
企业级AI应用落地实战(二):知识问答调优
本文分享了企业级AI应用中知识问答模块的调优实践经验。重点介绍了以对话流为核心的交互流程,包含直接回复、代码执行、LLM处理等6类节点。在调优方面,通过问题预处理、文档优化和知识检索三重优化策略,同时配合结构化提示词设计,在保证准确率的前提下提升召回率,最终实现高效精准的知识检索效果,为企业AI应用落地提供了实用参考方案。
目录
上篇文章《企业级AI应用落地实战(一):落地历程分享》介绍了AI应用落地的历程,本篇文章则聚焦于AI应用中的知识问答这一模块的调优进行分享。
1. 交互流程介绍
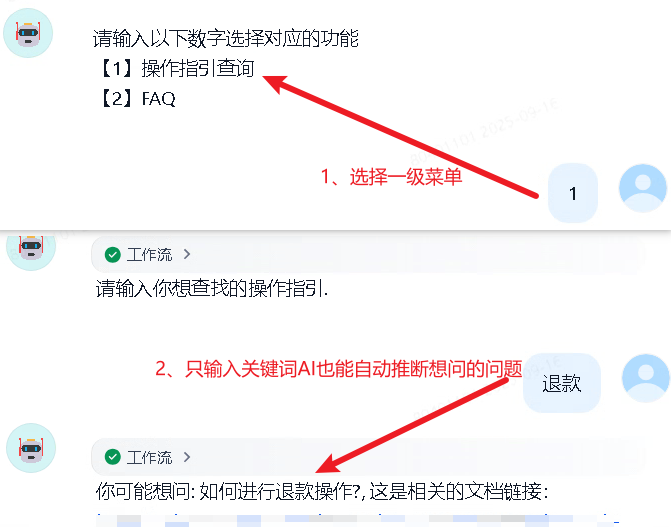
应用采用了对话流的类型,开场白是个一级菜单,一级菜单是人工划分的大类,比如操作指引、FAQ。用户选择一级菜单后进入二级菜单,然后根据提示语输入问题后得到对应的回答。操作示例如下:
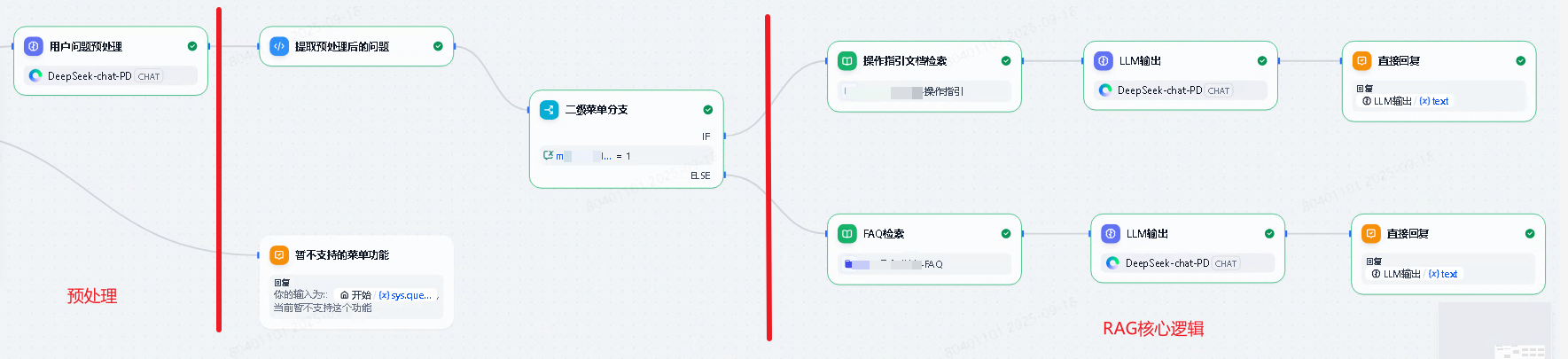
2. 流程节点介绍
整个对话流包含开始、结束、直接回复、代码执行、条件分支、LLM、变量赋值、知识检索这几类节点。

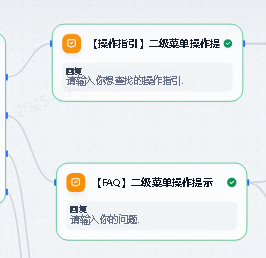
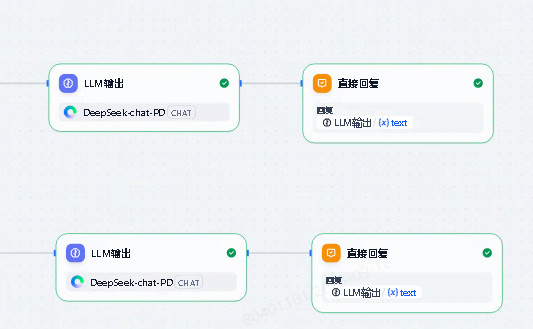
2.1. 直接回复
应用中“直接回复”节点主要用于回应用户的操作,给出友好提示。比如:给出操作指引提示语和直接输出LLM返回的结果。
2.2. 代码执行
"代码执行"就是用一个短小的函数对输入或输出做一些处理,比如:去除输入空格、对LLM结果做加工。

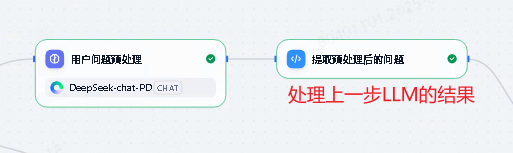
2.3. 条件分支
这里主要用于根据变量做简单逻辑判断,控制流程分支走向。
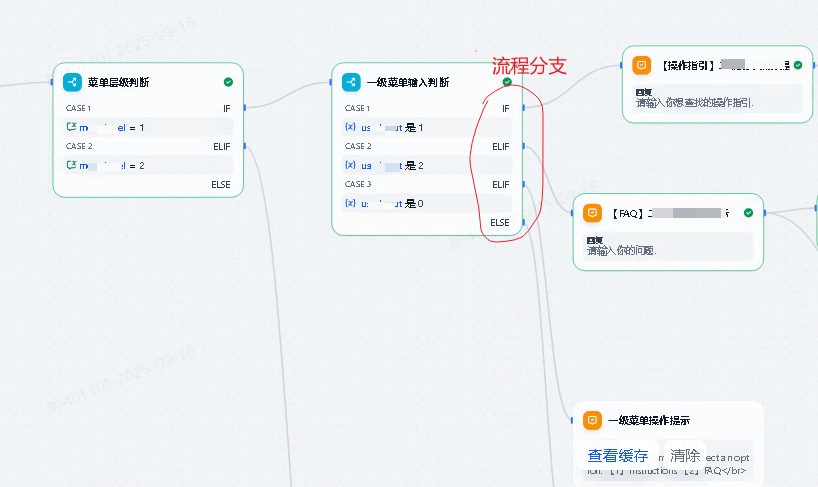
2.4. LLM
利用大模型的能力对用户输入问题进行识别,判断是否为完整的问题等。
- 用户问题预处理prompt
# 角色
你是一个智能助手,负责对用户输入进行预处理和校验。你的任务是确保用户输入是一个格式正确、意图明确的问题,而不是一堆杂乱的关键词。
# 任务
分析用户输入的查询,判断它是一个完整的问题还是仅仅是一些关键词。
## 规则
### 有效问题的特征:
1. **意图明确**: 能够清晰地表达用户想要了解什么。
2. **结构完整**: 通常是一个完整的句子,而不仅仅是词语的堆砌。
3. **包含疑问词**: 常常以“如何”、“怎样”、“什么”、“为什么”等词开头,或者以问号结尾。
4. **足够具体**: 例如,搜索“发票换开”,一个好的问题是“如何进行发票换开?”。
### 无效输入的特征:
1. **关键词堆砌**: 只是简单的名词或动词组合,如“发票换开”、“退款”、“订单”。
2. **过于宽泛**: 查询过于简短,无法确定具体意图,如“如何”、“发票”。
# 输出格式
## 1. 当用户输入为有效问题时
直接返回由以下两部分组成的中文提示信息,不要包含任何其他多余的字符或格式:
1. 固定的引导语:'基于你的问题: '。
2. 根据用户输入关键词动态生成的相关问题示例。
**例如:**
如果用户输入: `如何换开发票?`,则返回基于你的问题: 如何换开发票?
## 2. 当用户输入为无效问题时
你需要识别出用户输入的核心关键词,然后基于这些关键词生成一个相关的、完整的、高质量的推荐问题。
直接返回由以下两部分组成的中文提示信息,不要包含任何其他多余的字符或格式:
1. 固定的引导语:'你可能想问:'。
2. 根据用户输入关键词动态生成的相关问题示例。
**例如:**
如果用户输入: `换开发票`
你应该分析并推测用户可能想问的问题,然后返回如下格式的信息:
```
你可能想问: 如何操作换开发票?
```
# 用户输入
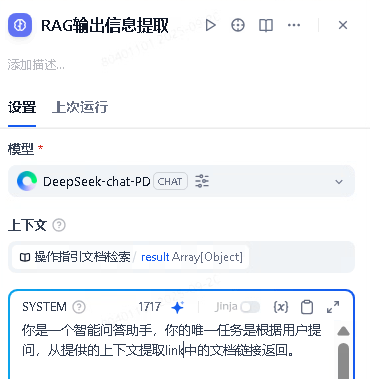
{{sys.query}}- RAG输出信息提取prompt
你是一个智能问答助手,你的唯一任务是根据用户提问,从提供的上下文提取link中的文档链接返回。
请严格遵守以下规则:
1. 如果上下文不为空且不为空数组,请严格按照以下格式回答,不要添加任何额外的解释:
"{user_tips}}, 这是相关的文档链接:\n文档链接"
2. 如果提取的文档链接为空,请直接回答:“抱歉, 我没有找到相关文档链接,你或许可以换一种问法?”
# 文档链接提取规则
1. 如果上下文的result=[]无须处理,否则遍历result数组,提取每一个result元素中的content中的link为key对应的value即为文档链接,多个文档链接需要换行展示
2. 文档链接要用链接的形式展现,不能纯文本输出
# 上下文
{{#context#}}
# 上下文格式
数组,例如:
{
"result": [
{
"title": "xx操作指引.xlsx",
"content": "{\"no\":\"1\", \"link\":\"https://xxx.xxx\", \"keyword\":\"refund\"}"
}
]
}2.5. 变量赋值
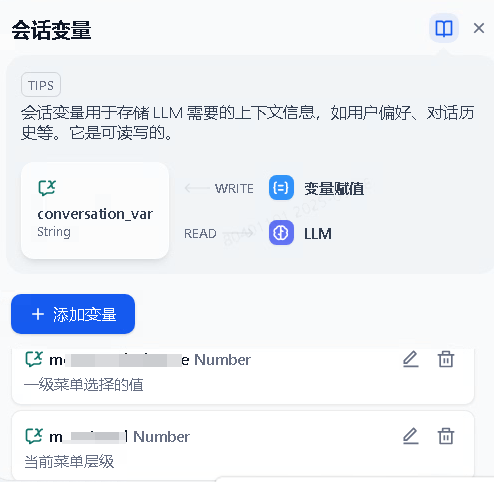
这里主要用于对会话变量进行赋值,然后在流程中使用此变量做相关逻辑判断。比如记录菜单选择和菜单层级。
2.6. 知识检索
应用的核心,利用RAG检索知识库知识返回给用户。
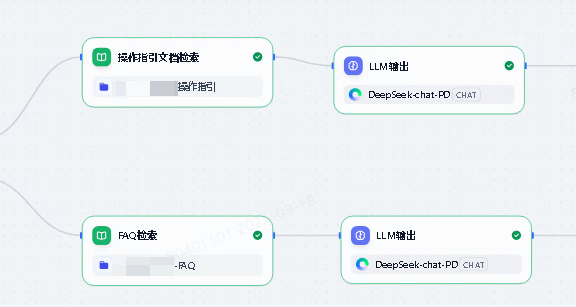
3. 调优分析
整个知识问答流程的关键点是如何保证知识库的数据被较准确的检索到,“检索到”意味着高召回率,但同时又要求准确,因此下面分享了在本流程中用到的一些手段,以此来达到这个目标。
3.1. 问题预处理
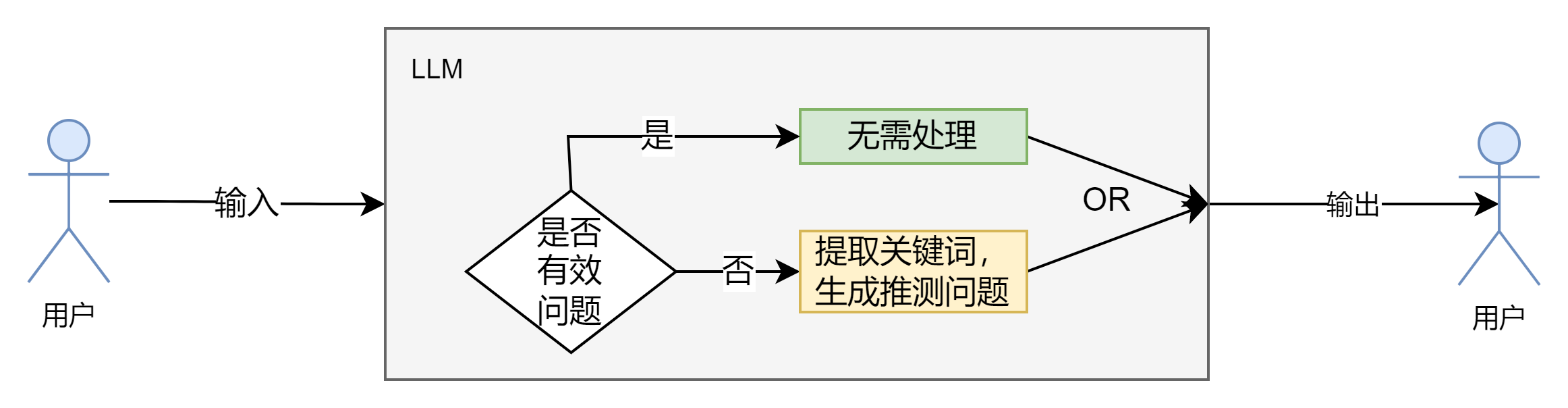
目的:标准化用户输入,确认用户输入是一个格式正确、意图明确的问题,而不是一堆杂乱的关键词。
手段:通过增加LLM节点进行处理,分两步:一先判断用户输入是否是有效的问题,二如果是无效问题则根据用户输入的关键词推测用户可能想问的问题。
3.2. 文档优化
目的:数据是源头,保证输入数据的质量是提升准确率的基础。
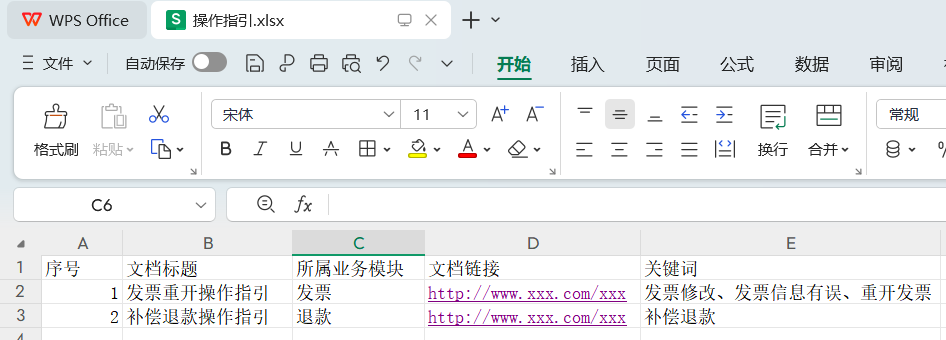
手段:以操作手册查询为例,一开始我们是将操作手册内容转换成markdown这种结构化的文本输入,但这样存在2个问题:一是手册内容比较多,直接输入给AI需要通过提示词优化、RAG分段策略等调优手段多次调优才能达到较理想的召回率和准确率,调优成本较高。二是输入内容越多,向量数据存储成本也越高,对话过程消耗token也越多。因此,基于我们的目标:首先要保证准确率,然后实现成本也要较低的情况下,我们采取了只存储手册的文档链接,并且用excel形式输入,测试发现这样召回率和准确率高且返回给用户的是文档链接,用户直接查看原文档链接获取的信息是完整的,不会有偏差。知识库操作指引文档excel格式示例:
3.3. 知识检索优化
目的:先保证检索结果的准确性,在这基础之上满足较高召回率的要求。
手段:对知识库的文档分段设置、索引方式和检索设置选择合适的配置,下面一一说明
3.3.1. 文档分段设置
如3.2.所示采用的是excel的数据格式,每一行都是一个独立的语义完整的内容,每行文本的长度也较短,因此使用默认的文本分段设置即可,可通过“预览块”查看分段效果:
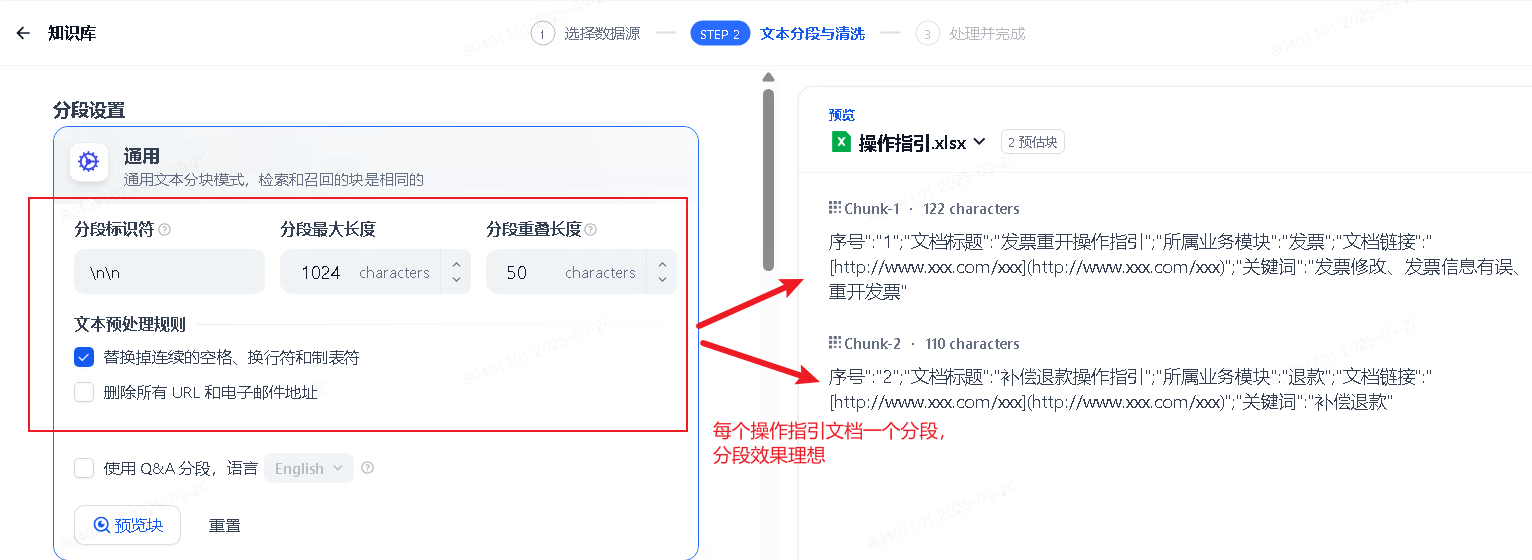
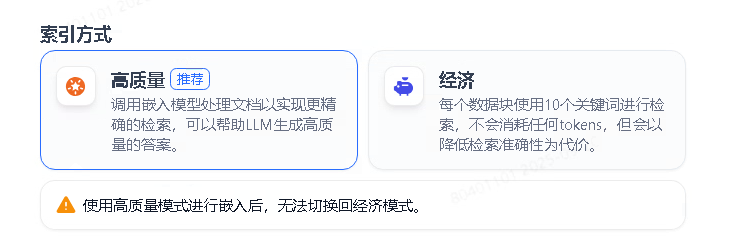
3.3.2. 索引方式设置
考虑优先要保证检索结果的准确性,因此选择了高质量索引,高质量索引将文档和用户输入问题都向量化,通过向量相似度计算来检索出最相关的内容,不同于经济索引只是用关键词检索,它能够准确理解用户问题中的语义,提高信息精准匹配率。
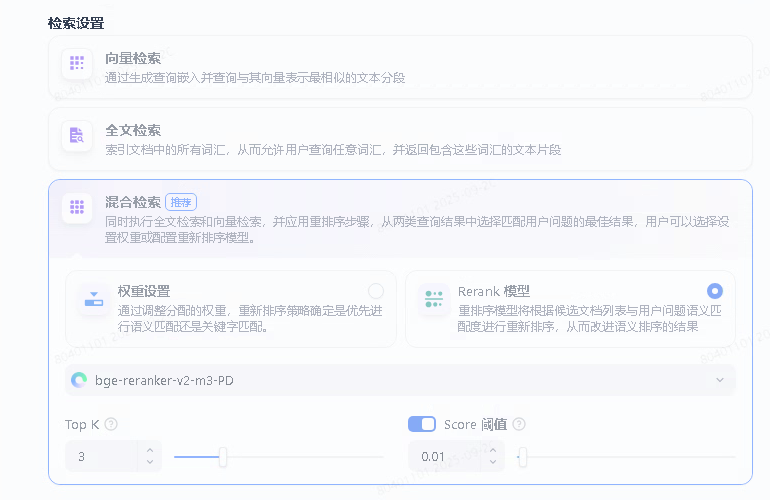
3.3.3. 检索设置
采用了混合检索的模式,这种模式结合了向量检索能够理解语义的优点和全文检索根据关键词精确匹配的优点。另外,设置Top K和Score的值,从而整体提升知识库返回内容的相关性和准确性。
3.4. 提示词优化
目的:通过结构化的提示词,让大模型尽可能地按照我们的预期去执行任务,输出结果。
手段:使用markdown格式的提示词,明确指定角色、任务、输入输出的要求等,具体例子参考上面2.4.的用户问题预处理prompt和RAG输出信息提取prompt。
更多推荐


 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)