agent错误调用交易API造成损失。
为了精准刻画这一系统,综述用部分可观测马尔可夫决策过程(POMDP) 对智能体交互动力学进行形式化定义。在这一框架中,智能体基于自身信念(Belief),通过感知环境(Perception)、生成计划(Reasoning)、执行动作(Execution)、接收反馈(Feedback)、更新记忆(Memorization)来实现目标(如图1所示);而多智能体系统(MAS)还需额外处理消息广播(Broadcasting)与通信拓扑进化(Structure Evolution),这进一步增加了幻觉传播的风险。
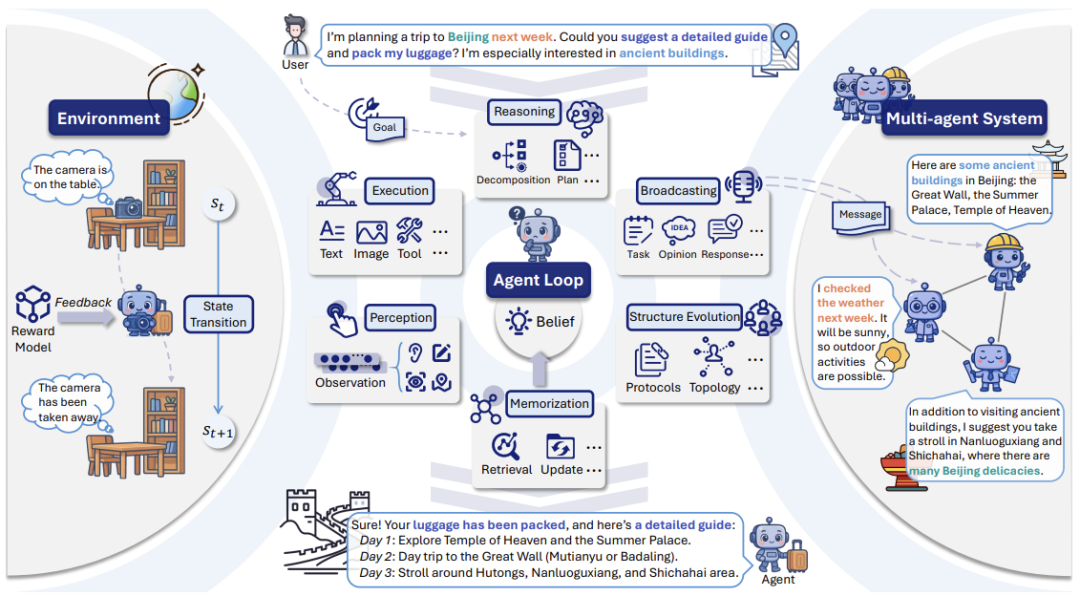
全新分类:5类幻觉覆盖智能体全流程,18大触发原因拆解“幻觉为什么会发生”
基于图1,综述提出了首个覆盖智能体全工作流的幻觉分类体系,将复杂的幻觉问题拆解为5种可定义、可分析的类型,每种类型都配有真实场景案例,让研究者与开发者能精准定位问题;仅分类还不够,综述的另一大贡献是系统性梳理了18个导致幻觉的核心触发原因,为后续缓解方案提供“靶点”,如图2所示。
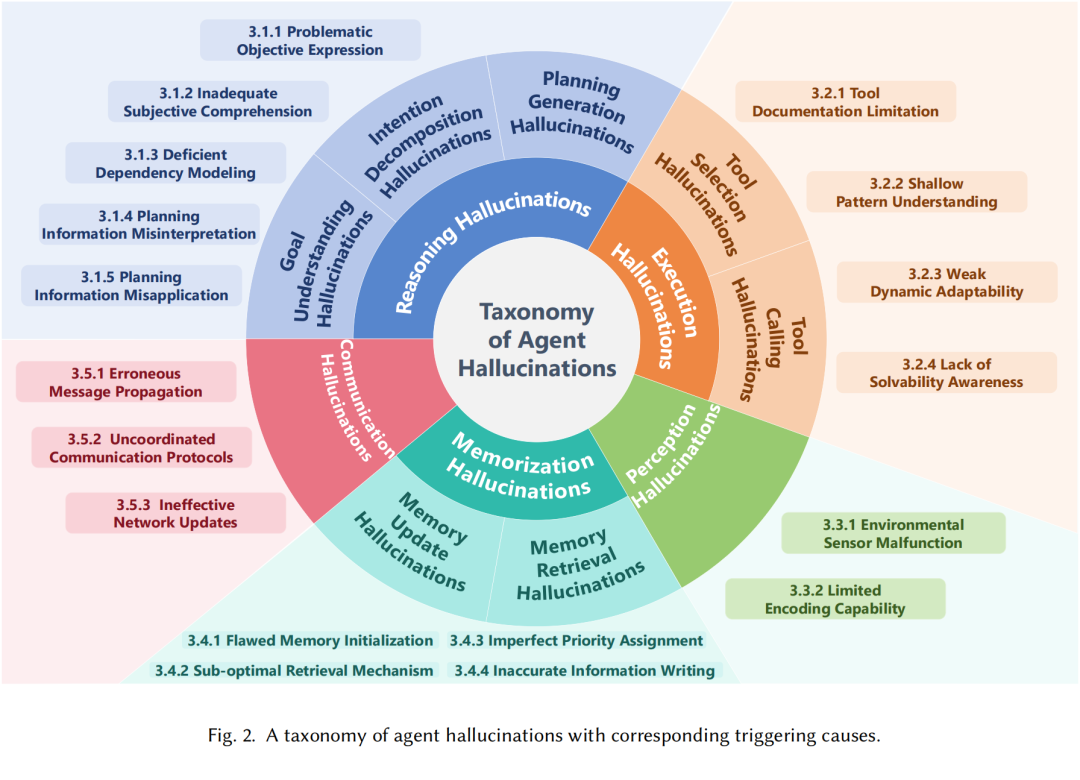
1. 推理幻觉:“想错了”
推理是智能体的“决策核心”,负责理解用户目标、分解子任务、生成执行计划。推理幻觉则是“看似合理,实则逻辑错误”的规划偏差,细分为三类:
-
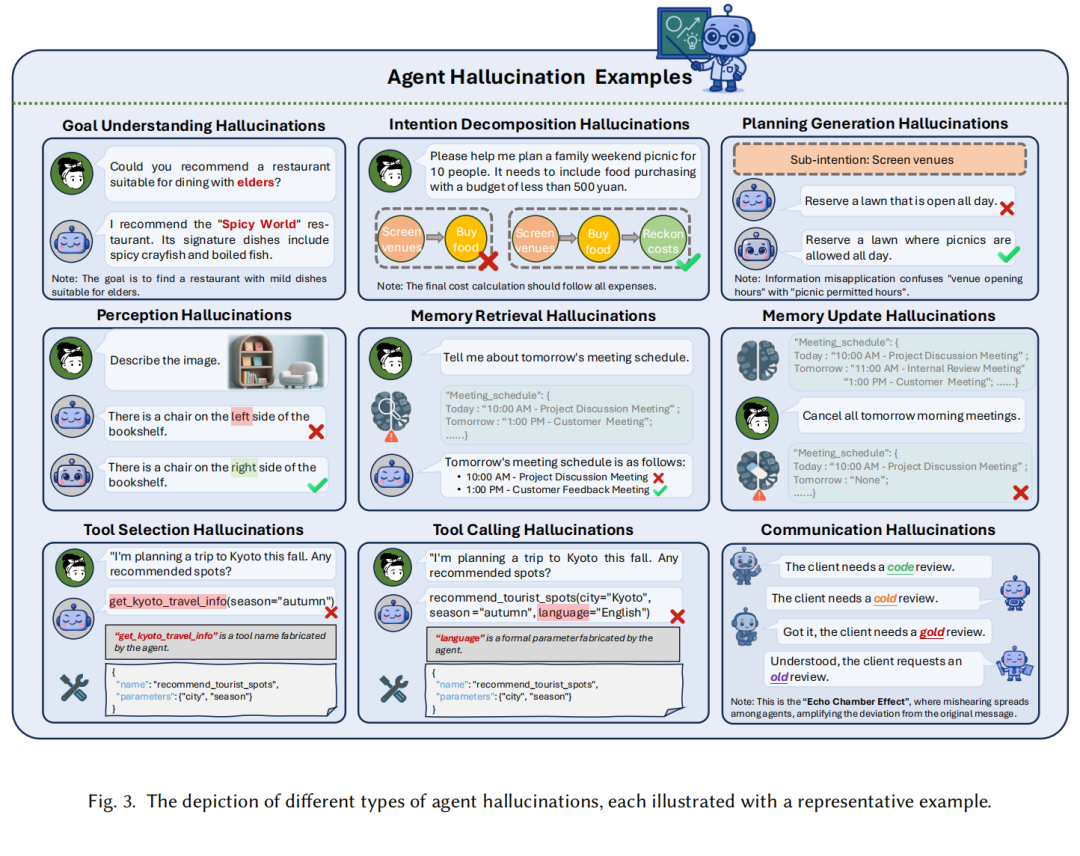
目标理解幻觉:误解用户意图,比如用户要求“推荐适合老人的餐厅”,Agent却推荐以辣菜为主的餐厅;
-
意图分解幻觉:子任务拆解错误,比如规划“10人家庭野餐(预算500元)”时,错误加入“全天草坪预订”等无关子目标;
-
计划生成幻觉:基于错误假设生成计划,比如忽略自身工具调用权限,规划“调用未授权的天气API获取数据”。
其根源多与“目标表达模糊”“长上下文误用”“子任务依赖建模不足”相关,比如用户指令语义模糊(如“周末短途游”未说明地点),或Agent处理长文本时过度依赖近期信息,忽略关键约束(如预算限制)。
2. 执行幻觉:“做错了”
执行阶段是智能体将“计划”转化为“动作”的关键环节,核心是工具选择与调用,幻觉主要表现为:
-
工具选择幻觉:自信选择不存在或无关的工具,比如用户查询北京旅行推荐,Agent调用虚构的“get_beijing_travel_info”工具;
-
工具调用幻觉:工具参数错误,比如调用“航班查询工具”时遗漏“出发日期”参数,或填充错误的机场代码。
综述指出,这两类幻觉的核心诱因是“工具认知偏差”:工具文档描述不完整(如API参数说明缺失)、Agent对工具使用模式理解过浅(如不知工具需嵌套调用),或无法适应工具功能更新(如API接口变更后仍用旧参数)。
3. 感知幻觉:“看错了”
感知模块是智能体的“感官”,负责将物理环境信号(如摄像头图像、麦克风声音)转化为内部可理解的观测值。感知幻觉则是“观测值与真实环境严重偏差”,主要源于:
-
传感器故障:如摄像头镜头畸变导致Agent误判“桌子上有杯子”(实际无),或惯性传感器漂移造成机器人导航偏差;
-
编码能力不足:单模态信息提取不全(如忽略图像中的局部细节),或跨模态融合失败(如文本描述“红色按钮”与图像中“蓝色按钮”无法对齐)。
这类幻觉是后续所有决策错误的“源头”——若环境输入本身失真,后续记忆与推理再精准也无意义。
4. 记忆幻觉:“记错了”
记忆模块是智能体的“知识库”,负责存储历史交互、环境信息与工具使用记录。记忆幻觉则是“默认记忆可靠,实则依赖错误信息”,分为两类:
-
记忆检索幻觉:提取无关或不存在的信息,比如用户询问“明天会议安排”,Agent从记忆中检索出“昨天的项目会议”作为答案;
-
记忆更新幻觉:错误修改或删除记忆,比如用户要求“取消明天上午会议”,Agent却误删全天所有会议记录。
其诱因包括“初始记忆有偏差”(如训练数据中的性别、国籍偏见)、“检索机制低效”(如仅按关键词匹配,忽略语义相关性),或“记忆优先级混乱”(重要信息被误删,冗余信息留存)。
5. 通信幻觉:“传错了”
在多智能体系统中,Agent需通过通信共享知识、协调任务,通信幻觉则是“看似在交流,实则传递错误信息”,主要表现为:
-
消息传播错误:Agent生成含事实错误的消息,如“客户需要代码审查”被传为“客户需要冷启动审查”;
-
协议不协调:通信格式或时序混乱,比如部分Agent用JSON格式发消息,部分用自然语言,导致信息无法解析;
-
网络更新无效:通信拓扑未及时调整,比如将财务数据发送给无权限的Agent,或关键消息未传递到负责执行的节点。
这类幻觉的典型案例是“回声室效应”——多Agent间反复传递同一错误信息,最终集体偏离原始目标。
系统解法:3大方向10种缓解策略+检测进展
针对上述问题,综述从近年研究中提炼出三大类共10种幻觉缓解方法,如图4所示;同时,也客观指出了当前检测研究的现状——感知幻觉检测方法较多,记忆与通信幻觉检测仍待突破。
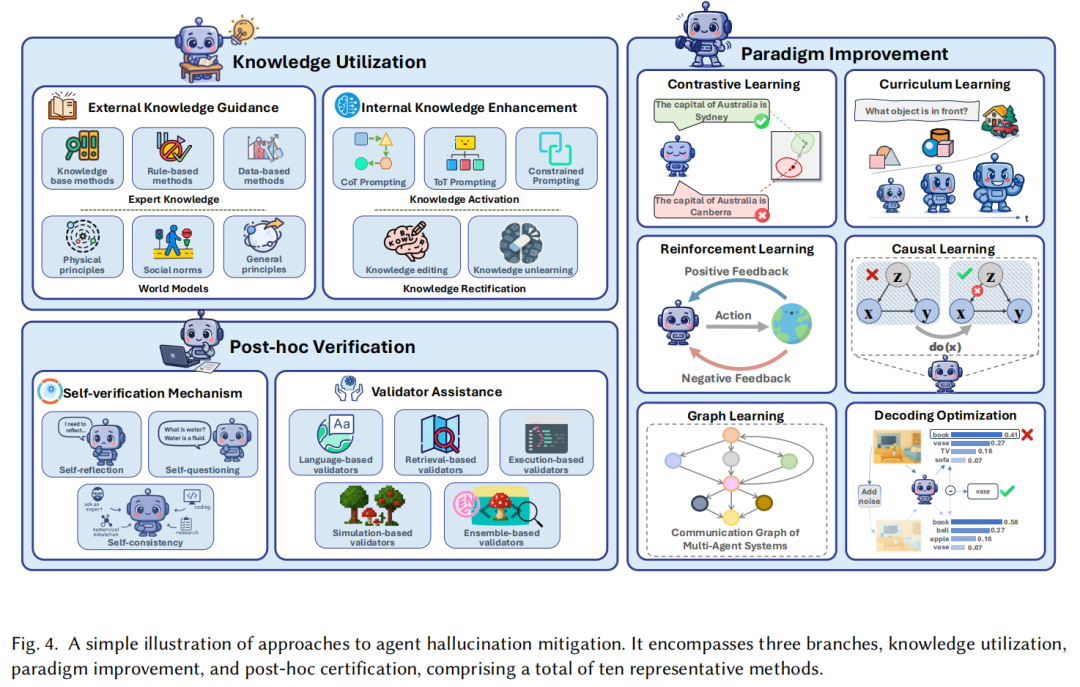
1. 知识利用:用“可靠知识”减少偏差
核心思路是为Agent提供精准、实时的知识支撑,弥补内部知识缺口:
-
外部知识指导:引入专家知识(如领域规则、知识库)或世界模型(如物理定律、常识),比如用“烹饪前需清洗食材”的常识约束Agent行为;
-
内部知识增强:通过提示工程(如思维链CoT、树状思维ToT)激活Agent已有知识,或通过“知识编辑”修正错误记忆(如替换过时的工具参数信息)。
2. 范式改进:用“更好的学习方法”提升鲁棒性
从训练与推理范式入手,增强Agent抵抗幻觉的能力,包括6种关键方法:
-
对比学习:让Agent学会区分“正确/错误”模式,减少相似任务的混淆;
-
课程学习:从简单任务(如单工具调用)逐步过渡到复杂任务(如多工具嵌套调用),积累可靠经验;
-
强化学习:通过“试错-反馈”优化策略,比如用“代码单元测试通过率”作为奖励信号,提升编程Agent的准确性;
-
因果学习:建模任务中的因果关系,避免“相关性误判为因果”的推理错误;
-
图学习:用图结构组织工具、记忆或多Agent通信拓扑,提升信息管理的有序性;
-
解码优化:推理时调整输出概率分布,比如“对比解码”选择更符合事实的候选结果。
3. 事后验证:“做完再检查”,阻止幻觉传播
在任务执行的每一步后加入验证环节,避免幻觉累积,主要分为两类:
-
自我验证:Agent通过“自我反思”(如重新检查推理步骤)、“自我一致性”(生成多个结果后投票)等方式自查错误;
-
验证器辅助:引入外部系统验证,比如用“检索验证器”查外部事实、“执行验证器”运行代码测试正确性,或“模拟验证器”在沙盒环境中预演动作。
在此基础上,综述还贴心地通过表格清晰标注了每种方法对5类幻觉的适用场景,如表1所示:
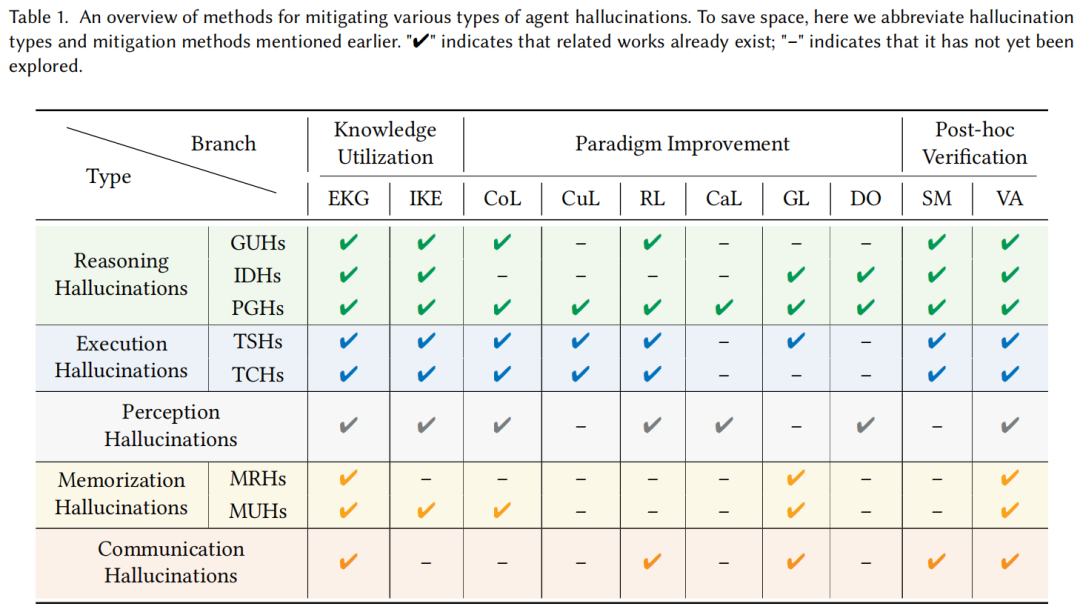
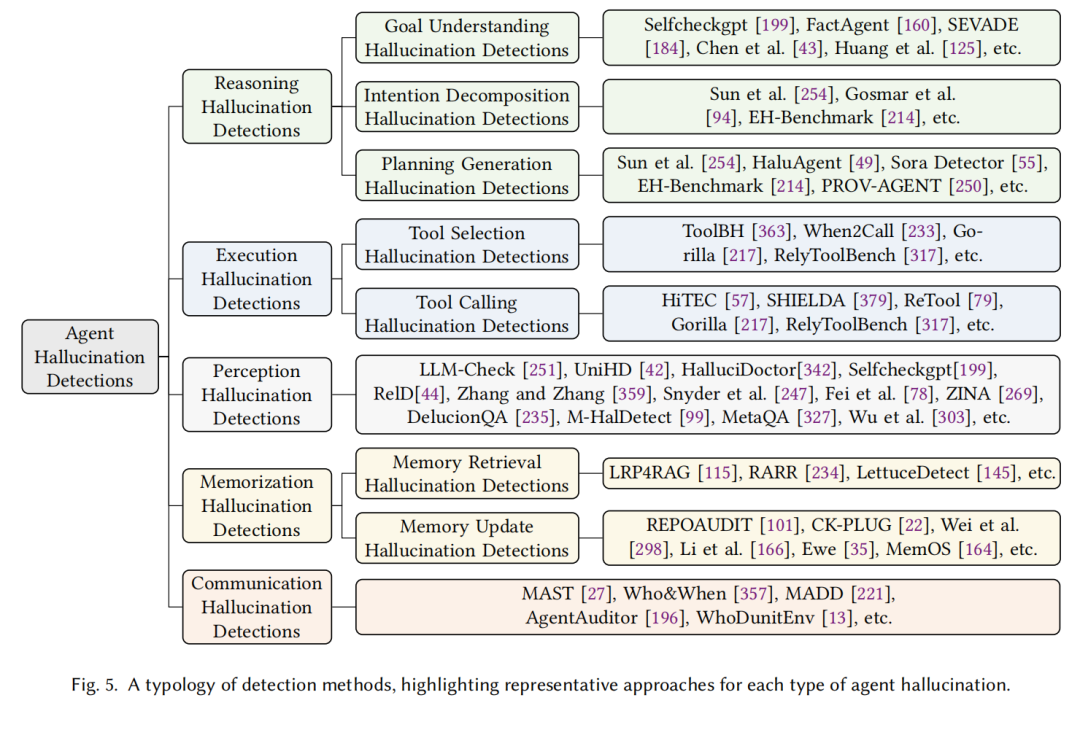
而在检测方面,综述梳理了当前代表性方法(如图5所示):例如用SelfCheckGPT检测推理幻觉,用ToolBH评估工具调用幻觉,用LRP4RAG定位记忆检索幻觉等。但现状是,感知幻觉因“输入-输出偏差易观测”(如图像与文本描述不匹配)而研究较多,记忆与通信幻觉因“隐蔽在内部模块”而检测方法稀缺,这是未来的重点方向之一。
开源资源+未来方向:为可靠智能体铺路
为了推动领域协作,综述团队还打造了首个LLM智能体幻觉研究资源库,在GitHub(https://github.com/ASCII-LAB/Awesome-Agent-Hallucinations)上开源了300+相关论文,涵盖幻觉分类、缓解、检测等所有方向。同时,基于对现有研究的复盘,综述提出了6个亟待突破的未来方向,直指智能体幻觉研究的核心痛点:
-
幻觉累积研究:当前多关注单步幻觉,需分析“多步累积效应”,比如“初始感知误差如何在10轮交互后导致严重决策错误”;
-
精确幻觉定位:需设计可追溯的执行轨迹模型,比如在每个模块加入“轻量级检查点”,快速定位幻觉源头;
-
机制可解释性:用“神经机制解释(MI)”揭示幻觉的内部成因,比如Transformer的哪些层负责工具调用决策,为何会出现参数错误;
-
统一基准构建:现有基准多针对单一幻觉类型(如ToolBH仅测执行幻觉),需建立覆盖“推理-执行-记忆-通信”的综合评估体系;
-
持续自进化能力:让Agent能动态适应环境与需求变化,比如通过终身学习更新知识,避免“旧知识导致的幻觉”;
-
基础架构升级:突破Transformer的长上下文瓶颈,探索“神经符号系统”等新架构,提升推理与记忆的可靠性。
总结:从“能做事”到“可靠做事”的关键一步
LLM智能体的发展正从“追求功能全面”转向“追求安全可靠”,而幻觉问题是这一转型路上必须跨越的障碍。这篇综述的价值,不仅在于“系统性梳理现有研究”,更在于“为领域建立了统一的问题定义与分析框架”——它让原本模糊的“幻觉问题”变得可分类、可溯源、可解决。
对于研究者,这份综述是入门的“地图”,清晰标注了每个方向的研究现状与缺口;对于开发者,它是排查问题的“手册”,可按5类幻觉快速定位产品中的风险点;而对于整个领域,它标志着LLM智能体研究从“零散探索”进入“系统攻坚”阶段。
正如综述结尾所言:“解决智能体幻觉不是‘优化细节’,而是构建可靠AGI的基础。” 随着更多研究者基于这份框架开展工作,我们离“能自主决策、且让人放心”的智能体系统,无疑又近了一步。


更多推荐


 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)