
语音类AI应用术语
1. TTS - 文本转语音
Text-to-Speech,文本转语音。一种将书面文字转换成人工语音的技术,核心是让机器“读出”文本。
应用场景:
-
语音助手:如 Siri、小爱同学的回答。
-
有声读物/新闻:将文章自动转化为语音。
-
无障碍技术:为视障人士朗读屏幕内容。
-
导航系统:播报路线指引。
发展水平:早期的TTS声音机械、不自然。现在基于深度学习的神经TTS 已经可以生成非常逼真、富有情感的人类语音。
2.ASR- 自动语音识别
Automatic Speech Recognition,自动语音识别。一种将人类语音自动、准确地转换为文本的技术,让机器“听懂”人话。
核心技术:声学特征提取(如MFCC)、声学模型(如TDNN、Transformer)、语言模型及解码器
应用场景:
-
语音输入法:在手机上用语音代替打字。
-
实时字幕:为视频会议或直播生成字幕。
-
语音助手:识别用户的语音指令。
-
语音转录:将会议录音、采访录音转成文字稿。
发展水平:在安静环境和标准口音下准确率已非常高,但在嘈杂环境或处理方言、专业术语时仍有挑战。
3. NLP - 自然语言处理
Natural Language Processing,自然语言处理。人工智能的一个子领域,关注计算机与人类(自然)语言之间的交互,尤其是如何让计算机处理、理解和生成人类语言。LLM(大语言模型)是其子集。
研究内容:
-
理解层面:词性标注、句法分析、语义分析、情感分析、机器阅读理解等。
-
生成层面:文本摘要、机器翻译、对话生成等。
应用场景:搜索引擎、垃圾邮件过滤、智能客服、机器翻译、情感分析等。ASR和TTS可以看作是NLP与语音信号处理的交叉领域,负责语言与语音的转换,而NLP更侧重于语言本身的理解和生成。
4. LLM - 大语言模型
Large Language Model,大语言模型。基于海量文本数据训练的、拥有巨大参数规模(通常是数十亿甚至万亿以上)的深度学习模型,理解和生成人类语言,并能够完成各种复杂的语言任务。它是当前NLP领域最前沿的技术
特点:
-
通用性:一个模型可以通过“提示”完成翻译、写作、编程、问答等众多任务,而无需为每个任务专门训练。
-
涌现能力:当模型规模达到一定程度时,会表现出在小模型中不具备的能力,如逻辑推理、链式思考等。
著名例子:ChatGPT(背后的GPT系列)、文心一言、通义千问、LLaMA等。
与NLP的关系:LLM是推动NLP领域取得革命性进展的核心技术。传统的NLP方法多为针对特定任务的小模型,而LLM是一种通用的基础模型。
5. VAD - 语音活动检测
Voice Activity Detection,语音活动检测,也叫端点检测。一种用于检测音频信号中是否存在人语音的技术,区分“有语音”和“无语音”(静音或噪声)的片段。
应用场景:
-
ASR的前置步骤:在识别前,先找出哪段时间有人说话,避免对静音部分进行无效识别,提升效率和准确率。
-
语音通信:在电话或视频会议中,只在检测到语音时才传输数据,可以节省带宽。
-
唤醒词检测:在智能音箱中,持续监听环境音,但只有检测到类似“小爱同学”的语音模式时才被正式激活。
技术协同关系
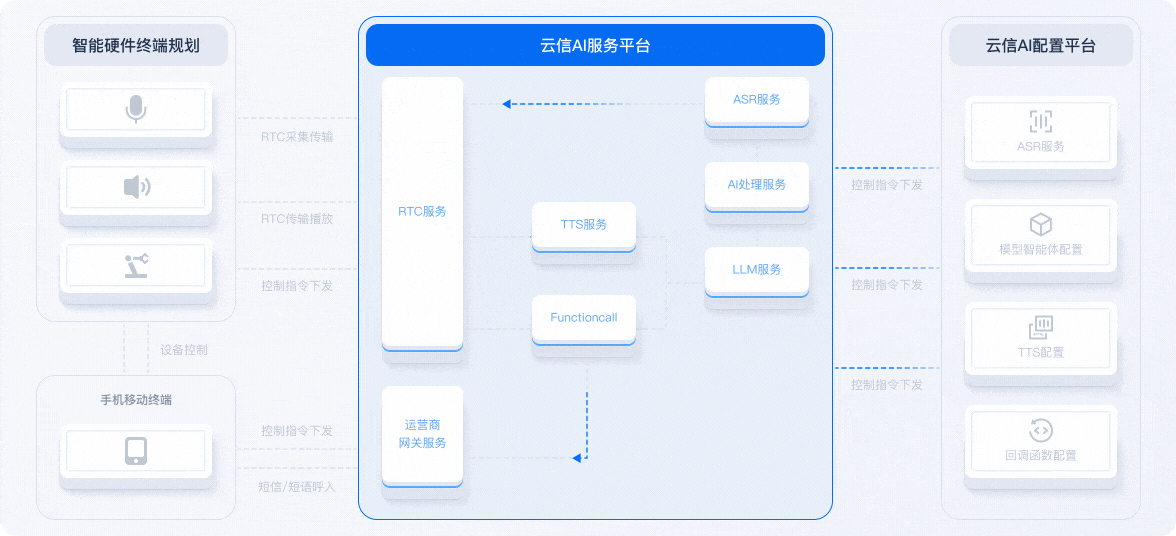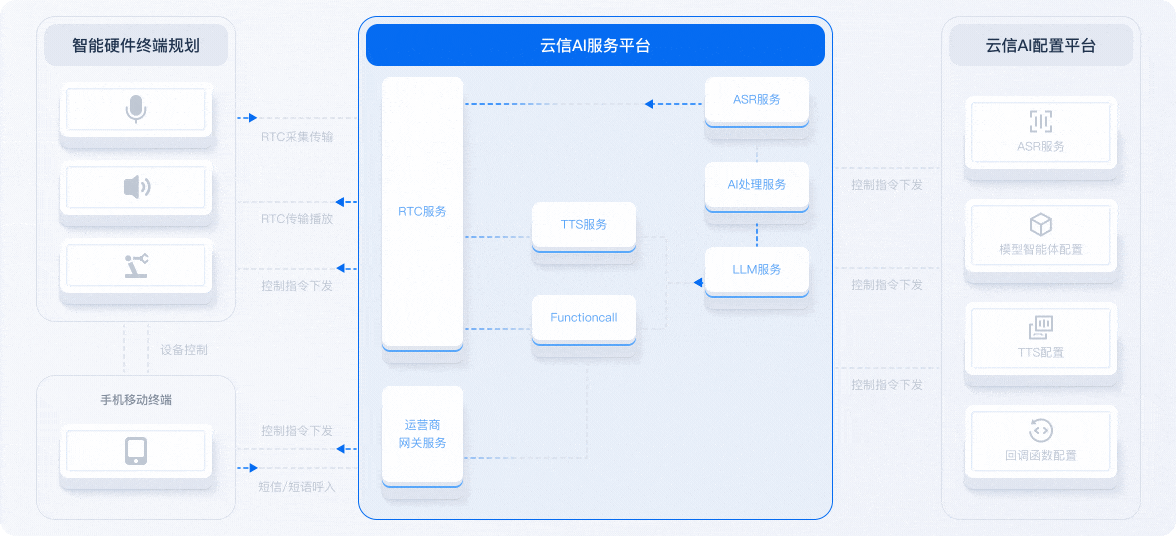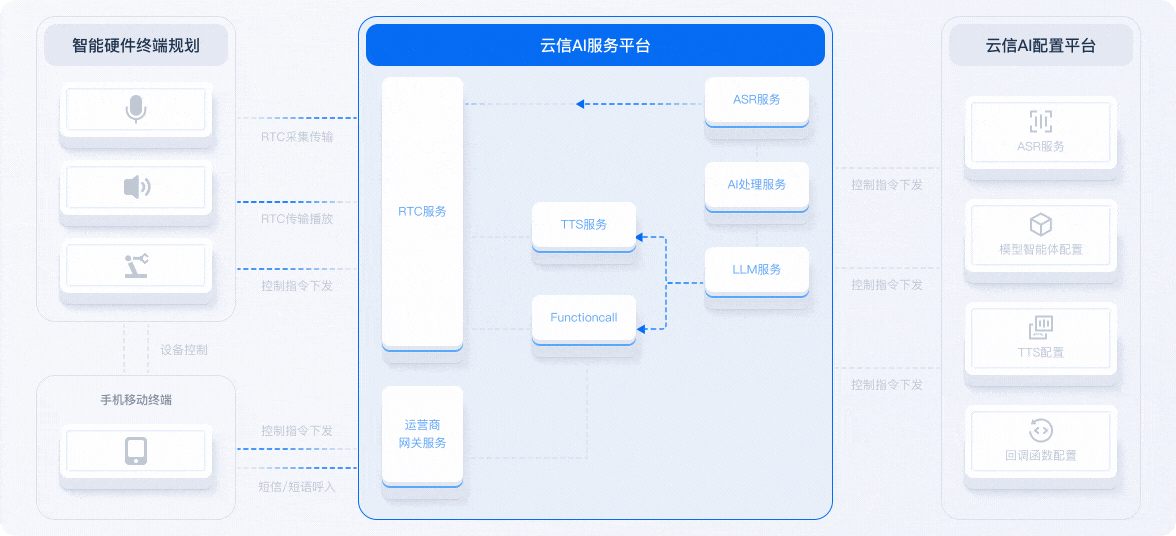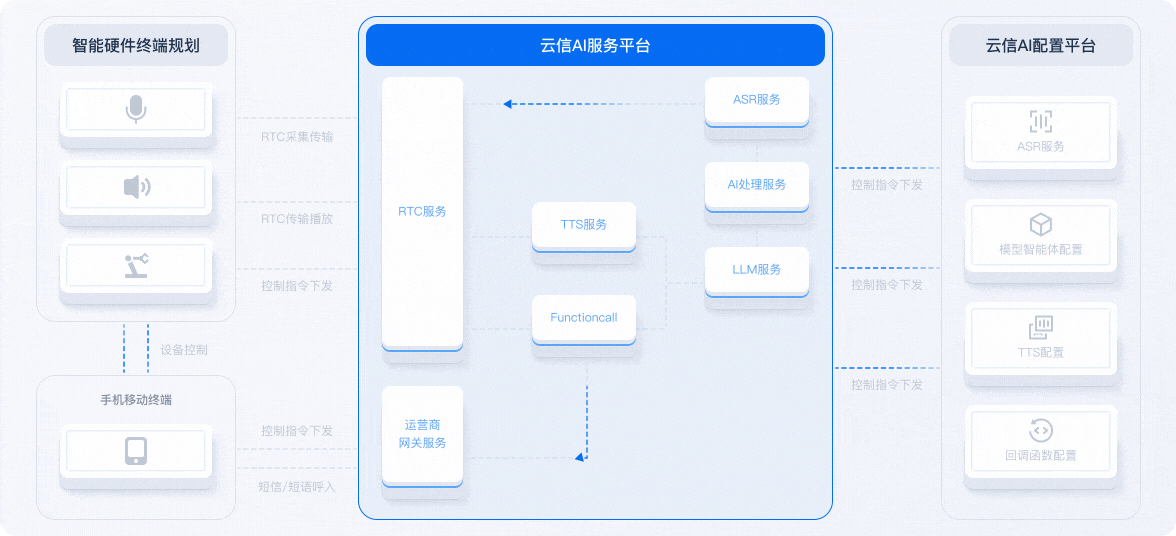
在语音交互系统中,四者协同工作:
- ASR 将语音转为文本;
- NLP/LLM 处理文本并生成回复;
- TTS 将回复文本转为语音输出
借用网易云信技术架构图说明
更多推荐


 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)