
Qwen3-VL双版本重磅发布:2B轻量与32B高性能模型重塑多模态AI应用格局
多模态人工智能领域再迎新突破,Qwen3-VL模型家族近日正式发布两款全新成员——2B参数轻量级版本与32B参数高性能版本。这一重大更新不仅丰富了开发者的技术选型,更在性能维度实现跨越式提升,其中32B版本在国际权威评测基准中表现抢眼,全面超越GPT-5 mini、Claude 4等主流竞品,尤其在科学与工程(STEM)问题求解、跨模态问答(VQA)、图文识别(OCR)、视频内容解析及智能代理任务
Qwen3-VL双版本重磅发布:2B轻量与32B高性能模型重塑多模态AI应用格局
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-8B-Instruct-FP8
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-8B-Instruct-FP8 多模态人工智能领域再迎新突破,Qwen3-VL模型家族近日正式发布两款全新成员——2B参数轻量级版本与32B参数高性能版本。这一重大更新不仅丰富了开发者的技术选型,更在性能维度实现跨越式提升,其中32B版本在国际权威评测基准中表现抢眼,全面超越GPT-5 mini、Claude 4等主流竞品,尤其在科学与工程(STEM)问题求解、跨模态问答(VQA)、图文识别(OCR)、视频内容解析及智能代理任务中展现出行业领先的处理能力。
 如上图所示,该架构图清晰呈现了Qwen3-VL的技术内核,包括Interleaved-MRoPE位置编码机制与DeepStack跨模态融合模块。这些核心技术组件共同支撑了模型在长上下文处理与多模态理解上的卓越表现,为开发者深入理解模型原理提供了直观参考。
如上图所示,该架构图清晰呈现了Qwen3-VL的技术内核,包括Interleaved-MRoPE位置编码机制与DeepStack跨模态融合模块。这些核心技术组件共同支撑了模型在长上下文处理与多模态理解上的卓越表现,为开发者深入理解模型原理提供了直观参考。
在文本识别能力方面,Qwen3-VL实现了语言支持范围的大幅扩展,现已覆盖32种语言的文字识别,较上一代模型的19种语言支持实现了68%的增幅。针对实际应用中常见的低光照成像、运动模糊、非水平文本等复杂场景,模型通过专项优化算法显著提升了识别鲁棒性。特别值得关注的是,其在古汉语典籍、专业学术文献等特殊文本类型的识别准确率上实现突破,同时支持PDF、CAD图纸等复杂格式文档的结构化信息提取,为数字人文研究、工程图纸数字化等专业领域提供了高效工具。
上下文理解能力的跃升成为Qwen3-VL的核心竞争力之一,模型原生支持256K tokens的超长文本处理窗口,通过动态上下文扩展技术可进一步拓展至百万tokens级别。这一特性使其能够流畅处理整卷书籍的阅读理解、连续数小时视频的内容分析,并实现毫秒级精度的关键信息定位。在实际应用中,该能力有效解决了传统模型在跨章节逻辑推理、视频情节时序分析等长程依赖任务中的性能瓶颈,为知识图谱构建、智能视频剪辑等场景提供了技术支撑。
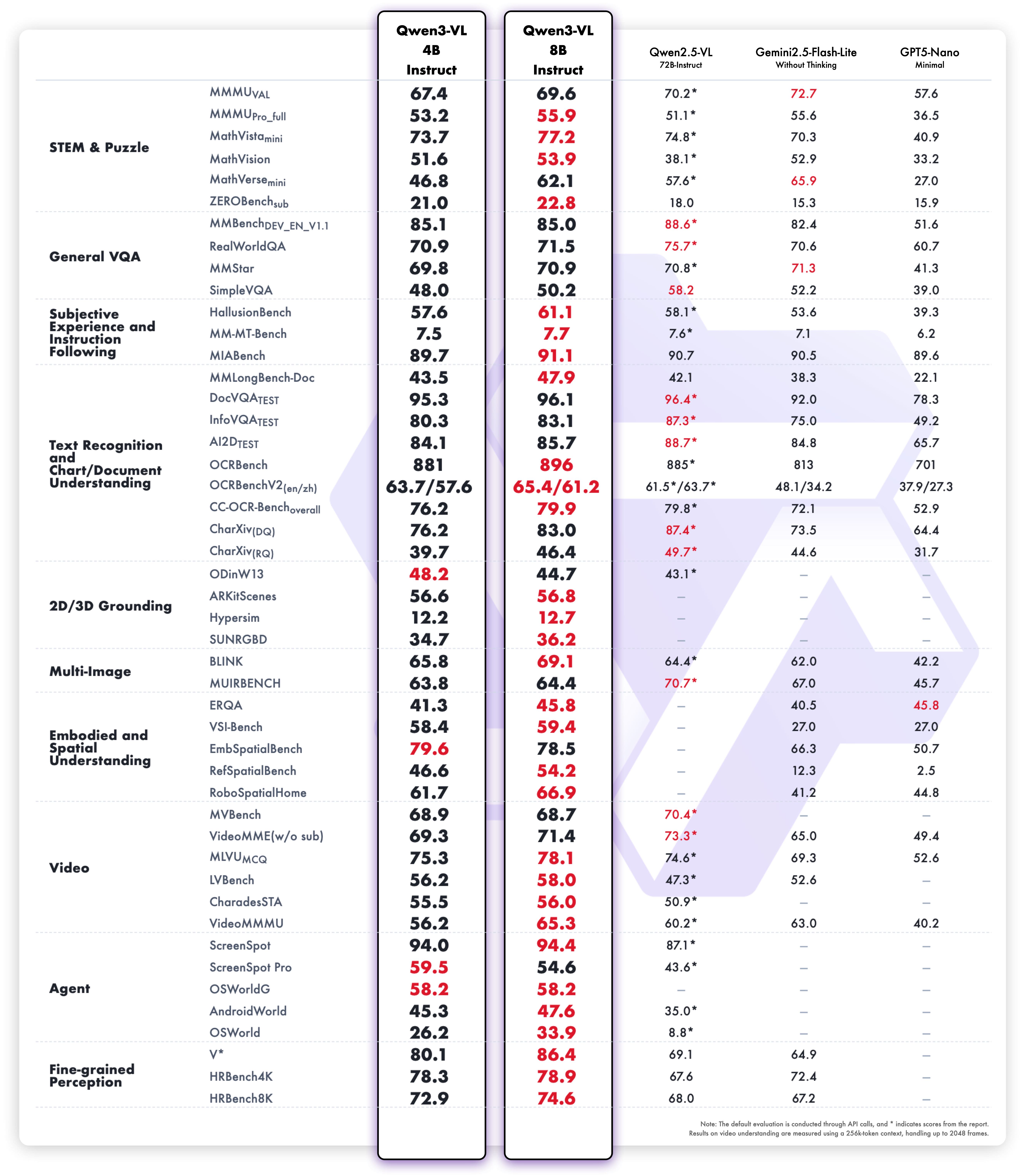 该对比图直观展示了Qwen3-VL不同参数版本在多模态任务中的性能表现,包括图像描述生成、视觉问答准确率等关键指标。通过4B与8B版本的横向对比,清晰呈现了模型性能随参数量级增长的变化趋势,为开发者根据应用场景选择合适版本提供了数据支持。
该对比图直观展示了Qwen3-VL不同参数版本在多模态任务中的性能表现,包括图像描述生成、视觉问答准确率等关键指标。通过4B与8B版本的横向对比,清晰呈现了模型性能随参数量级增长的变化趋势,为开发者根据应用场景选择合适版本提供了数据支持。
视觉内容的结构化生成能力成为Qwen3-VL的创新亮点,模型能够直接基于输入图像或视频内容,自动生成可编辑的Draw.io流程图、前端开发代码(HTML/CSS/JS)等结构化输出。这一功能将传统的图像理解能力提升至创造性输出层面,极大简化了UI/UX设计、技术文档自动化等工作流程。配合其增强的三维空间感知能力,Qwen3-VL可精准识别物体空间坐标、视角转换关系及遮挡层次,为室内设计可视化、机器人环境导航等嵌入式AI应用开辟了新路径。
多模态推理引擎的深度优化使Qwen3-VL在科学问题求解领域表现突出,通过融合视觉符号系统与逻辑推理链,模型能够对数学公式、物理实验图像等复杂输入进行因果分析,提供可追溯的分步解答过程。视觉识别范围也实现指数级扩展,现已覆盖全球知名人物、动漫角色、商业品牌、自然地标及数百万种动植物物种,结合知识图谱关联技术,实现了从图像识别到语义理解的完整闭环,真正具备了"见物知义"的认知能力。
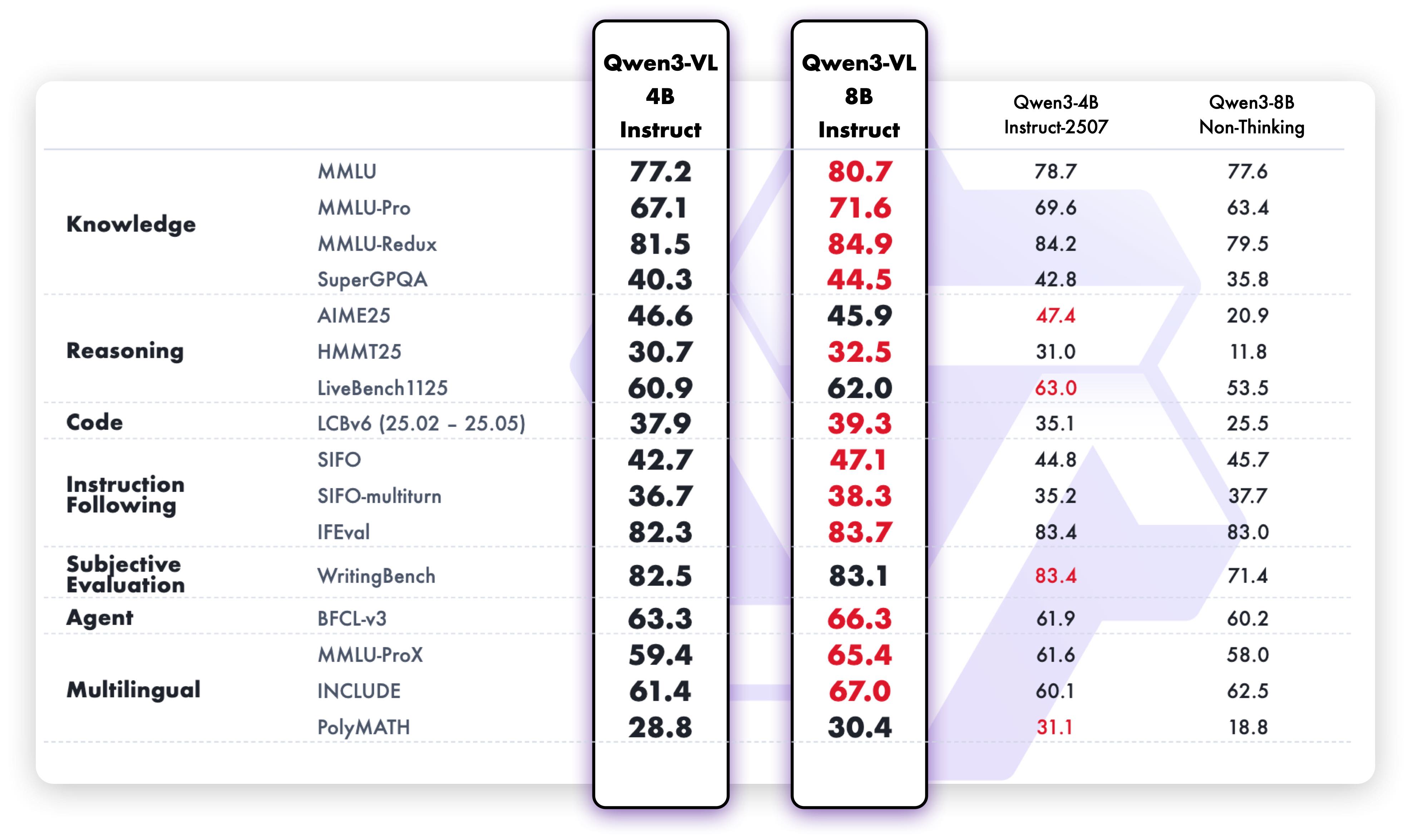 此图表对比展示了Qwen3-VL模型在纯文本任务中的性能表现,包括阅读理解准确率、逻辑推理得分等核心指标与传统大语言模型的对标情况。数据显示即使在纯文本场景下,多模态模型也达到了专业语言模型的性能水平,印证了Qwen3-VL在保持跨模态优势的同时,未牺牲文本处理能力。
此图表对比展示了Qwen3-VL模型在纯文本任务中的性能表现,包括阅读理解准确率、逻辑推理得分等核心指标与传统大语言模型的对标情况。数据显示即使在纯文本场景下,多模态模型也达到了专业语言模型的性能水平,印证了Qwen3-VL在保持跨模态优势的同时,未牺牲文本处理能力。
从行业发展视角看,Qwen3-VL双版本的推出标志着多模态AI技术进入"性能-效率"双轨发展阶段。2B轻量版本以其资源占用低、部署成本小的优势,为边缘计算设备、移动应用开发提供了高效解决方案;而32B高性能版本则通过极致性能满足企业级复杂场景需求。随着模型在代码生成、3D理解等领域的持续进化,Qwen3-VL有望在智能制造、数字内容创作、智能城市等关键领域推动生产力变革,为AI技术的产业化落地提供更广阔的想象空间。
更多推荐


 13
13 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)