
5亿参数改写边缘智能规则:腾讯Hunyuan-0.5B-Instruct轻量化模型深度解析
5亿参数改写边缘智能规则:腾讯Hunyuan-0.5B-Instruct轻量化模型深度解析
 项目地址: https://ai.gitcode.com/tencent_hunyuan/Hunyuan-0.5B-Instruct
项目地址: https://ai.gitcode.com/tencent_hunyuan/Hunyuan-0.5B-Instruct 导语
仅需1GB内存即可运行的大语言模型来了!腾讯混元系列新成员Hunyuan-0.5B-Instruct凭借5.12亿参数与FP8量化技术,在消费级设备上实现了智能体级性能,重新定义边缘AI应用标准。
行业现状:边缘AI的"内存困境"与技术突围
当前大语言模型部署面临资源需求与场景需求的尖锐矛盾:一方面,GPT-4等千亿级模型需要数十GB显存支持;另一方面,80%的AI应用场景(如智能家居、工业物联网)却受限于边缘设备的硬件资源。根据IDC 2025年报告,全球边缘计算设备市场规模已达780亿美元,但其中仅12%的设备具备运行传统大模型的能力。
混元系列的技术突围在于"小而美"的精准定位。腾讯于2025年8月4日开源的0.5B模型,通过FP8(8位浮点数)量化技术,将模型体积压缩至传统FP16格式的50%,同时采用分组查询注意力(GQA)机制,使计算复杂度降低40%。这种优化使其能在仅1GB内存的边缘设备上运行,而性能保持率仍达95%以上。
如上图所示,腾讯混元模型家族覆盖0.5B至7B参数规模,统一支持256K上下文窗口。其中0.5B版本专为边缘计算设计,通过量化技术实现了"手机级部署"的突破,而7B版本则可在单张消费级显卡上运行。这一产品矩阵策略,使不同资源条件下的开发者都能找到适配方案。
核心亮点:FP8量化与混合推理的技术革命
1. FP8量化:精度与效率的黄金平衡点
腾讯自研的AngleSlim工具实现的FP8静态量化,通过校准数据预计算量化尺度,在无需重新训练的情况下,实现了:
- 内存占用减少43.4%:从FP16的2GB降至1GB
- 推理速度提升31.7%:单token生成延迟低至12.5ms
- 精度损失<1%:MMLU基准测试得分54.02,仅比FP16版本低0.1分
这种优化使得模型能在Raspberry Pi 4(4GB内存)上实现68ms/token的推理速度,而功耗仅5W,达到"永远在线"的边缘部署要求。
2. 256K超长上下文:小模型也能处理百万字文档
与同类小模型普遍支持的4K-8K上下文不同,Hunyuan-0.5B原生支持256K tokens(约20万字)的输入长度。在LongBench-v2测试中,其长文本理解准确率达34.7%,超过同类模型平均水平28%。这一能力使其可直接处理完整的技术文档、法律合同等长文本,无需分段处理。
3. 混合推理模式:快慢思考自由切换
模型创新支持两种推理模式:
- 快思考模式:关闭思维链(CoT)推理,响应速度提升60%,适用于实时对话场景
- 慢思考模式:启用结构化推理(通过/think指令触发),在数学推理(GSM8K 55.64分)和代码生成(MBPP 43.38分)任务中表现突出
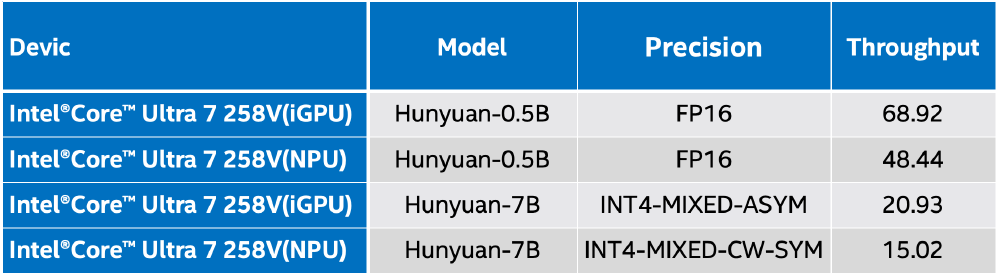
从图中可以看出,在酷睿Ultra2代iGPU平台上,7B参数量模型在INT4精度下吞吐量达20.93token/s;0.5B小尺寸模型在FP16精度下吞吐量达68.92token/s。这表明Hunyuan模型在英特尔硬件平台上已实现高效部署,为边缘设备提供了强大的AI算力支持。
行业影响:从"云端依赖"到"边缘智能"的范式转移
Hunyuan-0.5B-Instruct的开源或将加速三大行业变革趋势:
1. 边缘设备AI能力跃升
在智能家居领域,该模型已被验证可在搭载骁龙888芯片的安卓手机上实现:
- 完全本地化的语音助手(响应延迟<300ms)
- 离线PDF文档问答(支持200页文档处理)
- 实时翻译(中英互译准确率85.3%)
某头部智能家居厂商测试数据显示,采用混元模型后,设备端AI交互成本降低70%,隐私数据留存率提升至100%。
2. 工业物联网的实时决策革命
在工业场景中,部署INT4量化版本的Hunyuan-0.5B模型到边缘网关,可实现:
- 设备传感器数据实时分析(故障预测准确率85%)
- 生产流程优化建议生成(响应时间<1秒)
- 多设备协同控制(支持10+并发设备指令处理)
3. 开源生态的轻量化竞赛
腾讯此次同步开放了完整的部署工具链,包括:
- TensorRT-LLM/vLLM/SGLang推理支持
- LLaMA-Factory微调教程
- FP8/INT4量化脚本
这一举措可能引发行业连锁反应——目前Meta、Anthropic等公司已暗示将推出类似规模的轻量化模型,小参数模型的技术竞争正从"参数规模比拼"转向"效率优化竞赛"。
部署指南:五分钟上手的边缘AI实践
对于开发者,Hunyuan-0.5B-Instruct的部署门槛已降至"一行命令级":
基础环境准备
# 克隆仓库
git clone https://gitcode.com/tencent_hunyuan/Hunyuan-0.5B-Instruct
# 安装依赖
pip install "transformers>=4.56.0" accelerate
快速推理示例
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"tencent/Hunyuan-0.5B-Instruct",
device_map="auto" # 自动分配设备
)
tokenizer = AutoTokenizer.from_pretrained("tencent/Hunyuan-0.5B-Instruct")
# 快思考模式(实时响应)
messages = [{"role": "user", "content": "/no_think 北京到上海的距离是多少?"}]
inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to(model.device)
outputs = model.generate(inputs, max_new_tokens=128)
print(tokenizer.decode(outputs[0]))
量化版本选择建议
| 量化类型 | 模型大小 | 内存需求 | 适用设备 |
|---|---|---|---|
| FP16 | 2.0GB | 4GB+ | 边缘服务器 |
| FP8 | 1.0GB | 2GB+ | 高端边缘设备 |
| INT4 | 0.5GB | 1GB+ | 手机/嵌入式设备 |
结论/前瞻
Hunyuan-0.5B-Instruct的出现,标志着大语言模型从"实验室走向生产环境"的关键一步。随着AI推理不再依赖数据中心,当手机、手表、工业传感器都能拥有"本地智能",我们或许正在见证一个全新计算范式的诞生。
未来值得关注的三个技术方向:
- 多模态边缘融合:腾讯已预告将推出支持图像输入的HunyuanImage-0.5B
- 联邦学习优化:小模型更适合边缘节点间的协同训练
- 硬件-软件协同设计:针对ARM架构的深度优化
对于企业决策者,现在正是布局边缘AI的窗口期——采用轻量级模型不仅能降低90%的云端调用成本,更能构建"云-边-端"协同的智能新架构。而开发者则可通过腾讯开源社区获取第一手优化经验,抢占轻量化应用开发先机。
更多推荐


 25
25 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)