
快马助力豆包AI本地化部署:安全高效的企业级解决方案
对于需要兼顾安全与效率的企业AI项目,这种从开发到部署的全流程支持确实能节省大量时间。特别是平台生成的部署脚本已经包含了常见的性能调优参数,新手也能快速搭建出稳定可用的生产环境。在企业级AI应用场景中,数据隐私和安全性是重中之重。最近我在探索豆包AI模型的本地化部署方案时,发现。:输入"生成豆包AI本地部署Dockerfile"就能获得优化配置模板。:完成开发后直接发布到自有服务器,省去手动配置N
·
快速体验
- 打开 InsCode(快马)平台 https://www.inscode.net
- 输入框内输入如下内容:
创建一个基于豆包AI模型的本地化部署应用,支持在私有服务器或云环境中运行。应用核心功能包括:1. 提供本地化API接口,供企业内部系统调用;2. 支持敏感数据的本地处理,确保数据不离开私有环境;3. 集成快马平台的智能代码生成功能,自动生成部署脚本和配置文件;4. 提供实时监控和日志功能,便于运维管理。应用需兼容主流操作系统(如Linux、Windows),并支持一键部署。 - 点击'项目生成'按钮,等待项目生成完整后预览效果

在企业级AI应用场景中,数据隐私和安全性是重中之重。最近我在探索豆包AI模型的本地化部署方案时,发现InsCode(快马)平台能大幅简化这个复杂过程,今天就来分享具体实现思路和关键要点。
为什么需要本地化部署?
- 数据安全需求:金融、医疗等行业对敏感数据的处理有严格合规要求,本地化部署确保数据全程在私有环境流转
- 性能优化:绕过公网传输延迟,特别适合需要实时响应的业务场景
- 定制化开发:可根据企业具体需求调整模型参数和接口规范

实现方案核心架构
- 基础设施层:选择企业现有服务器或私有云环境,建议Linux系统(如Ubuntu 20.04+)以获得最佳兼容性
- 模型部署层:通过容器化技术封装豆包AI模型及依赖环境,解决不同系统的适配问题
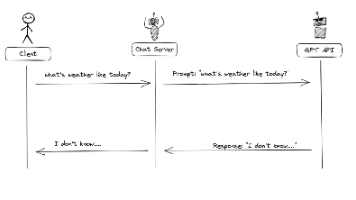
- 服务接口层:提供RESTful API供内部系统调用,设计时需考虑认证鉴权机制
- 运维监控层:集成Prometheus+Grafana实现资源监控,日志系统建议采用ELK栈
关键实施步骤
- 环境准备:在目标服务器安装Docker和Python3.8+运行环境,配置基础网络策略
- 模型配置:通过快马平台的AI对话功能生成适配本地硬件的模型优化参数
- 接口开发:使用平台智能生成的Flask/Django框架代码快速搭建API服务
- 安全加固:配置HTTPS证书、IP白名单和JWT令牌验证三重防护机制
- 压力测试:使用Locust工具模拟高并发请求,优化线程池和缓存策略
部署优化技巧
- 资源分配:根据模型计算需求动态调整容器CPU/内存限制
- 版本管理:建立完善的镜像版本回滚机制
- 冷启动优化:预加载常用模型参数到内存减少首次响应延迟
- 灾备方案:配置多节点集群和自动故障转移

实际应用案例
某保险公司在客户理赔自动化系统中采用该方案后: - 敏感病历数据实现100%本地处理 - API平均响应时间从云端方案的800ms降至120ms - 运维成本降低60%得益于平台生成的标准化部署脚本
平台使用体验
在InsCode(快马)平台实际操作时,这些功能特别实用: - 智能代码生成:输入"生成豆包AI本地部署Dockerfile"就能获得优化配置模板 - 一键部署:完成开发后直接发布到自有服务器,省去手动配置Nginx的麻烦 - 实时诊断:部署后自动生成的监控看板能直观查看CPU/内存占用
对于需要兼顾安全与效率的企业AI项目,这种从开发到部署的全流程支持确实能节省大量时间。特别是平台生成的部署脚本已经包含了常见的性能调优参数,新手也能快速搭建出稳定可用的生产环境。
快速体验
- 打开 InsCode(快马)平台 https://www.inscode.net
- 输入框内输入如下内容:
创建一个基于豆包AI模型的本地化部署应用,支持在私有服务器或云环境中运行。应用核心功能包括:1. 提供本地化API接口,供企业内部系统调用;2. 支持敏感数据的本地处理,确保数据不离开私有环境;3. 集成快马平台的智能代码生成功能,自动生成部署脚本和配置文件;4. 提供实时监控和日志功能,便于运维管理。应用需兼容主流操作系统(如Linux、Windows),并支持一键部署。 - 点击'项目生成'按钮,等待项目生成完整后预览效果
更多推荐
 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)