
最新RAG技术架构演进路线图拆解
RAG技术演进与应用趋势(2025年) 摘要:RAG技术已成为大模型应用的核心支撑,从NaiveRAG到AgenticRAG经历了三代架构升级。NaiveRAG通过文档分块解决知识不足问题;GraphRAG引入知识图谱解决上下文断层;AgenticRAG实现动态知识获取,支持多智能体协作。2025年RAG呈现三大趋势:元学习能力增强、模块化架构普及、混合检索技术成熟。企业应用建议根据业务复杂度选择
目录
- 前言
- RAG技术基础
- 纵向演进:RAG代际的升级之路
- 横向迭代:每条赛道的细节优化
- 4.1 Naive RAG的迭代演化
- 4.2 Graph RAG的架构调整
- 4.3 Agentic RAG的扩张设计
- 2025年RAG技术新趋势
- 企业级应用建议
前言
检索增强生成(Retrieval-Augmented Generation,RAG)技术已经成为当今大模型应用的核心支撑。从2023年的概念验证到2025年的广泛落地,RAG正经历从单一方案到多元架构、从固定流程到动态优化的深刻变革。根据最新数据显示,2025年企业采用RAG技术的比例已达到75%,这充分说明RAG已从技术探索走向行业落地,成为连接大模型与实际业务需求的重要桥梁。
本文将从大模型算法工程师的角度,系统阐述RAG架构的演进路径,通过纵向和横向两个维度,深入解析为什么这些架构升级是必要的,以及它们如何解决不同场景下的实际问题。
RAG技术基础
在深入了解RAG的架构演进之前,我们需要理解RAG技术的核心价值。大型语言模型虽然在通用推理和语言理解上表现卓越,但在实际应用中仍然面临明显的局限性。第一个问题是知识局限性:模型的知识来自训练数据的截断点,无法获取实时更新的信息。第二个问题是领域适应性差:在企业特定领域或专业知识上,模型往往缺乏足够的训练样本。第三个问题是幻觉生成:当模型遇到知识盲点时,可能生成虚假信息而非承认不知道。第四个问题是可追溯性缺失:模型的回答过程不透明,难以验证信息来源。
RAG技术通过整合外部知识库,为大模型提供了一个有力的补充方案。其核心思想是在生成答案前,先从外部知识库检索相关信息,将这些信息与用户查询结合,形成丰富的上下文,最后指导大模型生成更加准确、可信的回答。这样不仅提高了知识密集型任务的处理能力,还允许知识库的持续更新和特定领域信息的整合。
纵向演进:RAG代际的升级之路
RAG技术的纵向演进反映了工程师们在解决更复杂问题时的思维升级。每一代架构都建立在前一代的基础上,解决其核心痛点,推动整个领域向前发展。
3.1 Naive RAG:解决知识不足的第一步
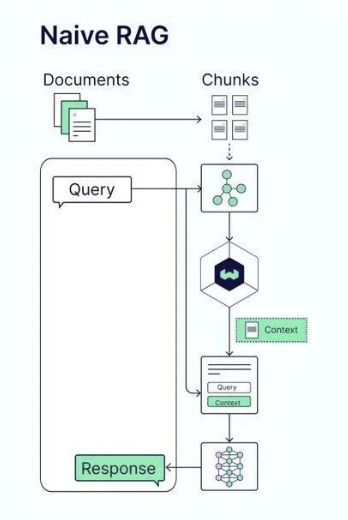
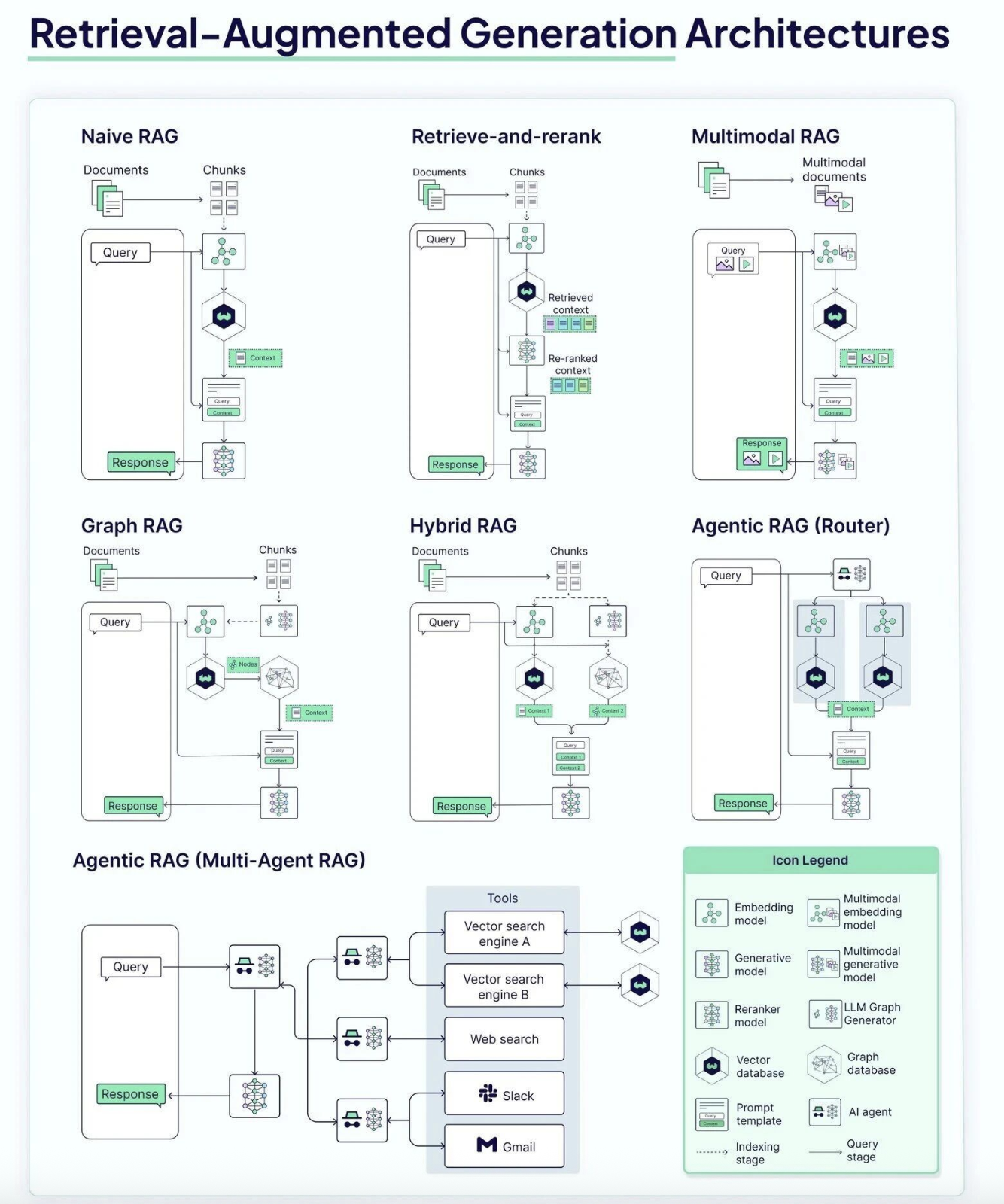
Naive RAG是RAG技术最初的形态,其架构设计相对简洁直接,但解决了当时最紧迫的问题。
在Naive RAG中,整个流程分为三个关键阶段。
首先是文档分割阶段:将原始文档切分成较小的块(chunk),便于存储和检索。
其次是查询处理阶段:用户输入查询后,系统直接将查询转化为嵌入向量。
最后是生成阶段:使用检索到的块作为上下文,直接送入大模型生成答案。
Naive RAG的核心价值在于三个方面。
第一,它解决了大模型自身知识库不足的问题,使模型能够基于外部知识进行回答。
第二,它一定程度上缓解了大模型的幻觉问题,因为模型的答案有具体的知识源支撑。
第三,它推进了大模型在企业环境中的应用,使企业能够快速构建基于自有数据的智能问答系统。
然而,Naive RAG也暴露了一些问题。当文档被简单切分成块后,相关信息可能被分散到不同的块中,导致上下文断层。此外,当处理需要全局理解的复杂查询时,单纯的局部检索往往不足以提供完整的答案。这些局限性为后续架构的升级指明了方向。
3.2 Graph RAG:打破知识分割的壁垒
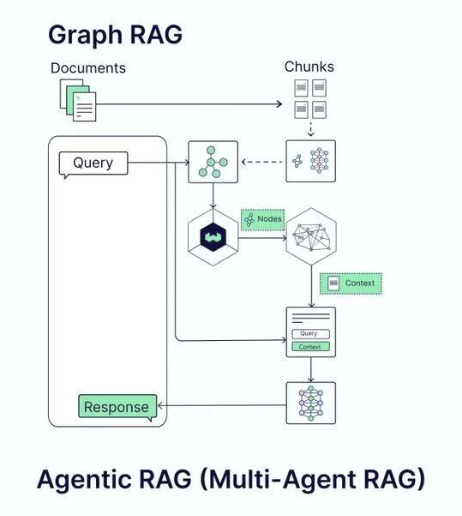
Graph RAG的出现正是为了解决Naive RAG中存在的上下文断层和全局上下文缺失问题。这是一个从平面检索到结构化知识组织的重要升级。
Graph RAG的核心创新在于引入了图结构来表示知识。与其说Graph RAG是一种检索方式,不如说它是一种知识组织的方式。
在这种架构中,文档中的实体(Entity)被识别出来,实体之间的关系被抽取并构建成知识图谱。查询时,系统不仅能够找到相关的文本块,还能够通过图的连接关系发现相关的背景知识。
具体来说,Graph RAG解决了两类关键问题。
第一个问题是知识分割导致的上下文断层。在Naive RAG中,一个完整的概念可能被分割在多个块中。而在Graph RAG中,这些块之间的语义关系被显式表示为图中的边,检索时可以追溯这些连接,获得更完整的上下文。
第二个问题是全局上下文缺失。当用户提出需要综合多个方面知识的复杂问题时,Graph RAG通过图遍历算法可以自动收集相关的多个实体和关系,形成整体的认识。
Graph RAG还支持多个维度的检索策略。可以进行实体级检索,找到与查询相关的关键实体。也可以进行关系级检索,发现实体之间的因果或包含关系。甚至可以进行路径级检索,找到连接两个概念的关键知识路径。这些灵活的检索方式使得Graph RAG能够处理更复杂的知识需求。
3.3 Agentic RAG:知识获取方式的根本革新
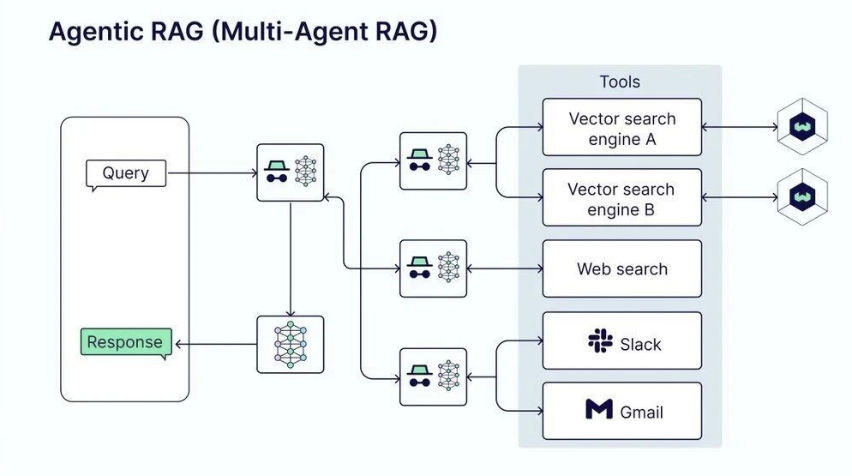
如果说Graph RAG是知识组织方式的升级,那么Agentic RAG则是知识获取方式的根本革新。这是RAG发展历程中最重要的转折点。
在Agentic RAG之前的架构中,RAG系统通常遵循一个固定的流程:接收查询,执行检索,生成答案。系统的行为是预定义的,缺乏根据具体情况动态调整的能力。而Agentic RAG打破了这种固定范式,将检索从一个被动的流程步骤转变为大模型主动选择的工具。
Agentic RAG的架构分为两类核心模式。
第一类是路由型架构(Router模式),这是一个相对简洁的设计。在这种模式中,大模型根据查询内容动态选择使用哪一个检索工具。比如用户问"今天天气如何",系统可能选择调用天气查询工具;如果问"公司第三季度的财务数据",系统则选择调用内部知识库。这种设计通过解耦大模型和知识库,实现了知识源的灵活组织。
第二类是多智能体架构(Multi-Agent RAG),这是一个更复杂但更强大的设计。在这种模式中,不同的Agent各司其职,有些负责从特定数据源检索信息,有些负责进行信息整合和推理,有些负责结果验证。多个Agent之间通过统一的工具调用接口进行协作。一个复杂查询可能会触发多个Agent的协同工作,形成一个完整的处理流程。
Agentic RAG的核心升级有三个维度。
第一个是解耦,大模型和知识库不再紧密耦合,而是通过工具接口进行松散连接,这使得知识库可以独立演进和扩展。
第二个是动态性,系统可以根据查询内容和中间结果实时调整策略,而不是执行预定义的流程。
第三个是可扩张性,新的数据源和工具可以以插件的方式轻松集成到系统中,无需修改核心的Agent逻辑。
横向迭代:每条赛道的细节优化
在纵向进化的同时,每条RAG架构的赛道内部也在进行持续的优化和迭代。这些横向的改进虽然不如纵向升级那么具有颠覆性,但同样重要,因为它们解决的是在实际应用中频繁遇到的具体问题。
4.1 Naive RAG的迭代演化
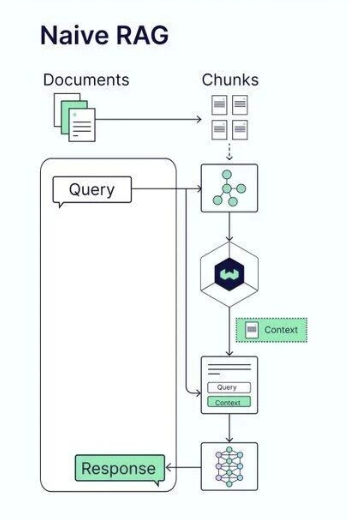
虽然Naive RAG相对简洁,但它的生命周期中仍然进行了两个重要的迭代。
第一个迭代是在检索阶段引入重排(Rerank)。在原始的Naive RAG中,检索通常基于向量相似度,返回top-k的相似文本块。
但这种方法存在一个问题:相似度高的文本块不一定是最相关的。重排机制的引入改善了这一点。系统先通过向量检索快速筛选出候选集合,然后使用一个更精细的重排模型(通常是一个专门训练的小模型或基于交叉注意力的模型)来重新排序这些候选,优化最终的检索结果。这个改进虽然增加了计算成本,但显著提高了检索精度,特别是在复杂查询场景下。
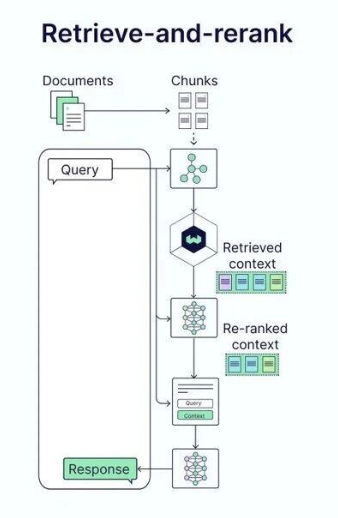
第二个迭代是对多模态信息的支持。现实中的知识库不仅包含文本,还包含图片、表格、图表等多种形式的信息。Naive RAG的扩展版本开始支持多模态嵌入模型,可以将文本和图片转换到同一个向量空间中。这样当用户查询时,系统不仅能够检索文本块,还能检索相关的图片和表格,为大模型提供更丰富的上下文。这对于处理包含大量可视化信息的领域(如医学影像、工程图纸等)特别有用。
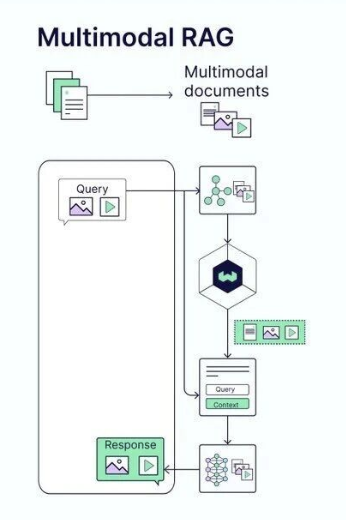
4.2 Graph RAG的架构调整
Graph RAG的内部迭代主要围绕知识图谱的组织和检索方式进行,主要体现在两种不同的架构方案上。
第一种是混合架构(Hybrid Architecture),这种方案兼容传统的向量检索。在混合架构中,系统同时维护向量数据库和图数据库两套数据结构。对于某些查询可能更适合向量检索,而对于另一些查询则更适合图遍历。混合架构允许系统根据查询特征智能地选择使用哪种检索方式。这种设计的优点是保持了系统的灵活性,同时充分利用了两种检索方式的优势。缺点是系统复杂度提高了,需要维护两套数据结构和对应的更新流程。
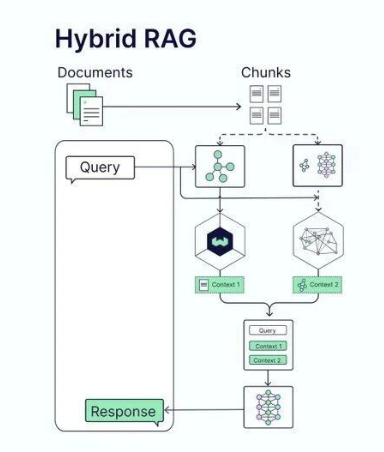
第二种是路由架构(Router Architecture),这是一个更进化的设计。在路由架构中,有一个"路由器"组件负责决定对于每一个查询,应该使用哪种检索方式和哪个数据源。路由器可以是一个简单的规则引擎,也可以是一个轻量级的机器学习模型。这种架构的优势在于它能够自动学习哪种策略对于哪类查询最有效,从而逐步优化系统性能。例如,系统可能学会对于实体关系查询使用图检索,对于相似度查询使用向量检索。
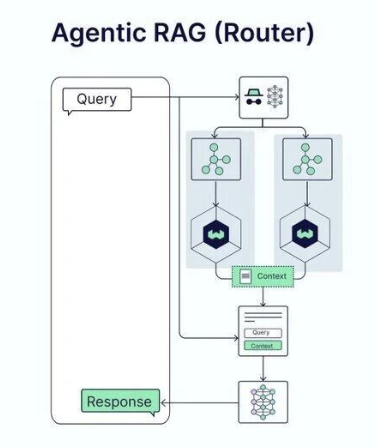
4.3 Agentic RAG的扩张设计
Agentic RAG作为最新的架构范式,其核心特点就是可扩张性。不同的实现方式展现了这种可扩张性的多个维度。
在工具层面的扩张,系统可以集成各种不同类型的检索工具和数据源。这些工具可以包括向量搜索引擎(用于文本和多模态内容检索),关键词搜索引擎(用于精确匹配和全文搜索),图数据库查询(用于知识图谱推理),以及专业的第三方服务(如Web搜索、API调用等)。每个工具都是一个独立的模块,通过统一的接口与Agent交互。
在Agent层面的扩张,系统可以拥有多个不同的Agent,每个Agent具有特定的职能。例如,可能有一个检索Agent专门负责查询数据库,一个推理Agent负责复杂的逻辑推理,一个验证Agent负责检查答案的准确性,一个总调度Agent负责协调整个流程。这些Agent通过异步通信进行协作,形成一个灵活的处理流程。
在数据源层面的扩张,系统可以连接到企业内部的各种系统。可以是结构化的数据库(SQL数据库、NoSQL数据库),也可以是非结构化的数据存储(文档库、日志库),甚至可以是实时的信息流。新的数据源可以动态添加,而无需修改Agent的核心逻辑。
2025年RAG技术新趋势
进入2025年,RAG技术的发展呈现出几个明显的新方向,这些趋势反映了产业的新需求和技术的新可能性。
元学习与自适应优化
2025年RAG的一个显著特征是其日益增强的"元学习"能力,即RAG系统展现出更强的自我意识和自我优化特性。最初的RAG系统采用固定的流水线作业方式,而现在的系统开始能够评估自身的中间步骤(比如评估检索质量是否足够)并相应调整策略。
这催生了诸如Self-RAG和Adaptive RAG等新技术。Self-RAG使系统能够判断何时需要进行额外的检索,何时可以直接生成答案。Adaptive RAG则通过动态调整查询处理策略来应对不同的任务难度。这些系统通过强化学习来优化检索策略,使用动态奖励函数来评估中间步骤的质量,从而逐步改进整体性能。
这种发展意味着未来的RAG系统可能因其更强的自我适应能力,而减少对特定数据集或任务的手动调优需求。
模块化与灵活架构
RAG从最初的单一架构发展到现在的多元范式,还进一步演化为更加模块化的设计。现代的Modular RAG架构通过引入LLM的"反思"能力,支持动态调用检索工具或递归优化输出,形成类似Agent的交互模式。
这种模块化设计允许用户根据特定的任务需求灵活组合不同的组件。对于简单的问答任务,可能只需要基础的检索模块。对于复杂的多步骤任务,则可以组合多个模块形成一个完整的工作流。这种灵活性显著提升了RAG系统在复杂场景中的适应性。
混合检索技术的普及
虽然向量检索在RAG中占据核心地位,但单纯的向量检索在某些场景下存在不足。传统的向量检索擅长语义相似度匹配,但在精确匹配方面可能不如基于关键词的方法。因此,混合检索技术(将向量检索与BM25关键词搜索相结合)成为了2025年的主流做法。
许多RAG框架(如RAGFlow等)通过混合搜索策略来提升召回率。部分向量数据库(如Qdrant)甚至推出了改进版BM42算法来优化关键词搜索。这种融合方法在实际应用中表现出色,特别是在处理需要精确匹配和语义理解相结合的查询时。
实时性和动态性的提升
2025年的RAG系统越来越强调实时性。系统能够快速集成新的数据,支持实时的知识库更新。这对于需要处理快速变化信息的应用场景(如新闻、金融市场、技术动态等)特别重要。
此外,系统的动态性也在提升。系统不再是被动地等待查询,而是能够主动推理和规划。Agent能够进行多轮的思考和检索,根据中间结果动态调整查询策略,甚至可以进行假设推理。
企业级应用建议
对于企业在2025年应用RAG技术时,以下建议可能有帮助。
根据业务复杂度选择架构
对于知识查询相对简单、主要处理问答任务的企业,Naive RAG配合重排和多模态支持可能已经足够。这类系统相对简单易维护,成本较低。
对于需要处理企业内部复杂知识关系的场景,比如需要理解产品之间的依赖关系、流程之间的因果关系等,Graph RAG会是一个更合适的选择。这需要在前期投入更多的知识抽取和图构建工作。
对于需要集成多个异构数据源、或需要支持复杂多步骤推理的企业级应用,Agentic RAG提供了最灵活的解决方案。虽然系统复杂度更高,但带来的收益也最大。
重视数据质量和知识组织
无论选择哪种架构,数据质量都是RAG系统成功的基石。企业应该投入足够的资源进行数据清洗、去重、标准化,并建立完善的数据治理流程。对于Graph RAG,还需要建立有效的实体识别和关系抽取流程。
建立持续优化机制
RAG系统一旦上线,并不意味着工作完成。企业应该建立监控和评估机制,定期检查系统的检索精度、生成质量等指标。对于表现不达预期的查询,应该进行深入分析,判断是检索质量问题还是生成质量问题,然后有针对性地优化。
谨慎处理多模态内容
如果业务中包含较多的多模态内容,应该选择支持多模态嵌入的系统。但要注意,多模态模型的性能仍在不断进步,企业应该定期评估最新的多模态模型是否能够改进系统性能。
规划Agent扩展
如果选择Agentic RAG架构,应该从一个相对简单的初始版本开始,然后逐步增加Agent和工具。这样可以更容易地识别和解决问题,避免过度设计导致的复杂性。
总结
RAG技术从Naive RAG到Graph RAG再到Agentic RAG的演进,体现了工程师们对于"如何更好地整合外部知识和大模型"这个问题的不断思考。每一次架构升级都不是为了追求技术的新奇,而是为了解决实际应用中遇到的具体问题。
在2025年及其后的时间里,RAG不会消亡,反而会以更新的范式获得更广泛、更深入的应用。无论是自适应优化的Self-RAG,还是多智能体协同的Agent架构,都在将RAG从一个辅助工具演变为企业AI系统的核心基础设施。
作为大模型算法工程师,我们需要根据具体的业务需求选择合适的RAG架构,建立完善的数据治理和优化机制,并持续跟踪最新的技术发展。只有这样,才能真正发挥RAG在连接大模型和现实业务之间的桥梁作用,推动企业AI应用向更深、更广的方向发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)