
Agent方法梳理
摘要 本文系统介绍了多种大语言模型(LLM)优化框架与技术: 验证重试机制:通过初始化配置、验证循环和智能修复策略(如JSONPatch)提升工具调用的准确性。 LATS框架:采用蒙特卡洛树搜索实现思维树扩展,通过"选择-扩展-评估-回溯"四步循环获得结构化解决方案。 LLMCompiler:创新性任务并行框架,通过任务图规划、智能调度和结果合并,显著提升复杂问题处理效率。 多
Extraction
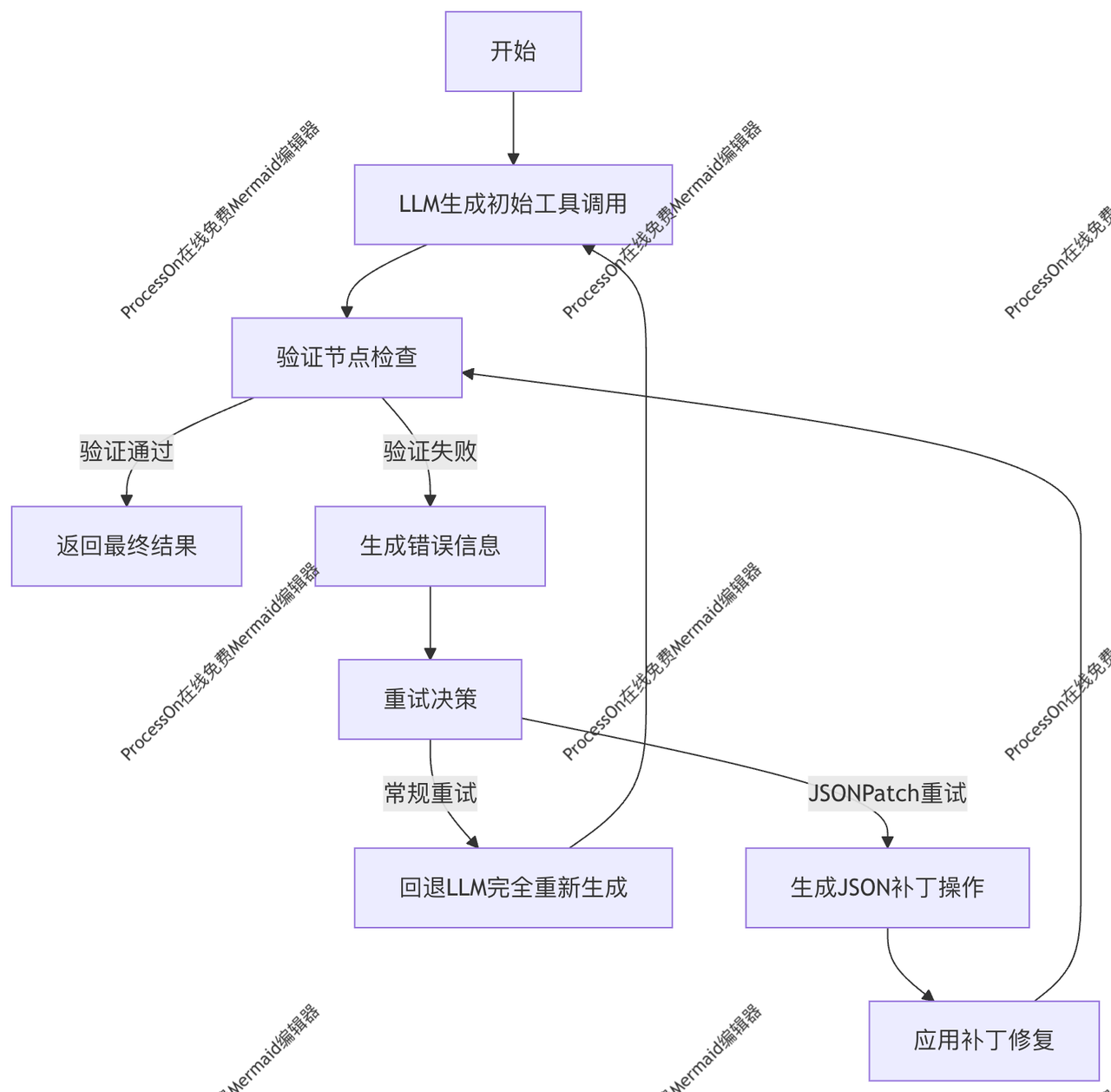
详细步骤
- 初始化阶段:
- 设置 OpenAI API 密钥
- 定义 Pydantic 数据模型和验证规则
- 配置 LLM 工具调用绑定
- 验证重试循环:
- 步骤1: LLM 生成工具调用
- 步骤2: 验证节点检查调用是否符合 schema
- 步骤3: 如果验证失败,根据策略选择重试方式:
- 常规重试:完全重新生成调用
- JSONPatch:生成针对性的补丁操作
- JSONPatch 策略优势:
- 只修复错误部分,保留正确内容
- 提供更精确的错误定位和修复
- 减少重复生成的开销
Lats
![[图片]](https://i-blog.csdnimg.cn/direct/a9498660c4554718ade7317dbe8dae97.png)
LATS(Language Agent Tree Search)
把 LLM 同时当成「策略网络」(下一步怎么走)和「价值网络」(走了以后好不好),用蒙特卡洛树搜索(MCTS)反复“选-扩-评-反”,直到模型在结构化输出里声明 found_solution=true 为止。
核心循环(四步)
- Selection – UCT 选最有潜力的节点
- Expansion – LLM 生成 k 个下一步思考节点
- Simulation – 快速 rollout,LLM 自评得分并调用 Reflection 工具
- Back-prop – 把得分反向更新到整棵树的 Q 值
关键特色
- 思维树 + 自洽投票:把单步 CoT 扩展成树状搜索
- Reflection 工具:强制结构化输出 score 与 found_solution(布尔)
- 终止条件:LLM 在 Reflection 里显式 found_solution=true 即停止
- 可插拔:任何支持 function-calling 的 LLM 都能直接接入
一句话使用指南
把问题丢给根节点 → 运行 LATS 主循环 → 当 LLM 在 Reflection 中返回 found_solution=true 时,当前路径即为最终答案链。
LLM-compiler
LLMCompiler 的核心思想和作用:
一句话总结: LLMCompiler 是一个让大模型(LLM)能够**并行调用多个工具(函数)**来解决复杂问题的框架,它通过将问题分解成一个“任务图”(DAG),并高效地调度执行,从而显著提高了速度和降低了成本。
更具体地说,它由三个主要部分组成
- Planner(规划器):
- 作用:根据用户的提问,LLM 会先生成一个完整的执行计划。这个计划不是一条线,而是一个类似“流程图”的结构(有向无环图,DAG)。
- 核心:它会明确列出需要执行哪些任务(调用哪个工具,输入什么参数),以及这些任务之间的依赖关系。例如,任务 B 可能需要用到任务 A 的结果,那么任务 A 和 B 就必须按顺序执行;而任务 C 和任务 D 互不依赖,就可以同时执行。
- 表示:它会给每个任务编号(如 1, 2, 3…),并用 $1, $2 这样的占位符来表示某个任务的输出结果。
- Task Fetching Unit(任务调度器):
- 作用:一旦规划器生成了任务图,调度器就开始工作。
- 核心:它会像一个高效的“项目经理”,实时监控哪些任务的“前置依赖”已经满足了。一旦某个任务的所有依赖都完成了,调度器就会立即把它送去执行。
- 并行性:这就是实现“并行调用”的关键。调度器会同时把多个互不依赖的任务丢给不同的“工人”(Executor)去处理,而不是像传统方法那样一个一个排队。
- Joiner(合并器):
- 作用:在所有任务都执行完毕后,Joiner 负责整合所有结果,并最终回答用户的问题。
- 核心:它也是一个 LLM。它会根据最初的用户问题和所有工具返回的详细结果,生成一个连贯、准确的最终答案。如果发现结果不足以回答问题,它甚至可以决定让 Planner 重新规划一轮新的任务。
- 举个例子来理解:
假设你问:“苹果公司今天的股价是多少,同时帮我总结一下微软最近的新闻,并比较一下这两家公司的市值。”
- 传统方法(如 ReAct):LLM 会一步一步来:先查苹果股价,再查微软新闻,再比较市值,整个过程是串行的,比较慢。
- LLMCompiler 方法:
- Planner 会生成一个计划:
- 任务1:调用股价查询工具,获取苹果股价。
- 任务2:调用新闻搜索工具,获取微软新闻。
- 任务3:调用市值查询工具,获取苹果市值。
- 任务4:调用市值查询工具,获取微软市值。
- 任务5:比较任务3和任务4的结果(即苹果和微软的市值)。
- Task Fetching Unit 发现任务1、2、3、4互不依赖,于是同时启动四个工具调用,并行执行。
- Joiner 收到所有结果后,整合成一段完整的回答:“苹果公司今天的股价是…,微软最近的新闻是…,经过比较,苹果的市值为…,微软的市值为…”。
总结优点:
- 速度更快:通过并行执行,大幅减少等待时间。
- 成本更低:减少了 LLM 反复串行调用工具的轮数。
- 更可靠:通过提前规划,避免了在复杂任务中“走到一半发现走不通”的问题。
Multi-agent
1. Superviser
用 “一个 Supervisor 大模型 + 多个子 Agent 工具” 的星形架构,让 Supervisor 通过 函数调用 动态决定下一步派给谁干活,子 Agent 干完把结果回传,Supervisor 再决定继续派单或直接返回答案——整条流程用 LangGraph 一张图即可调度,实现“多智能体协作”且新增子 Agent 只需注册为工具。
2. Hierarchical teams
把「大 Boss → 组长 → 组员」三层管理结构搬进多智能体系统:顶层 Supervisor 只负责分派任务给各 Team Leader,Leader 再指挥自己的小队(Researcher / Coder / DocWriter 等)并行干活,最后用 Leader 汇总的结果向 Supervisor 汇报——整颗树由 LangGraph 两级图嵌套实现,可横向扩展任意多团队。
3. Multi-agent-collaboration
一个「去中心化」的多智能体圆桌:没有 boss,只有共享消息黑板;每个 agent 监听黑板,自己判断要不要抢任务;抢到后执行并把结果写回黑板,循环直到有人宣布“我解决了”——全程用 LangGraph 的条件边 + 消息累加实现,新增 agent 只需注册一条“抢单函数”。
plan-and-execute
Plan-and-Execute(计划-执行)一句话总结
先让 LLM 一次性写出「多步计划」,再按步骤依次执行,每步结果回传后由 LLM 动态修订下一步或给出最终答案,实现「先想后干,边干边改」。
核心流程(3 个节点)
-
Plannerprompt:{用户问题} → 生成 Plan(List[str],每步一句指令)
-
Executor(循环)for step in plan:‑ 调用工具 / 检索 / 代码解释器‑ 把「当前步骤结果」塞回 prompt‑ LLM 决定: • 继续执行下一步,或 • 修订剩余计划,或 • 直接跳到 Finalizer
-
Finalizer汇总所有中间结果 → 生成最终回答给用户
关键特色
- 两步分离:先全局计划,再局部执行,降低长链推理的累积错误
- 可观测:每步输入输出透明,便于调试与人类审核
- 动态修订:执行过程中可根据新信息增删改计划
- 工具兼容:任何 LangChain Tool / Agent Executor 都可即插即用
一句话使用指南
用户问题 → Planner 给出计划 → Executor 逐步跑工具 → Finalizer 汇总输出;中间任何一步出现新事实,LLM 都能实时调整后续计划。
Reflection & reflextion
| 维度 | Reflection (langgraph/reflection) | Reflexion (langgraph/reflexion) |
|---|---|---|
| 目标 | 提升单次回答质量(写作、推理) | 提升任务成功率(代码、工具调用) |
| 失败信号 | 无显式失败,仅靠 LLM 自评分数 | 有显式外部测试或奖励 |
| 记忆机制 | 无外部存储,循环内即时使用 | 把失败反思写入可检索的记忆库 |
| 循环粒度 | 文本重写循环 | 任务尝试循环 |
| 典型场景 | 文章润色、QA 优化 | 代码生成、工具链执行、导航任务 |
rewoo
ReWOO(Reasoning WithOut Observation)算法流程逐行拆解
—— 把「一次调用工具」拆成「先写计划→再批量执行→再汇总」三步,显著减少 LLM 对工具返回的反复等待,提升速度与 Token 效率。
- 角色与符号
- Planner:LLM,只负责写「需要哪些工具、调用参数」
- Worker:执行器,真正调用工具,返回结果
- Solver:LLM,把原始问题 + 工具结果拼成最终答案
- 整体 DAG(有向无环图)三阶段
┌-----------┐ ┌----------┐ ┌----------┐
│ Planner ├----►│ Worker ├----►│ Solver │
└-----------┘ └----------┘ └----------┘
纯文本计划 批量并行 纯文本答案 - 详细子流程(对应 notebook 节点)
Step-1 PLAN
输入:用户 question
输出:Plan 对象 = 列表 of ToolInvocation
[
{“tool”: “Search”, “arg”: “2024 法国奥运会奖牌榜”},
{“tool”: “Calculator”, “arg”: “金牌数*0.3”}
]
- 节点函数:planner_node(state) -> {plan: List[ToolInvocation]}
- 无工具调用,零等待。
Step-2 WORK
输入:上一步 plan
输出:results 列表,与 plan 一一对应 - 节点函数:work_node(state)内部同步/异步批量调用工具,返回 List[Any]。
- 失败处理:单个工具报错 → 把异常文本塞进对应槽位,不中断 DAG。
Step-3 SOLVE
输入:question + plan + results
输出:最终答案 - 节点函数:solve_node(state)
- LLM 仅做一次文本合成,不再调用任何工具。
- 状态机定义(Pydantic)
class ReWOOState(TypedDict):
question: str
plan: List[ToolInvocation]
results: List[Any] # 与 plan 同序
answer: str - 条件边(控制流)
planner -> work (无条件)
work -> solve (无条件)
solve -> END - 与 ReAct 对比优势
| 维度 | ReAct | ReWOO |
|---|---|---|
| 工具调用次数 | 多轮交错 | 仅 1 批 |
| LLM 等待 I/O | 每步都等 | 零等待(planner & solver) |
| Token 消耗 | 反复拼接历史 | 只拼一次结果 |
| 并行度 | 无 | 工具可全并行 |
| 适用场景 | 需动态调整 | 工具集合可静态枚举 |
- 一句话总结
ReWOO 先把「需要什么工具、参数」一次性规划成纯文本,再批量跑完工具,最后让 LLM 只看结果写答案——用 “先计划后执行” 砍掉 ReAct 的反复等待,省 Token 又提速。 - 一句话区分plan & execute和rewoo
Plan & Execute 是「先写步骤清单,再一步一步顺序执行,边跑边改计划」;
ReWOO 是「先写工具清单,再一次性批量调用所有工具,最后一次性汇总写答案」——前者动态迭代,后者静态批跑。
| 维度 | Plan & Execute | ReWOO |
|---|---|---|
| 计划内容 | 自然语言步骤(可含逻辑、判断) | 明确的工具调用签名(tool + arg) |
| 执行节奏 | 顺序执行,每步后可增删改计划 | 一次批量并行,计划不可变 |
| LLM 等待 I/O | 每步工具返回后都要再唤醒 LLM | 零等待(Planner 与 Solver 之间) |
| 中间反馈 | 能利用上一步结果决定下一步 | 工具结果只最后一次性看 |
| 适用场景 | 步骤依赖前后文、需动态决策 | 工具调用彼此独立、可并发 |
| 实现节点 | Planner → Executor(循环)→ Finalizer | Planner → Worker → Solver |
记忆口诀
Plan-Execute:步步为营,边走边改;ReWOO:一锤子买卖,批完收工。
self-discover
Self-Discover 一句话总结
让 LLM 先“自省”:根据任务类型,自己从原子模块池里挑选、组合、拼接成一条最适合的推理结构(推理链模板),再按该模板一步步生成答案——全程零人工预设模板,结构可解释、可迁移、可复用。
原子模块池(可扩展)
- llm: 直接让 LLM 回答
- cos: 常识推理
- math: 符号/方程推理
- scientific: 科学方法
- logic: 逻辑链
- code: 写代码再执行
… 共 20+ 个预定义模块(notebook 用 16 个)
三阶段流水线(对应 notebook 节点)
-
SELF-DISCOVER输入:{task_description}动作:LLM 阅读任务 → 从原子池选若干模块 → 输出 JSON
{
“selected_modules”: [“cos”, “math”, “logic”],
“structure”: “cos → math → logic”
} -
ADAPT输入:上一步 JSON动作:LLM 把选中的模块拼成一条自然语言推理链模板(含占位符)输出:模板字符串,例如
Step1 用常识解释问题;Step2 建立方程;Step3 用逻辑验证… -
IMPLEMENT输入:原始问题 + 模板动作:按模板依次调用对应模块(或 LLM 自身)填值输出:最终答案
状态机定义(极简)
class SelfDiscoverState(TypedDict):
task: str
selected: List[str] # 阶段1输出
template: str # 阶段2输出
result: str # 阶段3输出
与 Few-Shot / CoT 的区别
| 方法 | 模板来源 | 迁移性 | 可解释性 |
|---|---|---|---|
| Few-Shot | 人工写示例 | 任务一变就失效 | 低 |
| CoT | 人工写“Let’s think step by step” | 通用但粗糙 | 低 |
| Self-Discover | LLM 自组合原子模块 | 新任务自动生结构 | 高(模块+链可视) |
一句话用法
给模型一个任务 → 它先写“我该用哪几步” → 再按自己写的步骤执行 → 输出答案;模板、步骤、模块选择全程自生成,人类只维护原子模块池。
tnt-llm
一句话,TNT-LLM 是“让 LLM 自己写测试、自己跑测试、自己修 bug”的半自动化微调框架——用同一套 LLM 流水线在“测试生成 → 执行 → 故障定位 → 数据过滤 → 微调”里循环,几小时就能低成本蒸馏出一个小模型,效果往往好过直接人工标数据。
具体流程(官方教程 5 步闭环)
-
Task Spec → 统一任务描述把任何任务都转成“输入/输出 JSON 模板 + 自然语言指令”,保证同一脚本可复用到分类、抽取、翻译等不同场景。
-
TestGen(炸弹制造)LLM 按模板 + 指令批量生成候选测试样本(含输入+期望输出)。
- 用 temperature>1 多采样,保证多样性。
- 输出自带“置信分”,方便后面过滤。
- TestExec(炸弹引爆)把上一步生成的样本立即喂给同一个 LLM 执行一遍,得到实际输出。
- 自动对比“期望输出 ≠ 实际输出” → 把不一致的样本标为 失败用例。
- Diag & Filter(拆弹回收)
- 用规则 + 同一 LLM 做故障定位:是标签错?格式错?还是指令歧义?
- 只保留“LLM 自己能稳定答对”或“经轻量重写后可答对”的样本,其余扔掉。
- 结果得到一份高质量自洽训练集(通常比原始生成量少 30 %–60 %)。
- Fine-tune(再造战士)用过滤后的数据对小模型(7 B/13 B)做轻量级 LoRA 微调。微调后的小模型即可部署,也可回到第 2 步继续“自循环”提升。
给定任务描述文件和预算(生成多少条),脚本自动走完闭环并吐出微调后的小模型权重。
Tot
Tree-of-Thoughts(ToT) 的核心机制用“一句话 + 一张图 + 三点对比”帮你梳理清楚,并把它与 LLMCompiler 做直观对照。
- 一句话总结
ToT 让 LLM 像“下围棋”一样在脑子里同时开多盘棋:每一步先快速长出若干“候选落子”,再打分、剪枝、往前推演,直到某条思路彻底走通或超时为止。 - 工作流程(对应教程里的 24 点示例)
┌──────────┐ 生成 k 个候选式子 ┌──────────┐ 计算得分 ┌──────────┐ 保留 top-b ┌──────────┐
│ expand ├──────────────────►│ score ├──────────►│ prune ├──────────►│ 继续/终止 │
│ (Thought)│ │ (Evaluator)│ │ (Beam) │ │ (DFS/BFS) │
└──────────┘ └──────────┘ └──────────┘ └──────────┘
- expand:LLM 一次提出多个下一步(并行采样)。
- score:用 LLM 或规则给每个下一步打分(是否更接近 24、是否合法)。
- prune:按得分只留前 b 个(beam width),其余剪掉。
- 继续/终止:若某条路径已得 24 → 结束;否则把幸存者送回 expand,深度 +1,直到 max_depth。
- 与 LLMCompiler 的三点核心差异
维度
LLMCompiler
Tree-of-Thoughts
核心目标
并行调用外部工具以缩短端到端延迟
并行探索内部推理路径以提高解题质量
图结构
静态 DAG(有向无环),任务节点是工具调用,边是数据依赖
动态树(Tree),节点是“思路”,边是推理步骤
并行点
不同工具间真正同时发请求(I/O 并行)
同一层兄弟节点批量采样(LLM 并行生成),但后续仍要逐层展开 - 什么时候选谁?
- 工具密集型(查股价、搜新闻、调 API)→ LLMCompiler:一次把能跑的工具全跑完,省时间省钱。
- 推理密集型(解 24 点、填字谜、数学证明)→ ToT:让模型自己“多试几条路”,避免一条道走到黑。
把两者放在同一张图里看: - LLMCompiler 是“横向”拓宽,同时把外围信息拉回来;
- ToT 是“纵向”加深,反复自我博弈直到找出最优链。
Reference
https://github.com/langchain-ai/langgraph/blob/main/docs/docs/tutorials
更多推荐
 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)