
SparkX企业智能体开发平台 v1.1.0 -增加rerank
·
为什么要引入重排模型?
重排是信息检索流程中的第二阶段,旨在对初步召回的候选文档进行细粒度排序,以提升结果与查询的相关性。其核心是通过语义理解模型对文档与查询的匹配度进行深度评估,超越传统关键词匹配或向量相似度的限制。由于我们用的embedding模型在语义理解上 存在一定的缺陷,因此召回的文本跟语义的匹配不是很完美,我们这里通过重排模型,对结果进行重新排序,则大模型会返回给我们更优质的结果。
开源地址
https://gitee.com/shop-sparker/spark-x
重排模型是怎么工作的呢?
以我本地的一个只是知识库为例子。我这知识库是对《遮天》的主角,叶凡的介绍
现在我提示问题:
叶凡在遮天中的成就
此时系统经过 embedding的召回处理,召回了如下的片段
这些语句是根据embeding 的搜索得来的相似度排名,其对这些语句与 叶凡在遮天中的成就 这个问题的语义理解其实并不完美,这时系统通过重排索引,对这些语句与 问题 叶凡在遮天中的成就 进行打分,得到如下的结果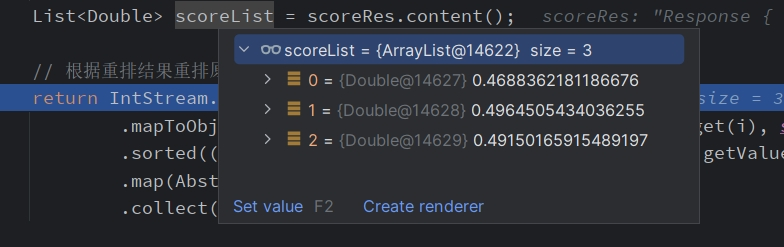
我们可以看到,其实原始的语句排序并不好,第一条的相关性其实是低于后面的。因此我们根据分数的排名重新整理召回的 相关片段
我们按照得分,从高到低,依次把原召回片段重新排序后,再提交给 AI 大模型,这样我们的结果就会更加的精准。
可以在哪里使用重排模型呢?
1、在普通应用中,点击设置,关联知识库的参数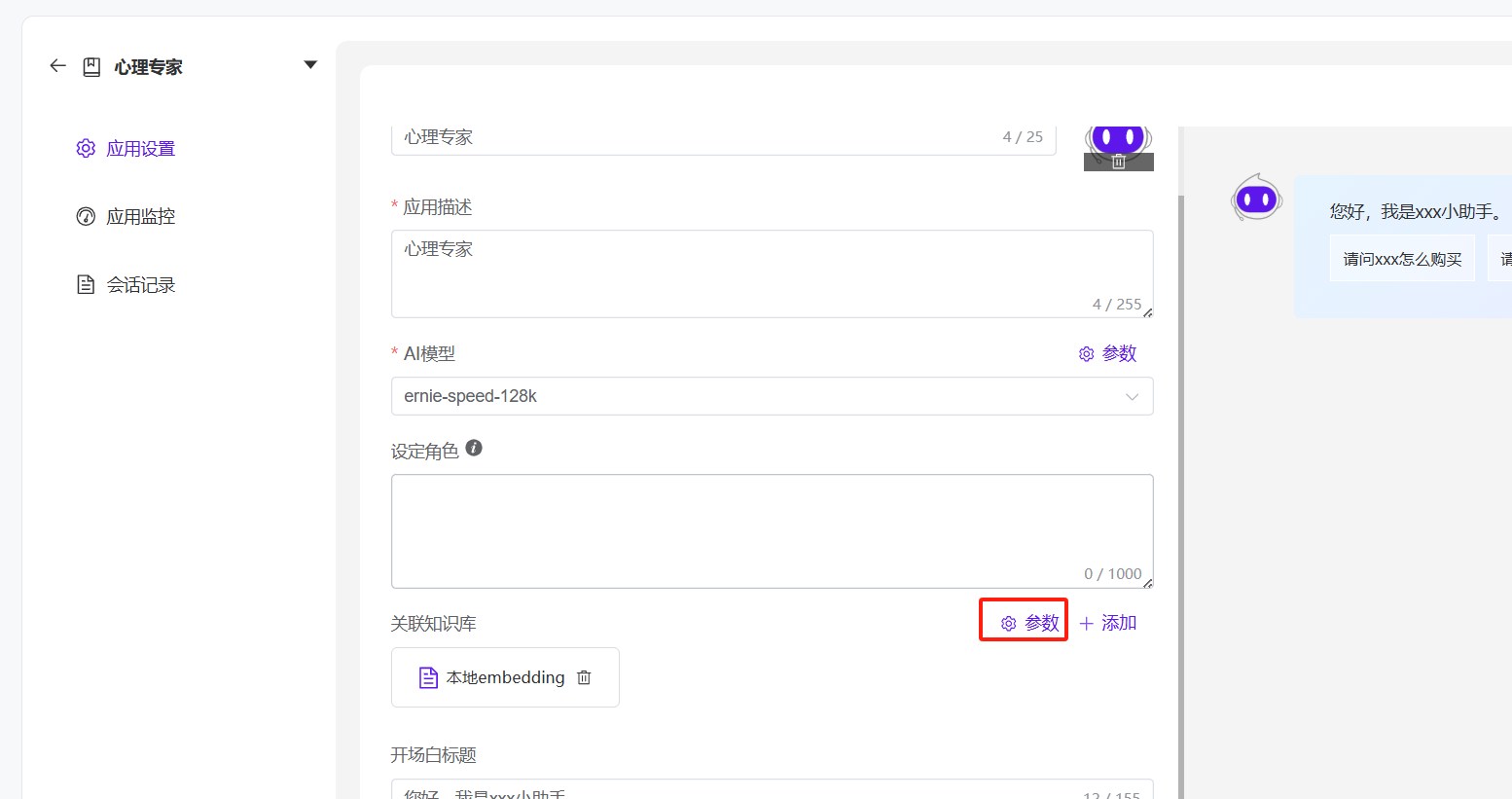
选择你可以使用的重排模型即可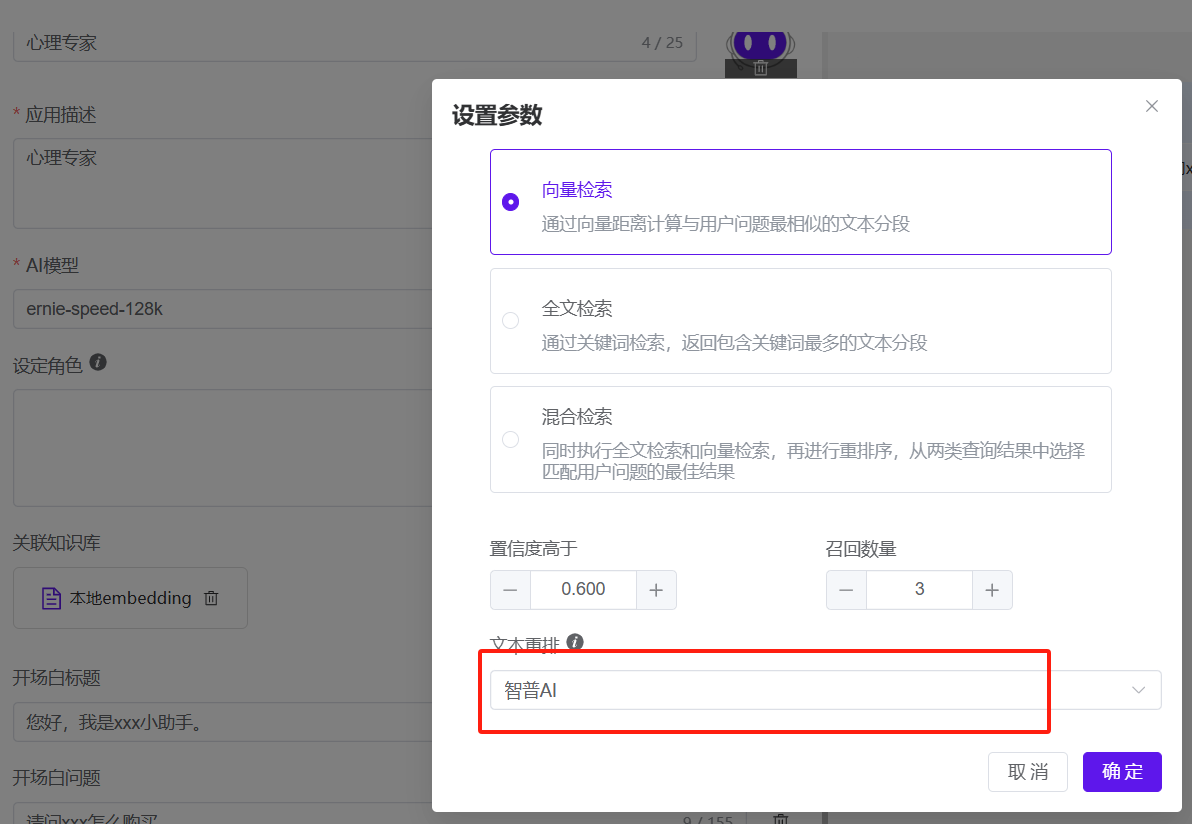
2、在编排中,点击 知识检索 节点,选择重排模型即可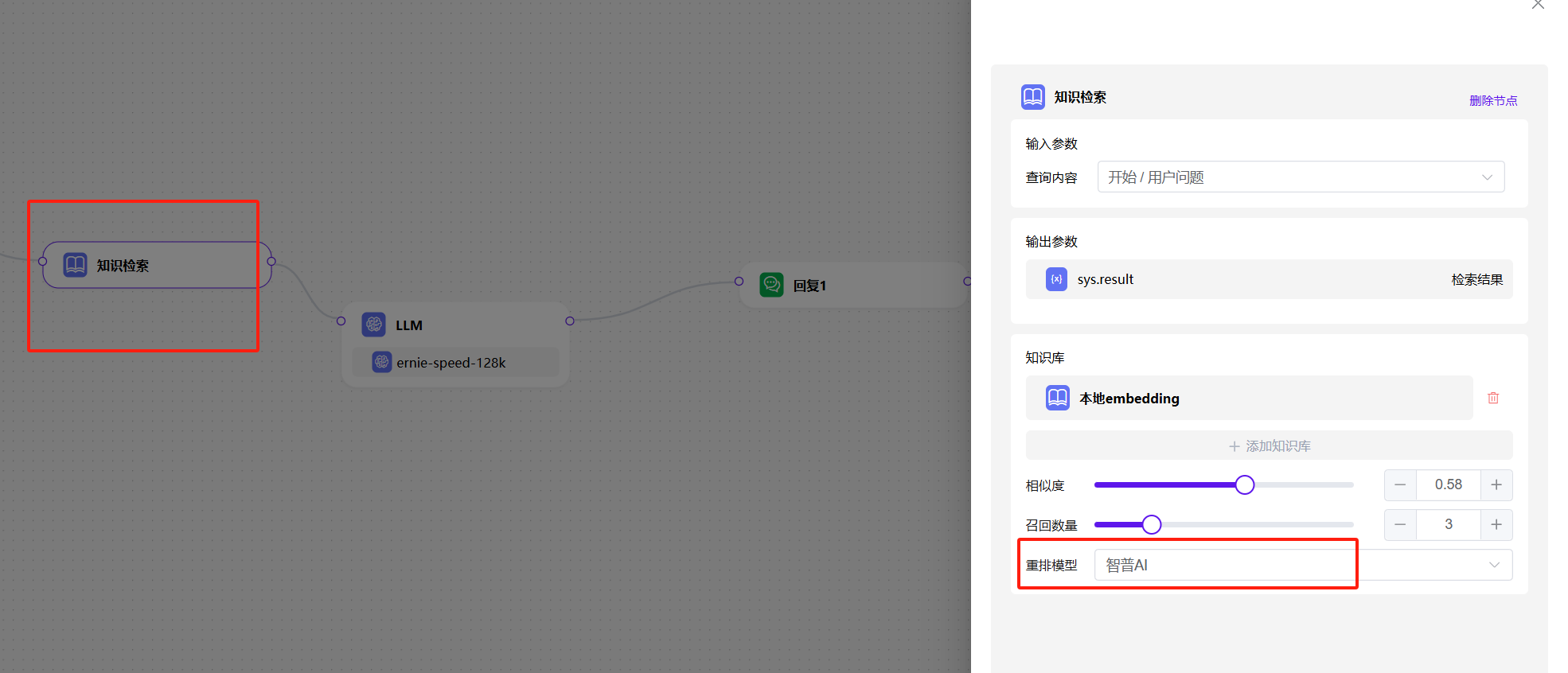
更多推荐


 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)