
论文导读 | 人工智能浪潮下的数据系统该如何应对变化?
时至今日,随着突飞猛进的人工智能相关技术在智能助手、自然科学研究和音视频生成等领域得到应用,我们正见证着一次人工智能技术的浪潮。作为数据库领域的研究者,我们不禁要思考,AI应用给数据系统提出了什么样的要求?数据系统的设计和开发者应该作出哪些改变来适应这些要求?本文从AI应用的数据管理需求和数据系统可能的发展方向出发,总结近期论文中提出的观点,尝试回答上述两个问题。
时至今日,随着突飞猛进的人工智能相关技术在智能助手、自然科学研究和音视频生成等领域得到应用,我们正见证着一次人工智能技术的浪潮。作为数据库领域的研究者,我们不禁要思考,AI应用给数据系统提出了什么样的要求?数据系统的设计和开发者应该作出哪些改变来适应这些要求?本文从AI应用的数据管理需求和数据系统可能的发展方向出发,总结近期论文中提出的观点,尝试回答上述两个问题。
AI应用中的数据存储
从存储数据的用途上划分,AI应用中需要数据系统进行管理的数据包括四类:训练数据、模型数据、RAG数据以及推理数据。而在管理这些数据的过程中,数据系统需要关注的技术点又包括数据的格式、分布和组织形式三个方面。本章节将从三个方面一一说明针对四类数据现有的解决方案。其中,训练数据、模型数据和RAG数据对数据系统的依赖程度相对更高,因此是本文叙述的主要关注点。
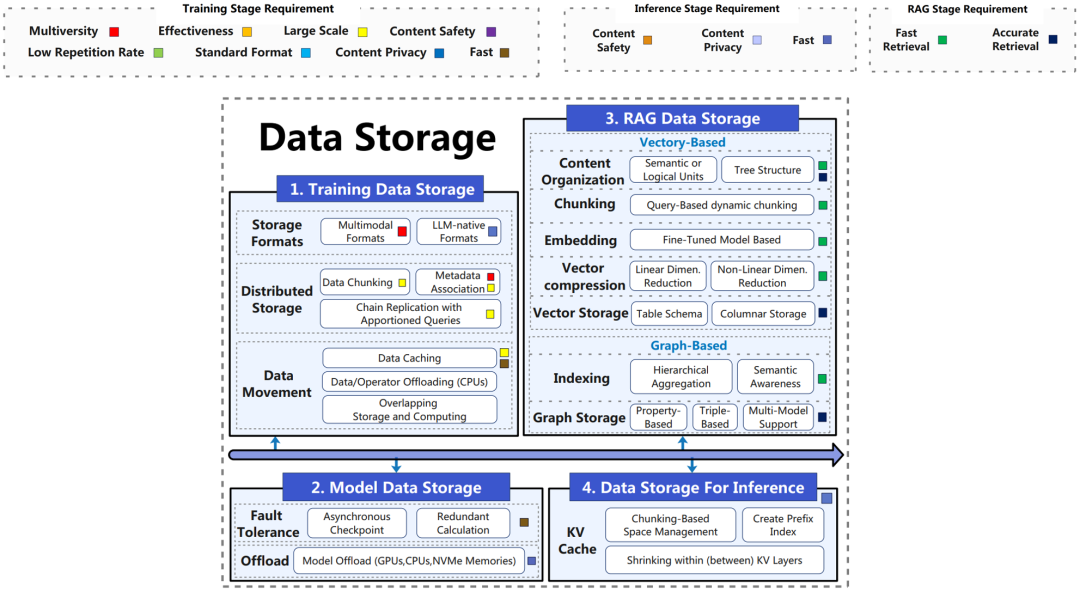
数据格式方面的关注点主要是训练数据以及模型数据可能存储在格式各异的文件格式中,不同的文件格式需要整合。尤其是在LLM相关的系统中,多模态数据的管理需求使得能否采用高效的文件格式对系统性能也存在一定的影响。
以文本为例,原始训练数据通常按照纯文本格式如CSV,JSON,TXT等存储,这些原始格式通常缺少压缩等处理。部分成熟的深度学习框架如tensorflow中提供了TFRecord,它基于Protobuf对打包在tf.train.Example中的训练数据存储对象进行序列化和数据sharding。模型数据方面,几乎所有基于Python的机器学习框架都支持Python中用于数据持久化的Pickle格式。具体的深度学习框架也提供特有的模型数据格式,如pytorch中的.pt与.pth格式。还有部分工作从某些方面优化模型格式,例如Safetensors提高的了序列化过程中的安全性,ONNX格式提供跨框架的数据格式支持。
数据分布是指在LLM体量不断扩大的背景下,需要对各类数据进行分布式存储,并且不同的数据可能存放在不同异构存储单元中。
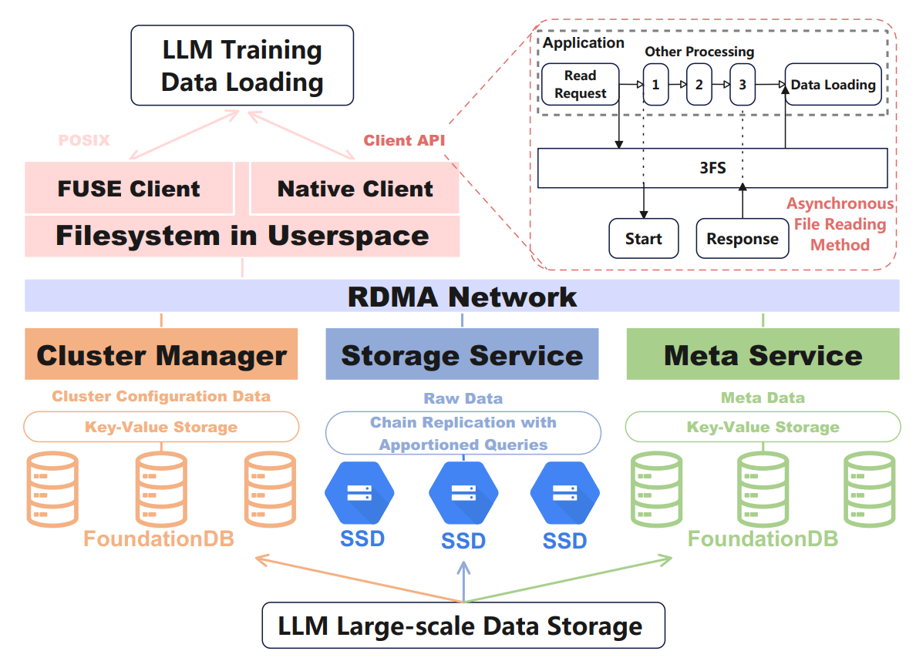
上图为DeepSeek采用的分布式数据存储3FS的示意图,本文以此为例说明AI应用中的数据分布式存储。3FS中部署了大量SSD结点,并使用链式复制和分配查询来保证数据一致性。3FS 中存储的文件被拆分为默认 512K 大小相等的块,块连成链,并在多个 SSD 上进行复制。读请求可以被分发到任意一个块。出问题的时候,不是overwrite而是把这个chunk移动到链的最后,当恢复正常后再将其他copy里的内容复制回来。读取可以在链中的任何节点上进行。每个节点都保留一份相同的数据副本。如果脏节点收到读取请求,则该节点会联系尾节点以检查其状态。作为回报,尾节点会发回其状态,这有助于保持强一致性,因为读取操作相对于尾节点是序列化的。由此可见,3FS的一个设计原则是牺牲一部分写性能换读性能(对LLM读比写重要一点)。3FS发现文件缓存会大量消耗主存带宽,所以引入了异步的数据读取方法。禁用文件缓存,直接读(也得益于高速的RDMA互联和SSD),还做了很多内存对齐的优化
除此之外,系统还需要决策什么样的数据存储在什么样的存储单元中。模型数据中的状态数据主要是分布在GPU显存中,同时前向过程中的feature map并不会立即用到,所以有的系统会将这些数据缓存在CPU主存中,并用Tiling等常见优化技术优化其处理逻辑。
RAG系统引入外部知识来优化模型输出,这部分外部知识同样需要在保证检索准确度的前提下尽可能提高效率,避免在数据量或并发查询量巨大时成为系统瓶颈。
RAG系统中存在大量的向量检索需求。原始数据通过嵌入模型转换为向量形式时,可能需要对原始数据的内容进行一些调整以优化向量映射的质量。例如,将文本数据切分成相互独立的语义单元,或者将文档转换成带有特定结构和连接关系提示的逻辑结构。同时,由于目前基于LLM的RAG系统经常需要处理长文本,所以对长文本进行切分(Chunking)也是常见的处理。这时,系统需要动态地确定文本切分的策略和粒度(句子、段落、章节等)。得到向量表示之后,需要对向量进行压缩,其中一类方法是用PCA等方法做降维,对于不符合分布的情况,有的工作会把优化目标换成最小化查询向量和error的内积的方法,去找一个投影子空间来做降维。为了提高这个过程的效率,相关工作会优化相似性的定义方法和迭代计算的流程;另一类方法的主要思路是将向量切分成定长的子向量,随后基于k-means对每个子向量做量化。压缩后的向量数据本身的存储和索引也是学术界和工业界研究了多年的问题,存在倒排档、连续存储、基于近似图的存储等多种方法。
如何实现面向AI应用的数据系统?
在充分了解要支持AI应用所需要管理的数据类型后,本文通过介绍UCB的研究人员近期发表的《Supporting Our AI Overlords: Redesigning Data Systems to be Agent-First》一文,介绍目前学术界认为面对AI应用优化的数据系统应该如何设计。
这篇文章首先通过一组case study说明了针对AI应用重新审视数据系统的框架设计的意义。研究者们使用BIRD Text2SQL Benchmark比较了使用GPT-4o-mini以及Qwen2.5-Coder-7B两个模型根据自然语言输出SQL查询的能力。后端数据库采用DuckDB。
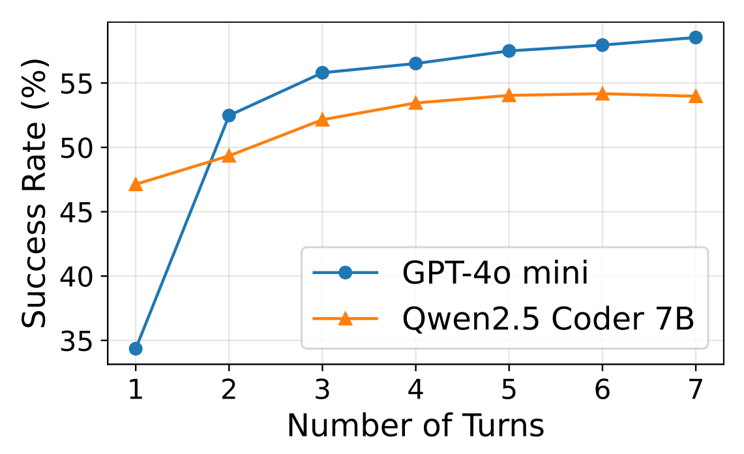
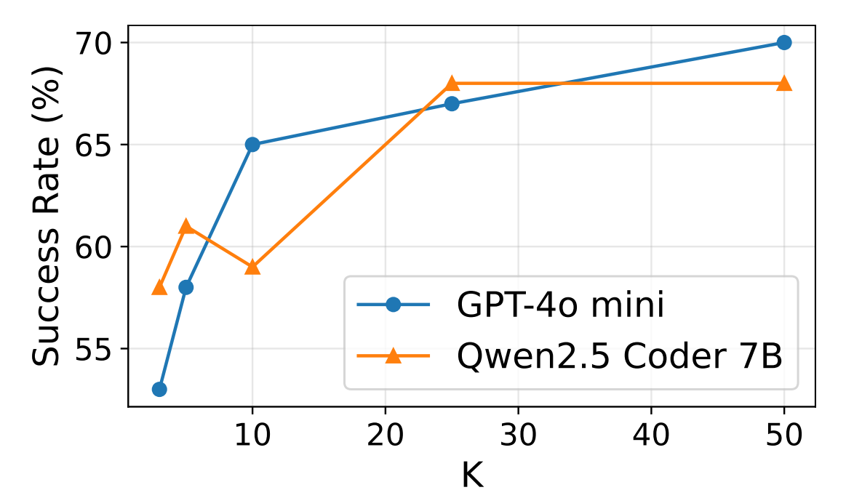
从上面两张统计图中对单agent和多agent情形的测试可以看出,单Agent随着尝试轮次的增加,任务成功率呈增长趋势,5轮后增长速度减弱;采用多个Agent并发执行任务,也能提升任务成功率,当并发数增加到50时,成功率可达70%左右。不管是单Agent多轮尝试,还是多Agent并发尝试,都会导致请求吞吐量呈倍级、甚至数十倍级的提升,从而对数据库的性能提出了更高的要求。
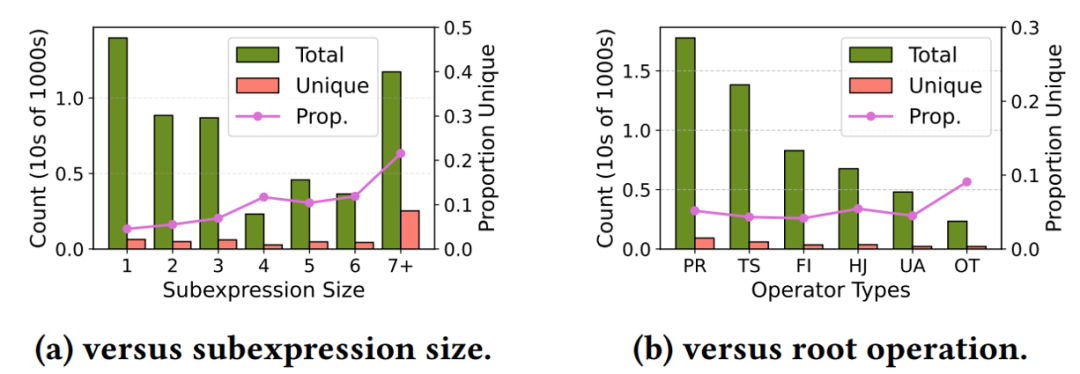
上图是另一组探究SQL查询的重复程度的实验。可以看到,在不同规模的执行计划下,unique 节点的占比不高于25%,按照节点(算子)类型归类,无重复节点(算子类型相同,算子中表达式不同)的占比不高于15%。这意味着,缓存或者记忆,将会是提升 Agent 访问数据库性能的潜力所在。
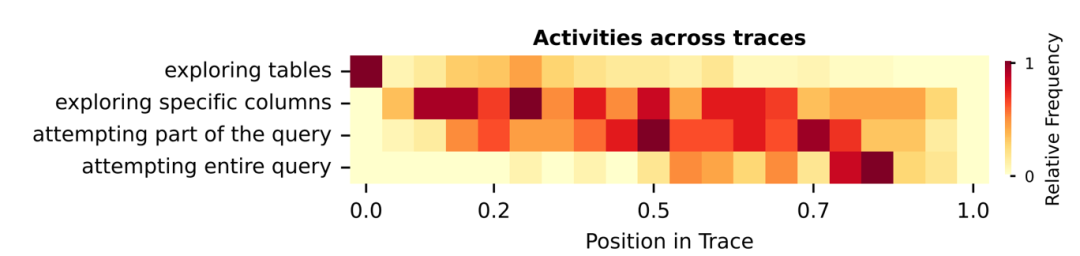
上图是一组探究Agent在生成数据查询时都向底层数据系统发起了哪些请求的实验,给 Agent 一个数据查询的任务,它并不会立刻生成结果查询 SQL,而是会先进行一些探索,包括查询数据库中都有哪些表和查询指定表中有哪些列,随后基于前面的信息,构建中间查询,开始尝试查询相关数据,迭代地根据子查询生成完整的 SQL,并执行查询,得到最终结果。可以看到,在任务执行的过程中,Agent大部分时间里都处于试错阶段,反复探索列和执行中间查询。
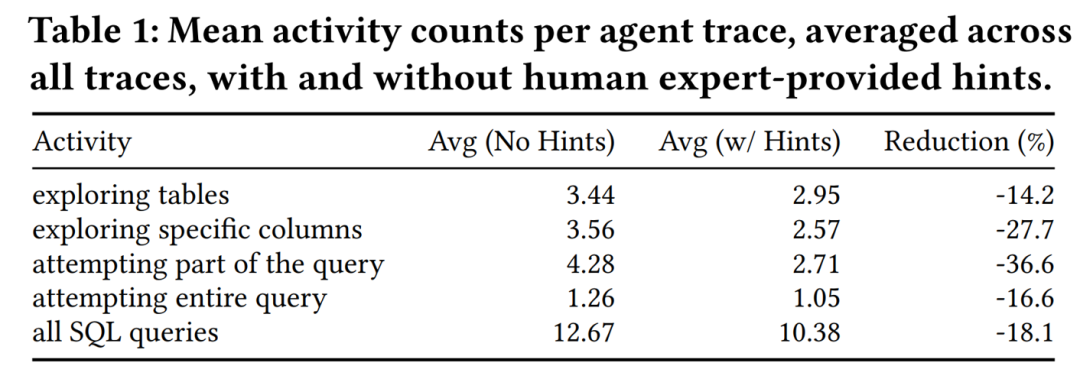
上表展示了在提供了合适的提示词之后,Agent完成数据查询任务需要的平均操作轮数。结果显示,适当的引导,可以降低18.1%的总SQL查询次数。
基于上述观察,论文作者认为,为人类设计的传统数据库需要从一个被动的查询执行者,转变为一个能够与 Agent 主动协作的伙伴。即下图所示的Agent-first的数据库架构,它主要包括查询方式、查询优化和索引三个方面的革新。
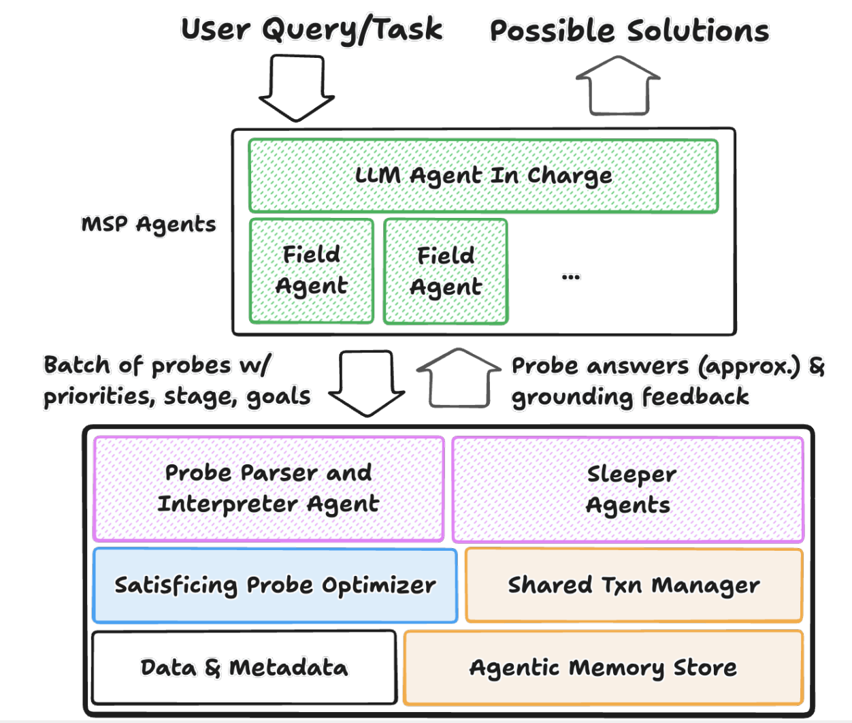
在查询方式方面,Agent与数据库的交互不再仅仅依靠SQL,而是依靠Probe。Probe 不仅包含了 SQL,还有附带一段由自然语言描述的背景信息,这主要起到引导作用,有助于减少反复试错。这些信息能够帮助系统明确查询的目标,动态调整在不同的探索阶段数据查询准确度,允许用户指定查询结果的可接受的近似程度和终止条件。用户甚至能够给数据库系统保留一定的“自我发挥”的空间。要支持这些要求,就需要在数据库端用库内 Agent 替代传统的SQL解析器,解析 Probe,随后提交给后端执行查询,并同时维护多个提供辅助信息和建议的辅助Sleeper Agent。
在查询优化方面,查询优化器现在需要考虑更多样的查询目标,以用最小的总时间代价,完成本批次以及未来批次的Probes查询任务,并且查询结果并不一定需要精确的。这需要系统具备基于增量信息做剪枝,避免做无用功的能力,对涌入的查询请求是否真正是查询需要的作出一定程度的判断,甚至可以提前准备好下一批次的查询结果,主动构造物化视图。
在索引方面,对传统数据库来说,业务流程往往是固定的。比如,应用知道哪些列会被经常查询,就可以预先为这些列建立索引,提升随机查询性能。但 Agent 的业务流程是动态的,查询类型是多样化的。它可以是对元数据的探索性查询、也可以是精确数据查询;可以是 TP 业务的点查,也可以是 AP 业务的批量扫描;可以是全文检索,也可以是向量检索。并且这些检索有大量重复。因此,构建新的记忆和索引是非常必要的。
参考文献
[1] Xuanhe Zhou, Junxuan He, Wei Zhou, Haodong Chen, Zirui Tang, Haoyu Zhao, Xin Tong, Guoliang Li, Youmin Chen, Jun Zhou, Zhaojun Sun, Binyuan Hui, Shuo Wang, Conghui He, Zhiyuan Liu, Jingren Zhou, Fan Wu: A Survey of LLM ⨉ DATA. CoRR abs/2505.18458 (2025)
[2] Shu Liu, Soujanya Ponnapalli, Shreya Shankar, Sepanta Zeighami, Alan Zhu, Shubham Agarwal, Ruiqi Chen, Samion Suwito, Shuo Yuan, Ion Stoica, Matei Zaharia, Alvin Cheung, Natacha Crooks, Joseph E. Gonzalez, Aditya G. Parameswaran: Supporting Our AI Overlords: Redesigning Data Systems to be Agent-First. CoRR abs/2509.00997 (2025)
[3] Jintao Zhang, Guoliang Li, Jinyang Su: SAGE: A Framework of Precise Retrieval for RAG. ICDE 2025: 1388-1401
[4] Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, Qing Li: A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models. KDD 2024: 6491-6501


欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
实验室开源产品图数据库gStore:
gStore官网:https://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)