
站在 Java 程序员的角度如何学习和使用 AI?从 MVC 到智能体,范式变了!
本文探讨了Java开发者如何适应AI技术变革,分析了从传统MVC开发向AI Agent模式的范式转变。文章指出,LLM(大语言模型)作为预测性无状态系统存在输入限制、缺乏记忆等固有缺陷,而AI智能体通过三大核心技术解决了这些问题: Prompt工程 - 控制模型行为 RAG技术 - 动态注入外部知识(结合语义检索与关键词检索) MCP架构 - 赋予模型工具调用能力(API/DB/代码执行) 文章还
文章目录
前言
今天给大家分享一下站在 Java 程序员的角度如何学习和使用 AI,相信我,如果你对这部分知识不甚了解,看了这个视频绝对对你大有帮助。之所以选择学习这部分内容,既是因为现在 AI 发展得非常好,也是因为这部分内容也确实简单,收益非常的高。在开始之前,先问大家几个问题:
- 你能分清楚开发 AI 和应用 AI 吗?
- 你能区分出 LLM 和 AI 智能体吗,ChatGPT 官网是一个 LLM 还是一个 AI 智能体?
先回答第一个问题,开发 AI 指的是训练 AI 模型,除此之外,都是在应用 AI,本文也是在讲解 AI 的应用技术。
那么到底什么是 LLM 以及它自身的限制——AI 智能体解决了什么问题
LLM 是一个可以根据用户输入的 Token 并结合自己的训练数据集预测下一个最可能出现的 Token 的软件,仅此而已,并且这个过程是无状态的。所以 LLM 天然具有以下限制:
- 输入 Token 是有限制的,输入输出 Token 的总和限制在一个范围内
- 没有记忆功能
- 无法知道训练集之外的信息
- 没有操作本地环境的能力
而 AI 智能体,就是在解决了这些问题之上,具有一定功能的应用。
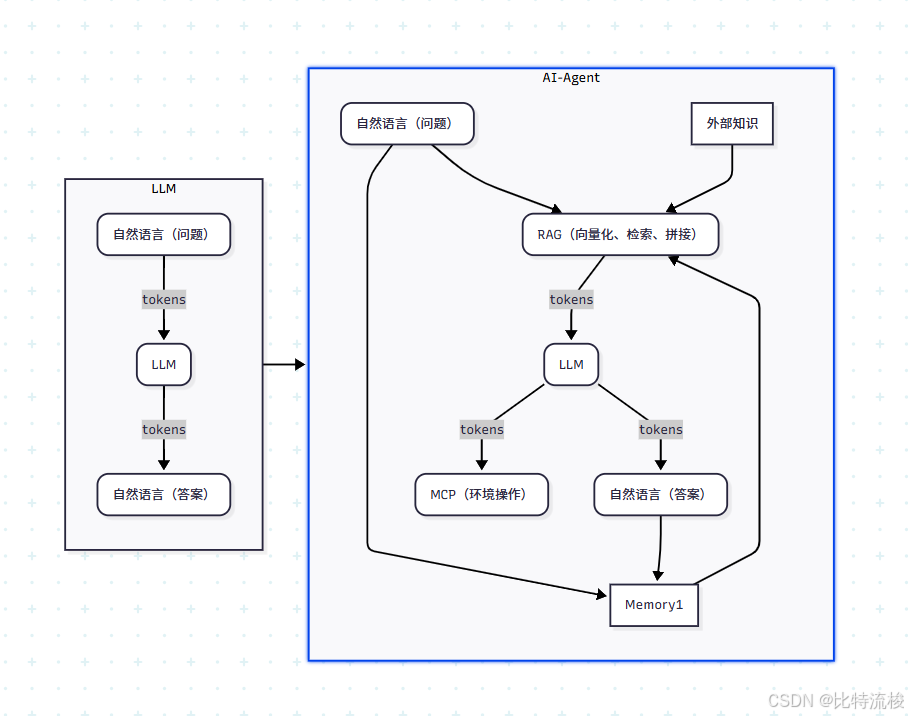
编程范式的变化
其实 LLM 刚火的时候我并不关心。作为一个后端开发者,我第一反应是:又来了一个新的 SDK 而已嘛。但直到我将它真正的应用到生产项目中,我才突然意识到,这不仅是多了个 SDK,更像是一次开发范式的升级。
我们来看一下这张图,左上角是我们熟悉的传统 MVC 开发流程:
- 一个接口进来,对应一个 controller;
- controller 调用 service;
- service 最终访问数据库、缓存,或者调用远程服务。
这个过程的控制流和数据流都非常明确。而在左下角,AI 应用的结构就完全不一样了:
- 用户进来的不是一个“接口请求”,而是一段自然语言;
- 中间的“控制器”被一个**提示词工程(Prompt Engineering)**替代;
- 它可能是一个简单 prompt,也可能是一个复杂的 RAG 流程(比如先去向量库查资料);
- 然后通过“路由”逻辑,决定调用哪个工具、数据库、系统,执行实际操作。
值得注意的是,在 AI Agent 模式下,各个模块的流程控制并不是手动调用的,而是由 LLM 的输入输出自行决定的。所以说,从传统 MVC 到 AI Agent,就像 Spring 框架的控制反转一样,我们正在经历一次从“我来写逻辑”到“模型来选逻辑”的范式转变。
一切都是围绕输入输出展开的 —— Prompt 工程、RAG 与 MCP
我们用大模型做应用,核心就是控制两个东西:
- 喂进去什么(输入)
- 读出来什么(输出)
围绕这个目标,发展出了三个核心组件:
1. Prompt Engineering(提示词工程):控制 LLM 的行为
提示词就是你给模型的指令。它可以简单一句话,也可以是几百行的复杂提示(文本格式、文本推断、文本概括、文本转换、文本扩展、防注入等)。但提示词工程解决不了两个痛点:
- 模型知识有限(不知道你的内部资料)
- 提示词太长会超过 Token 限制
这就引出了 RAG。
2. RAG(Retrieval-Augmented Generation):把“外部知识”注入模型
RAG 是为了给 LLM 提供“参考资料”,它的流程可以分为两个阶段:
Retrieval(检索)
你不能把所有资料塞进 prompt,只能在用户提问时动态选出最相关的内容。这一步我们有两种技术路线:
| 方法 | 说明 | 优势 | 劣势 |
|---|---|---|---|
| 全文检索(Full-text Search) | 用关键词匹配(如 Elasticsearch) | 精度高、实时性好 | 不理解语义 |
| 向量检索(Semantic Search) | 把问题和文档都转成 embedding,算相似度(如 Qdrant、Weaviate、FAISS) | 能理解同义词、上下文 | 依赖 embedding 质量 |
通常我们会向量检索为主,关键词检索为辅,提高覆盖率和准确率。
拼接成 Prompt
选出相关文档后,把它们和问题一起组成新的 Prompt,再送给 LLM,让它在有背景资料的情况下回答。这样就绕过了模型的知识盲区,答案更准确。
3. MCP(Multi-step Code Planning / Tool Use):让模型有“动手能力”
即便模型有了知识,它也不能执行操作。比如它不能:
- 查询数据库
- 发起 HTTP 请求
- 调用 Java 方法
- 执行脚本 / 命令行
这时我们就要加上一套机制,让 LLM 能说:
“请调用 searchProduct 接口,参数是 name=MacBook”
你把这段结构化输出解析出来,真正去调用你写的函数、API、服务,执行完再把结果传回模型。这个过程就叫 Tool Use / Function Calling / MCP。
进一步提升——多模态、多轮检索
随着大模型的能力不断演进,我们已经不再局限于单轮文本输入输出,AI 应用正进入两个重要方向:
1. 多模态输入
现在主流大模型(如 GPT-4o、Claude 3、Gemini)都支持多模态输入:
- 图片、图表、PDF、语音、视频,甚至是拖拽上传文件
- 输出也可以是结构化 JSON、图片,甚至带情感语音
例如你上传一张图表问:“这图说明了什么?”,模型不仅能识别内容,还能结合标题和颜色给出分析——这超出了传统 NLP 的范畴。
2. 多轮对话 & 多角色协作
复杂任务通常不能一问一答搞定,这时候我们需要多个模型/组件协作执行任务。例如一个任务链可以分成:
- 思考 Agent:判断用户意图
- 检索 Agent:找相关信息(RAG)
- 规划 Agent:组织调用顺序
- 工具执行 Agent:执行具体操作
最后由一个模型将结果整合,给出自然语言回复。这种流程就叫多轮多步协作(multi-agent planning + multi-step RAG)。
规范化——Spring AI 和 LangChain4j
前面提到的 Prompt、RAG、MCP、Memory 等,虽然可以用 HTTP + JSON 手写实现,但工程上显然不现实。这时就需要“把这些通用组件封装起来”,而对 Java 工程师来说,现在有两个主流框架可以用:
-
Spring AI(Spring 官方出品)
- 支持常见模型:OpenAI、Azure、Gemini、HuggingFace 等
- 用 Spring Boot 风格配置模型调用、RAG、Function calling
- 内建 Prompt 模板(Thymeleaf)、Embedding 支持、Memory 支持
-
LangChain4j
- Java 社区实现的 LangChain 生态移植
- 专注构建 Agent、RAG、Retriever、ToolChain 等组件
- 支持与向量数据库、嵌入模型无缝对接
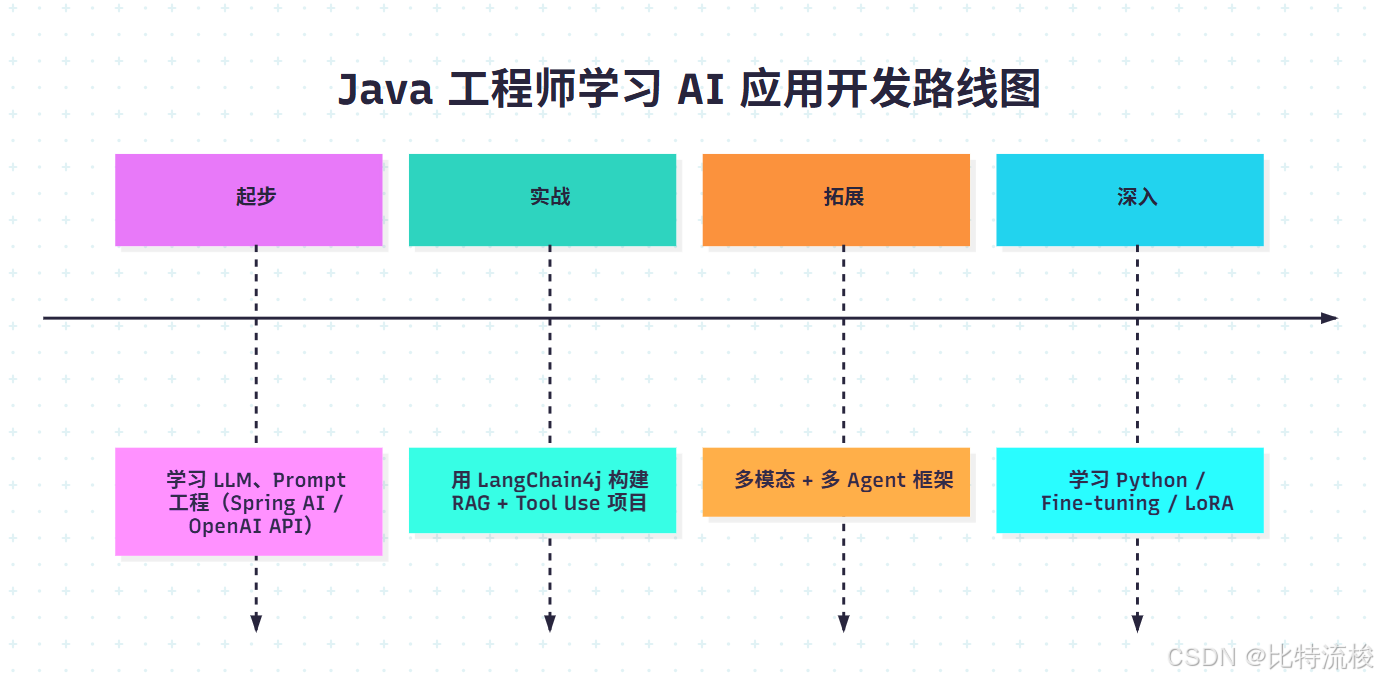
如何学习
如果你是 Java 工程师,想要从 0 到 1 掌握 AI 应用开发,我推荐这样一个路线:
更多推荐
 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)