
UCM 领读计划 #01:KV Cache 前沿论文解析,突破多上下文推理效率瓶颈的新算法
UCM领读计划
欢迎加入 UCM 社区“领读计划”第 01 期。本期我们共同解析 《Sparse Attention Across Multiple-Context KV Cache》。这篇论文针对 KV Cache 在多上下文下的复杂调度,提出了一套行之有效的稀疏注意力方案。我们将拨开算法的迷雾,解析其如何精准切入并优化大模型推理中的性能瓶颈。
论文信息
论文名称:Sparse Attention Across Multiple-Context KV Cache
作者:Ziyi Cao, Qingyi Si, Jingbin Zhang, Bingquan Liu
机构:哈尔滨工业大学·华为数据存储产品线
论文链接: https://arxiv.org/abs/2508.11661
Part.1 摘要
在大语言模型(LLM)的长文本推理任务中,如何高效处理多上下文检索增强生成(RAG)场景,一直是推理效率与内存占用的瓶颈。传统方法往往需要完整加载历史KV Cache,导致GPU内存消耗巨大。本文创新性地提出了 SamKV方法,首次在多上下文场景下实现了KV Cache 稀疏化与局部重计算。通过显著提升推理吞吐量,该方法为长文本多跳问答及复杂推理任务提供了一套高效且可扩展的解决方案。
.Part.2 研究背景与挑战
随着大语言模型在问答、对话、教育等领域的广泛应用,用户请求越来越复杂,尤其是在多上下文RAG场景中,系统需要同时处理多个检索文档作为上下文输入。传统KV Cache复用方法虽然提升了单上下文的推理效率,但在多上下文场景中面临两大挑战:
缺乏跨文档注意力机制:每个文档的KV Cache独立计算,缺少文档间的注意力交互,影响推理准确性;
内存占用高:即使只需重计算部分token,仍须加载全部KV Cache,导致GPU内存压力大。
现有方法如CacheBlend、EPIC等尝试通过重计算缓解注意力缺失,但未能实现缓存稀疏化,内存问题依然突出。
.Part.3 SamKV方法框架
SamKV提出一种“稀疏化+选择性重计算”的双阶段策略,主要包括三个核心模块:
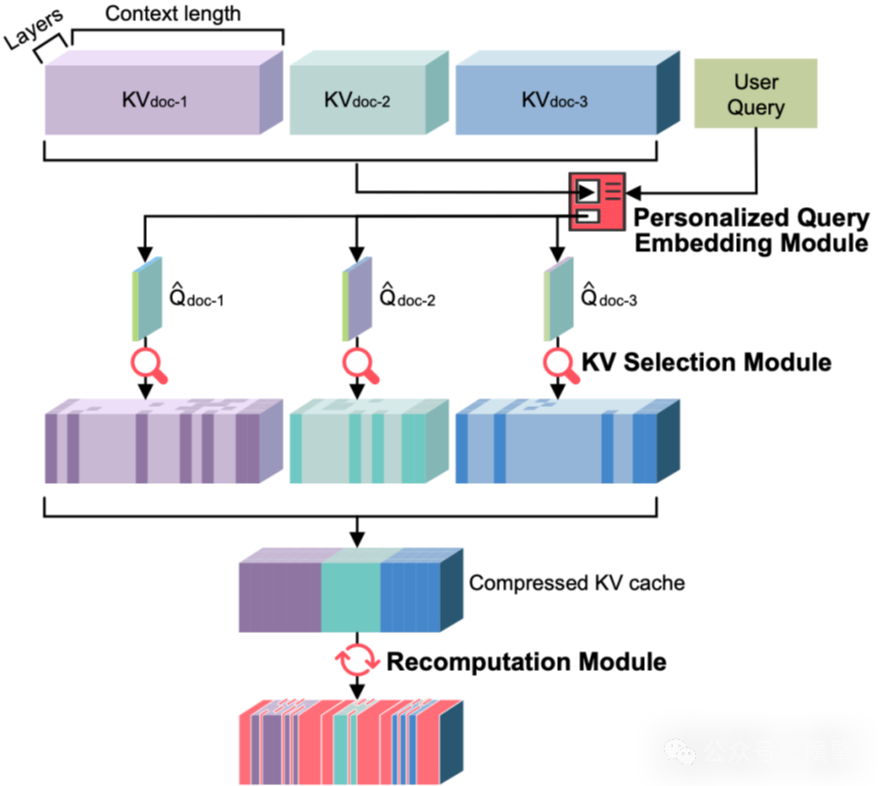
图1:SamKV整体框架示意图
(一)个性化查询向量生成模块
传统方法使用用户查询直接进行稀疏化,难以捕捉多文档间的共识信息。SamKV引入个性化查询向量,在基础查询向量中融合其他文档的局部Q Cache信息,增强跨文档语义关联的识别能力。
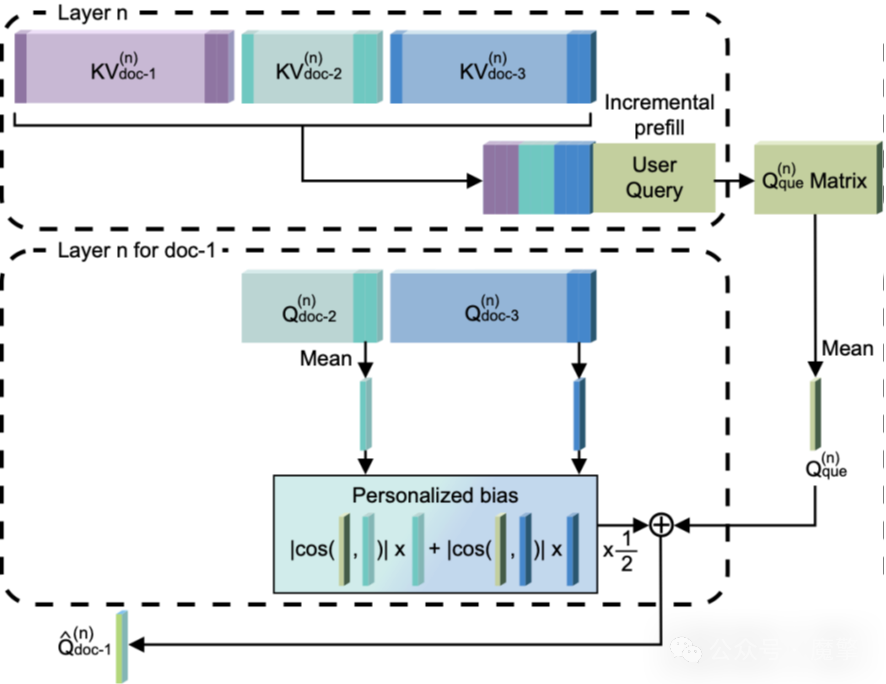
图2:个性化查询向量生成示意图
(二)KV选择模块
SamKV采用动态Top-P采样策略,基于注意力得分动态选择重要KV块。仅保留初始位置与局部位置的KV Cache,对中间段落进行稀疏筛选,最终将KV Cache压缩至原长度的15%。
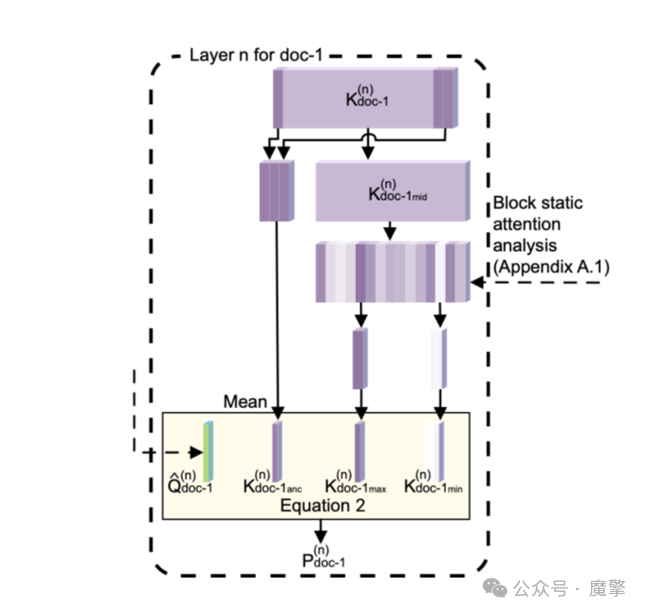
图3:KV选择与稀疏化示意图
(三)重计算模块
为弥补因独立预填充导致的跨文档注意力缺失,SamKV对稀疏化后的KV Cache中关键token进行局部重计算,并支持“覆盖”与“融合”两种更新策略,在减少计算量的同时保持模型性能。
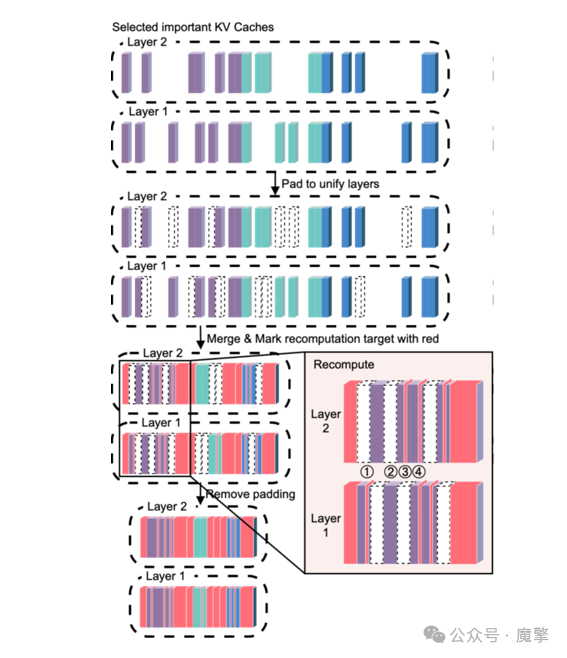
图4:局部重计算与缓存更新示意图
Part.4 实验验证
本文在LongBench的多个长文本问答数据集上评估SamKV,包括2WikiMQA、MuSiQue与HotpotQA,并选用Mistral-7B、Llama3.1-8B等模型进行对比。
(一)性能对比
实验结果显示,SamKV在多数数据集上优于现有多上下文方法(如CacheBlend、EPIC),甚至在2WikiMQA和HotpotQA上超过完整重计算基线。例如,在Llama3.1-8B上,SamKV在HotpotQA上F1达到35.27,显著高于完整重计算的24.12。
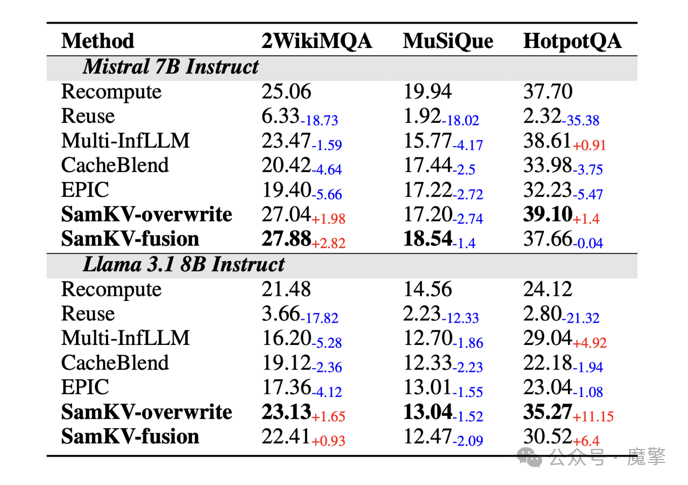
表1:SamKV与Baseline在多数据集上的F1性能对比
(二)消融实验
通过对“是否选择中间KV Cache”、“是否添加个性化偏置”、“是否进行重计算”三个维度的消融分析,验证了各模块的有效性。实验表明,局部重计算可提升F1约6%~7%,且稀疏化后仅重计算少量token即可显著缓解跨文档注意力缺失。
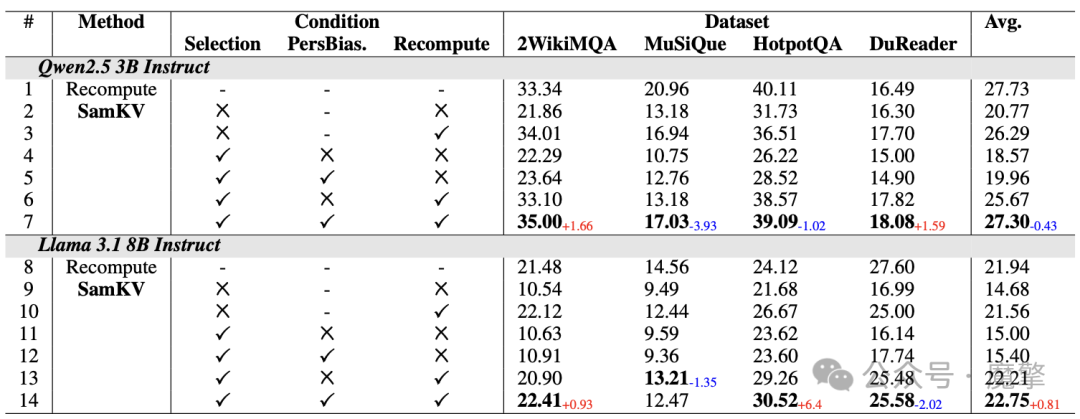
表2:消融实验分析图
Part.5 总结与展
SamKV首次在多上下文场景中实现KV Cache的稀疏化,仅保留15%的缓存即可达到与完整重计算相当的精度,显著降低了GPU内存占用与推理延迟。该方法通过跨文档共识感知的稀疏化与局部重计算,为长文本、多文档的LLM推理任务提供了高效可行的技术路径。
加入UCM社区:

微信号丨 存储小助手 添加存储开源小助手,申请加入UCM开源交流群
更多推荐


 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)